
While the machine learning applications created by hyperscalers and the simulations and models run by HPC centers are very different animals, the kinds of hardware that help accelerate the performance for one is also helping to boost the other in many cases. And that means that the total addressable market for systems like the latest GPU-accelerated Power Systems machines or the alternatives from Nvidia and others has rapidly expanded as enterprises try to deploy both HPC and AI to better run their businesses.
HPC as we know it has obviously been around for a long time, and is in a major transition as companies try to push more work through their HPC systems or accelerate the jobs they are running. (It comes to the same, You can do more of the same simulations with different initial conditions or run a longer or finer-grained simulations as the iron gets more powerful.) Machine learning, particularly the neural networks that have been used to do image, video, and speech recognition and increasingly are the back-ends for recommendation engines, fraud detection, and risk analysis, is a much newer workload and one where the software stack is changing very fast, sometimes to the great frustration of hardware designers. But it is clearly arguable that AI, not traditional HPC, is pushing the boundaries on single-node performance and looking to leverage the decades of experience that has gone into parallel computing frameworks like the Message Passing Interface (MPI) that revolutionized cluster computing two decades ago, displacing federated RISC/Unix systems with their extended NUMA architectures with much cheaper X86 clusters running Linux.
It is reasonable to ponder how these two very different customer sets, with their two different hardware and software stacks, will come together. IBM and its OpenPower partners have had a plan for that, and it looks like it is coming together.
“We see AI and advanced analytics and databases are becoming the new workloads that are driving HPC infrastructure,” Sumit Gupta, vice president of high performance computing and analytics for IBM Systems group, tells The Next Platform. “The other way to think about this, of course, is that HPC technologies are making their way into the enterprise thanks to these advanced analytics workloads. The big trend has been on deep learning, and we have been focused on this for a while now and enterprises face a few challenges. Pretty much every enterprise has a mandate coming from senior management to go figure out artificial intelligence, deep learning, or machine learning. But this is still a very do-it-yourself world.”
This situation is akin to traditional HPC in the early days before commercial packages were widely adopted and as open source alternatives became available. GPU acceleration is taking off for simulation and modeling workloads as commercial application providers use CUDA to refactor their code to support GPU offload or to write whole new applications from scratch, and machine learning training frameworks that support GPU offload are changing fast and taking advantage of fat node computing that IBM and Nvidia together offer on Power Systems machines with Power8 CPUs and “Pascal” Tesla P100 GPU accelerators using NVLink interconnects to lash the two together. At the moment, machine learning applications, by their very nature, do not scale well across multiple nodes, but IBM has some ideas about how to fix that (as do a bunch of hyperscalers who pay very close attention to the HPC space.)
The evolution of applications on IBM’s modern Power platform is echoing the march of HPC history, but at a much accelerated pace than the original innovation took place.
“On Linux on Power, we started with solutions for HPC, in particular targeting both the research HPC markets and also the commercial HPC markets like financial services or the oil and gas industry,” Gupta explains. “Recently, we are seeing HPC type of workloads and associated systems and storage starting to penetrate the enterprise via high-speed databases and machine learning. In particular, we are working with companies that are building GPU-accelerated databases like Kinetica (formerly GPUdb), MapD, and BlazeGraph and companies doing deep learning like Minds.ai and Imagga. The solutions that these companies develop target a wide variety of enterprise markets, including retail, telcos, finance, and so forth.”
These workloads can have a common hardware platform, but customers need some help getting a commercial-grade, enterprise-ready deep stack.
Enter IBM’s PowerAI deep learning stack, which is being unveiled at the SC16 supercomputing conference in Salt Lake City this week. There is a plethora of AI, deep learning, and machine learning announcements coming out of what used to be a traditional HPC event. (There is no stopping this convergence, and we will be talking about this separately.) Almost all of the vendors are starting to just consider AI as another kind of HPC, along with data analytics and database acceleration. And for good reason. AI, in the very broadest sense, is a hot topic and simulation and modeling – what people used to generically call supercomputing but which we not call high performance computing – is not as hot even if it is vital to the design of products of all kinds, making our nuclear arsenals safe, or curing diseases.

