

Aside from the massive parallelism available in modern FPGAs, there are other two other key reasons why reconfigurable hardware is finding a fit in neural network processing in both training and inference.
First is the energy efficiency of these devices relative to performance, and second is the flexibility of an architecture that can be recast to the framework at hand. In the past we’ve described how FPGAs can fit over GPUs as well as custom ASICs in some cases, and what the future might hold for novel architectures based on reconfigurable hardware for these workloads. But there is still a lot of work to do on the ease of use and programmability front to push these devices into the mainstream (having them delivered via AWS for testing and development is a start)—and more work still required to use all the available compute, memory, and bandwidth resources on a device.
Among the refinements that can make FPGAs better suited to convolutional nets in particular is building flexibility into the buffers to cut down on off-chip transfers—something that is important for running large-scale CNNs that use batching techniques to trim down data transfer. This might sound like a low-level problem from the outside, but batching is what makes CNNs at scale possible (without jamming up bandwidth relative to processing capabilities).
While batching makes logical sense, and so too does exploiting the parallelism and power efficiency of an FPGA, it is not so simple, explains Dr. Peter Milder of Stony Brook University. He and his team have developed an FPGA based architecture, called Escher, to tackle convolutional neural networks in a way that minimizes redundant data movement and maximizes the on-chip buffers and innate flexibility of an FPGA to bolster inference. This takes clever work, however, because batching isn’t as inherently efficient as it might seem.
“The big problem is that when you compute a large, modern CNN and are doing inference, you have to bring in a lot of weights—all these pre-trained parameters. They are often hundreds of megabytes each, so you can’t store them on chip—it has to be in off-chip DRAM,” Milder explains. “In image recognition, you have to bring that data in by reading 400-500 MB just to get the weights and answer, then move on to the next image and read those same hundreds of megabytes again, which is an obvious inefficiency.” This is where batching makes sense—instead of operating on just one image at a time, the cost of doing that can be amortized by bringing all that data into a batch across ten images, for example for a 10X cut in data movement. Sounds effective—so what’s the problem and where can FPGAs cut through?
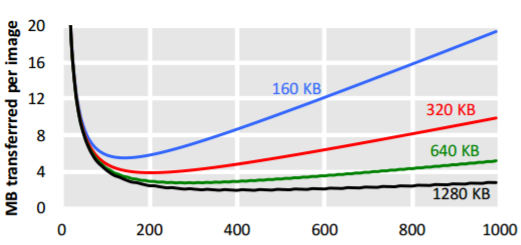
If there is limited on-chip storage—and on an FPGA there is a limited amount of block RAM or on an ASIC, a limited area for SRAM—as the batch sizes get bigger, the buffers to hold the inputs and outputs must be divided across the whole block. So, if there is a batch of ten images, the output buffer has 1/10 the space for each of the batch outputs. Diving the buffers among the batch means you have to transfer more data back and forth on chip for those inputs and outputs so that as the batch size gets bigger, the amount of data for weights is fine, but that intermediate data shuffle compounds quickly.
Milder says the goal is to create an architecture that is flexible enough for whatever layer users want to compute with. “What we did with Escher was to produce an accelerator for CNN layers that is flexible enough to work on fully connected and the convolutional layers themselves—and can have batching applied to all of them without the overhead.”
In this case it is possible to have the same amount of memory for input and output buffers and depending on settings adjustable at runtime, it is possible to use those for a batch size of just one, where the whole buffer is dedicated to just the results of that one image, or change those settings (the way it is addressing and some of the control logic so it can divide memory into groups for different batches) and run across larger batches more efficiently.
The team did their work on a mid-range Virtex 7 FPGA, but Milder says even with beefier FPGAs that add both compute and memory bandwidth, batching inefficiencies would continue to be a problem. His team is also working on finalizing results from another research endeavor related to refining FPGA training and making smaller, focused sets of FPGAs to handle different network models interchangeably. The full paper on Escher compares the performance on various benchmarks to another architecture we explored last year as well.
Milder’s own work has historically focused on making hardware design easier via optimization tools. “The interest in FPGAs now is staggering,” he tells The Next Platform. “Just a few years ago, there would only be a few people working on these problems and presenting at conferences, but now there are many sessions on topics like this.” He says that much of the momentum has been added by mainstream movements of FPGAs, including Microsoft’s Catapult designs and the addition of the F1 instances to Amazon Web Services offerings.
“People are seriously looking at FPGA deployments at scale now. The infrastructure is in place for a lot of work to keep scaling this up,” Milder says. “The raw parallelism with thousands of arithmetic units that can work in parallel, connected to relatively fast on-chip memory to feed them data means the potential for a lot of energy efficient compute at high performance values” for deep learning and other workload.

Chip Roadmaps Unfold, Crisscrossing And Interconnecting, At AMD
After its acquisitions of ATI in 2006 and the maturation of its discrete GPUs with the Instinct line from the past few years and the acquisitions of Xilinx and Pensando here in 2022, AMD is not just a second source of X86 processors. Now, without question, it is a formidable …
The Inevitability Of FPGAs In The Datacenter
You don’t have to be a chip designer to program an FPGA, just like you don’t have to be a C++ programmer to code in Java, but it probably helps in both cases if you want to do them well. The trick to commercializing both technologies – Java and FPGAs …
A Cornucopia Of Memory And Bandwidth In The Agilex-M FPGA
When it comes to memory for compute engines, FPGAs – or rather what we have started calling hybrid FPGAs because they have all kinds of hard coded logic as well as the FPGA programmable logic on a single package – have the broadest selection of memory types of any kind …
Even the deepest nets usually only have around 200MB of weight memory, and this can get around ~50% smaller by clever network design and/or pruning+quantization. I’m not a big fan of bringing in weight memory from DRAM, it’s simply far too expensive.
For example, separable convolutions (a la Quicknet and MobilNets) can provide a massive boost in parametric (and even computational!) efficiency while actually reaching higher efficiency!