PowerAI is a package of open source AI frameworks that have been traditionally written for X86 iron and Linux that have been ported to Power8 processors running Linux and tuned to take advantage of specific features on the Power Systems LC machines that put IBM back in to the HPC hardware business when they debuted this time last year and that have been substantially improved with the advent of a Power8 chip that includes the NVLink interconnect. The focus of IBM’s efforts in the HPC space with the updated Power Systems LC machines is the box code-named “Minsky,” which is made for Big Blue by ODM Wistron and which crams two Power8 chips with NVLink out to four Tesla P100 accelerators into a single 2U system that maxes out at 1 TB of main memory for the CPU complex – all for under $50,000. (We detailed the Minsky system here back in September.)
IBM is offering the PowerAI stack as a free software download, which stands to reason given that it is open source software, and Gupta says that Big Blue will eventually offer commercial support for PowerAI although pricing has not been set as yet. That is a means for the company to get back some of the investment IBM Research has done in tuning the frameworks and that other parts of IBM, such as the Spectrum MPI team, are doing to make AI workloads scale across multiple fat nodes in a manner similar to that which HPC simulations are doing on the Minksy system.
Saving time is one of the big reasons why IBM is packaging up the PowerAI stack. At a real-life customer trying to install open source machine learning frameworks on Power Systems machines, Gupta says that it took an onsite Linux expert two weeks to download and install frameworks and deal with all of the dependencies in the software stack. (This is a bit like trying to roll your own Linux kernel and base operating system.)

The other big reason to go with PowerAI running on the Minsky machine is performance. NVLink, as we discussed in detail the past, provides “tens of percent” improvement in performance for machine learning workloads all by itself, says Gupta, adding that the real benefit will come when the community solves the clustering problem for deep learning, getting a workflow that can scale across multiple nodes.
“This is the unsolved problem in deep learning today,” Gupta explains. “The mainstream Caffe framework is for single nodes, and it does not support MPI although there are some GitHub forks that sort of have it. Big hyperscale customers have been working on an MPI version of Caffe, and nearly every one of them has complained that OpenMPI does not work well with these frameworks and in fact many of them are evaluating Spectrum MPI right now because. TensorFlow, even though it is built for cluster scaling, it doesn’t scale very well to a large number of nodes. Then the performance benefit will be in the multiple Xs, not tens of percent.”

The initial release of PowerAI will have stock software from the popular frameworks shown above, but the IBM Caffe framework will have special optimizations to scale Caffe over multiple nodes. The desire is there to get this scaling to work because right now, even on a fat system with lots of GPU capacity for offload, it can take three or four days to do neural network training, even with a less complex model. The minute they have NVLink in the nodes, they can do more complex models because of the throughput improvement, and with cluster scaling of frameworks like Caffe and TensorFlow, they could be able to scale even further.
Right now, says Gupta, the predominant GPU being bought for machine learning training is the Tesla M40, which is based on the prior generation of “Maxwell” GPUs from Nvidia and which made their debut at last year’s SC15 supercomputing conference. While Nvidia announced the follow-on Pascal-based Tesla P40 accelerator in September, it is focusing these on machine learning inference (running the code of a trained algorithm) rather than for the actual training of the neural networks. The Pascal Tesla P100 is the premiere motor for neural network training, but they are hard to come by and IBM is one of the few vendors that can get its hands on a fairly large number of them. These use the SXM2 mounting method to snap the Pascals down onto the motherboard. As far as we can tell, the PCI-Express versions of the Tesla P100s (which do not support NVLink and which came out in September), are still not widely available.
Given that the Tesla M40 is the dominant accelerator for hyperscale machine learning, IBM compared two-socket Xeon machines using the M40s over PCI-Express links to a two-socket Power8 machine using NVLink to hook to four Tesla P100s using the SXM2 ports. Here is what it looks like:
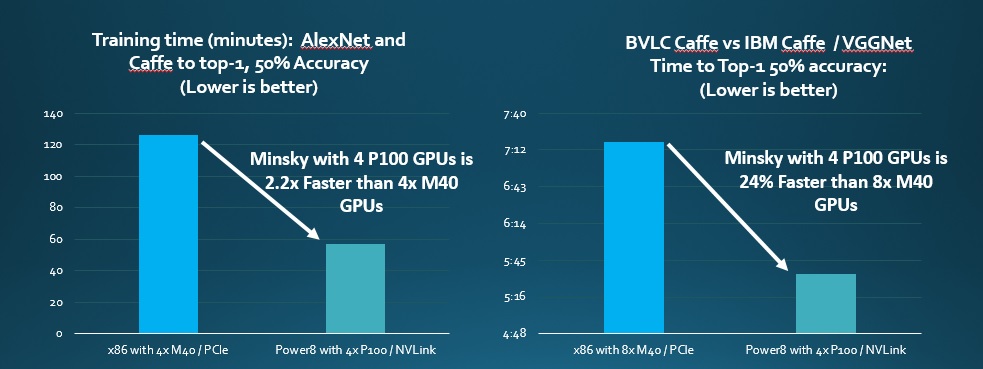
On the left hand side, IBM is comparing a machine using two ten-core “Broadwell” Xeon E5-2640 v4 processors running at 2.6 GHz with 512 GB of memory and four of the M40 accelerators running the AlexNet image recognition software and the Caffe framework. The Power8 machine has two ten-core processors running at 2.9 GHz (this is the merchant version of the chip, slower than the one IBM sells in its plain vanilla systems) with 512 GB of main memory and four of the P100 cards. The IBM machine is 2.2X faster at running the AlexNet neural network training algorithm. (But the 50 percent accuracy seems a bit low, if you ask us.) On the right hand side of this chart, IBM is comparing the BVLC variant of Caffe to its own IBM Caffe variant and the Xeon machine has eight M40 cards, hitting the practical maximum of the typical enterprise and hyperscale server. (We are aware that some machines are cramming in sixteen GPU accelerators. But that power density is not possible at a lot of enterprises.) In any event the Minsky server bests the Xeon plus M40 box by about 24 percent. What is missing here, of course, is any mention of the cost of the two machines. (We will be trying to hunt this down.) We suspect that the P100s cost twice as much as the M40s but do twice the work, for a big increase in space, power, and cooling savings.
Lest We Forget The HPC Side Of Minsky
The technical name of the Minsky server is the Power Systems LC for HPC, and that means it is intended for traditional HPC workloads. Moreover, Gupta confirms what we already expect: That enterprises will want to have one platform for GPU acceleration, whether it is for simulations, machine learning, database acceleration, or analytics.
To show off the capabilities of the Minsky machine, IBM trotted out some of its own benchmark tests:
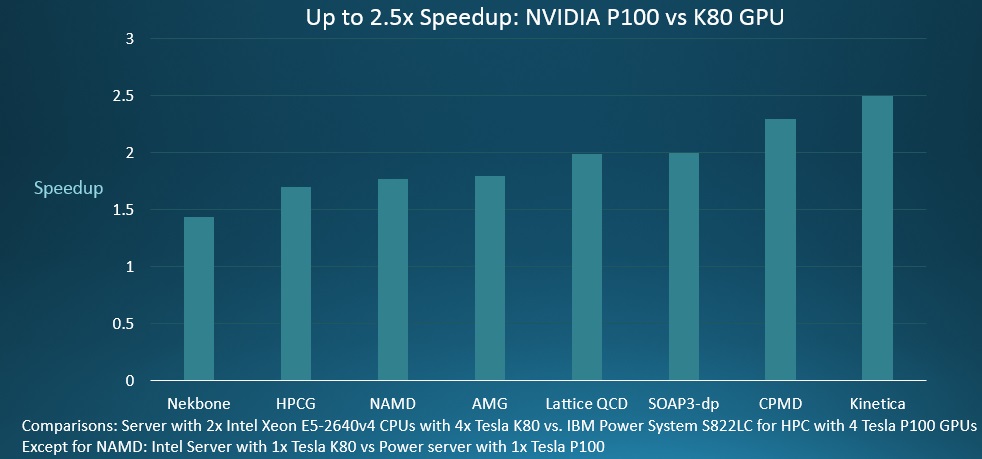
As you can see, depending on the workload, the performance gains range from around 50 percent to 150 percent. The above comparison uses four Tesla K80 dual-GPU accelerators from Nvidia on a two-socket Xeon server and pits that machine against a two-socket Power8 machine with four Tesla P100 SXM2 modules welded onto the motherboard. Gupta says that a system with two CPUs and four GPU accelerator cards is the sweet spot in the enterprise and HPC market right now, hence this comparison.
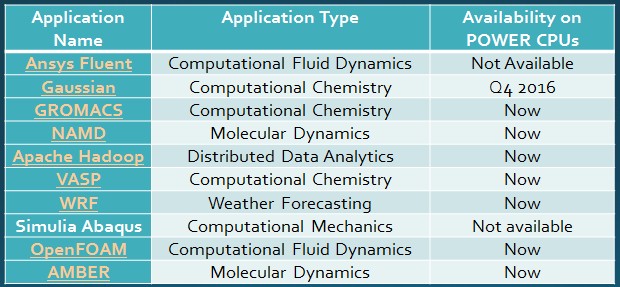
Perhaps as significant as the boost in performance that comes through the combination of the Power8 chip, NVLink, and the Tesla P100 SXM2s is the availability of HPC software to take advantage of it. Gupta says that there are hundreds of HPC applications now available on Power iron running Linux, and that eight of the top ten applications in the traditional HPC arena are running on Power with an important one, ANSYS Fluent, coming soon. It is a pity that more of the traditional HPC code is not open source, or else IBM might be able to put together a stack called PowerHPC and do the work itself. Presumably, those codes that have used CUDA to offload calculations from X86 processors to GPUs can be recompiled and work well with the Power-GPU combination without too much tuning.


Data Analytics Can Be The Next HPC For IBM Power
In the next few months, Big Blue will launch its entry and midrange Power10 servers, and to be blunt, we are not sure what the HPC and AI angle is going to be for these systems. This is peculiar and not consistent with the prior two decades of the history …

Making The Red Hat Platform Bet Pay Off For Big Blue
In the long run of the history of International Business Machines, a conglomerate established back in 1911 whose Electric Tabulating System was custom built by Herman Hollerith for the federal government in the United States for the 1890 census and then commercialized, the acquisition of Red Hat by Big Blue …

A GPU Upgrade For “Leonardo” Supercomputer But Not A Budget Upgrade
Neither scientific progress nor the budgetary process can wait for compute engine and interconnect roadmaps. At some point, an HPC center is at a cadence for upgrading its supercomputers that is difficult to change, and you get the best supercomputer you can get at any time and you try not …
wow! how much of the speed up.comes from.the nvlink or.from.the newer gpus? In.any case, this is impressive. IBM is finally taking the right approach and openPOWER will be a success if they follow this path. Once some hyperscale companies start buying POWER9 with volta gpus or other accelerators through CAPI 2.0…
Well the graph and the text do not match. The text says the Graph compares M40 on Intel to M40 on Power but the first part of the graph actually compares P100 to M40 and the right one 4 P100 to 8 M40 with two different builds. So I am not sure what this article is trying to say here
This is going to be an uphill battle for IBM, as the author pointed out these DeepLearning / ML packages are changing rapidly and they usually do not target the Power platform at all so will be a real uphill battle. Intel has it much easier as they just need to replace some key libraries and keep the rest in tact to get maximum performance out of their architectures. Where on Power you need to make sure everything and all its dependencies (which for some of these packages are many) have to keep working and with each update as well. The $50k price tag really doesn’t make it that attractive either considering I can buy a XeonPhi dev box for less than $5k at the moment.
are you comparing a box with a phi? #nonsense
IBM will need to do the same as Intel, i.e. optimize the libraried and frameworks to leverage the new HW features introduced on each generation. So, I do not think there is a diiference between the ‘hills’.
The fact that software changes quickly is a challenge for everybody. Actually, maybe IBM is in a better position by allowing their CPU to be tighly coupled to different type of accelerators via the novel buses introduced and standarized. That helps the flexibility.
Nope IBM needs to make sure all of them including all the dependent libraries work on Power architecture with each update for Torch, Theanos, Caffe + including all its interface languages LUA, Phyton and potential Matlab (does Matlab actually exist on Power at all?) and what not and there are lots. Caffe has quiet a bit of a dependency list if you ever tried to install and build it form scratch you would know.
Where for Intel all this code already works has been tested and runs on x86 so they do not need to do anything, they can just replace OpenBLAS with MKL which is a simple linking as it is fully BLAS interface compatible and potentially link a CuDNN replacement and they even added MPI support in their branch that’s all.
Now if you tell me that’s not a lot less overhead than I don’t know.
IBM + some people hang on to that pipe dream that the Power architecture suddenly will become relevant again. I would say ARM is more likely to succeed than Power as it has a user base that is about 1000 times larger.
have you seen PowerAI announcement? They ported all these frameworks to POWER.
+ Major distros support power now, so all new stuff is also deployed on POWER
+ DevOps + CI development philosophy reduces the headaches of testing on different platforms and architectures.
The choice of architecture is not going to be decided by if the software has support or has been ported… is going to be decided if performance/efficiency/cost (depending on your goal) is better. Look what SAP did when running HANA on POWER, impressive results.
I agree that userbase is important, but they are building it.
@OranjeeGeneral: $5k for a *devbox*, but that’s are not production KNL node. Factor in that for derplearning you’ll need several KNLs to match a single P100 (say 2-3x more, based on https://blogs.nvidia.com/blog/2016/08/16/correcting-some-mistakes). Also factor in that the PCI-E card version of KNL has not been released yet, so forget about dense systems, current KNL is one chip per (https://www-ssl.intel.com/content/www/us/en/processors/xeon/xeon-phi-detail.html). Considering these, you’ll quickly realize that you’ll need many, probably about a dozen KNL nodes to match the DL/ML performance of one of the Minsky systems assuming near perfect scaling (at least as good as over NVLink, so good luck with that), plus fabric and switch. Try to get that for $50k.
Well I think you are a not quiet informed.
Maybe you should read this first before continuing commenting
http://dap.xeonphi.com
I don’t see why you would need a PCI-Form factor at all (I don’t see any benefit in that) if you could have multi-socket system instead which would be far better and cheaper and bypasses the slow PCI-bus or the proprietary NVLink nonsense.
This IBM’s Power8 Tesla Hybrid is going to be a power hog (already known those IBM Power8 CPUs alone are going to draw up 220W just idling, example http://www.anandtech.com/show/10435/assessing-ibms-power8-part-1/11 “Put in practice, we measured 221W at idle on our S812LC, while a similarly equipped Xeon system idled at around 90-100W”), thus this means rich companies and institutions that can afford the gargantuan electric bills may look into it as an option (since its also very expensive).
Meanwhile similar x86 solutions using Tesla P100 are already available, example from SC16 at Supermicro booth https://www.youtube.com/watch?v=RFpcExgTHEk&t=5m36s and that includes the NVLink between the Tesla P100 modules. That one is probably a much more accessible choice for most people. Heck, even NVIDIA’s DGX-1 also uses Intel’s Xeons for high efficiency as shown here https://www.nextplatform.com/2016/11/14/nvidias-saturn-v-dgx-1-cluster-stacks/ Thus IBM has a huge mountain to climb (even thru OpenPower foundation efforts) just to get other server vendors interested in their Power8 based systems.