
The very first systems that allow for GPUs to be hooked directly to CPUs using Nvidia’s NVLink high-speed interconnect are coming to market now that Big Blue is updating its Power Systems LC line of Linux-based systems with the help of hardware partners in the OpenPower Foundation collective.
Interestingly, the advent of the Power Systems S822LC for HPC system, code-named “Minsky” inside of IBM because human beings like real names even if marketeers are not allowed to, gives the DGX-1 machine crafted by Nvidia for deep learning workloads some competition. Right now, these systems are the only two machines on the market that can get “Pascal” GP100 GPUs in the SMX2 form factor and sporting NVLink ports to provide high bandwidth links between the GPUs.
But the IBM Minsky machine is unique in an important way.
The DGX-1 machine from Nvidia, which we detailed here back in April when it was announced, uses NVLink ports to lash up to eight of the Tesla P100 SMX2 cards (which mount directly onto the system board) onto a motherboard with two “Haswell” Xeon E5 v3 processors from Intel; the GPUs link to the processor complex using regular PCI-Express links through a quad of PCI switches. (We detailed this setup in our detailed analysis of NVLink here.) The GPUs in the DGX-1 are cross-coupled with three links in a quad, which is attached by two PCI-Express switches; the NVLink ports provide 20 GB/sec of bandwidth per link. The system has two processors, each with four GPUs hanging off it, and four pairs of NVLink ports glue the pair of GPU complexes together. It looks like this:
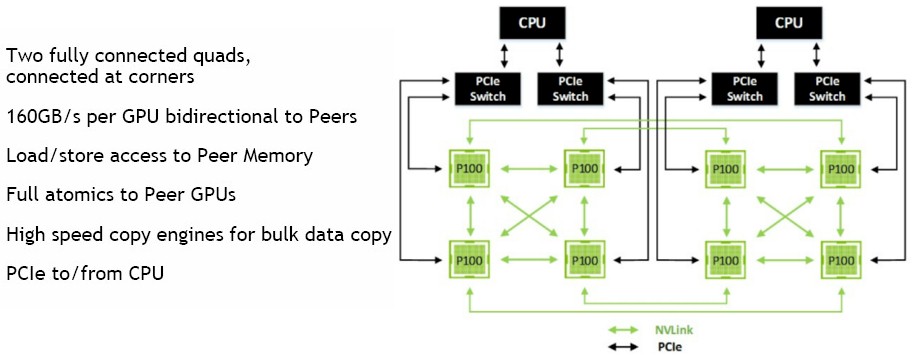
With the Minsky machine, IBM is using NVLink ports on the updated Power8 CPU, which was launched in April at the OpenPower Summit and is making its debut in the Minsky system, which is actually manufactured by ODM Wistron and rebadged, sold, and supported by IBM. The NVLink ports are bundled up in a quad to deliver 80 GB/sec of bandwidth between a pair of GPUs and between each GPU and the updated Power8 CPU, like this:
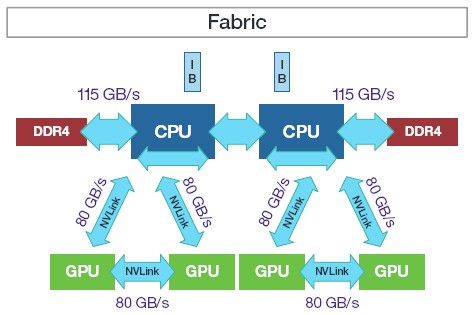
As you can see, that 80 GB/sec of bandwidth between the compute elements of the IBM Power S822LC for HPC system rivals (although does not reach) the 115 GB/sec of bandwidth coming out of each Power8 socket and into the distributed L4 cache that is implemented in the “Centaur” memory buffer chip that is required in Power8 systems. (The system has a total of 230 GB/sec of sustained memory bandwidth to L4 cache, obviously, with two sockets.) If you measure the bandwidth out of the L4 cache in the Centaur buffer chip into the DDR4 memory sticks (there is one Centaur chip for each of the eight DDR memory ports on the processor), the aggregate across 32 DIMMs (that’s four per memory port on the Power8 chip) comes to 170 GB/sec per socket and 340 GB/sec per system.
So, the DGX-1 machine, which Nvidia has tuned up specifically for deep learning, has more GPUs but they are less tightly coupled to the Intel Xeon CPUs and they have less bandwidth between the GPUs as well. The IBM system, which aims to create a very brawny node and very tight coupling of GPUs and CPUs so they can better share memory, has fewer GPUs and more bandwidth between the compute elements. IBM is aiming this Minsky box at HPC workloads, but there is no reason it cannot be used for deep learning or even accelerated databases, just like the DGX-1 can, in theory, be used for HPC.

The Minsky system has a brand new motherboard made by Wistron under the guidance of Big Blue, but the Power8 socket is the same size as in the prior Power Systems LC machines, Dylan Boday, senior manager for Linux on Power at IBM, tells The Next Platform. As with the prior “Firestone” Wistron machine in the LC lineup (also called the Power S822LC, maddeningly), the Centaur memory chips are embedded on memory riser cards and normal DDR4 memory sticks slot into these risers. (On IBM’s own Power Systems machines, the Centaur chips are embedded on hefty memory cards that weld the memory chips directly onto them, which is more expensive but provides some density benefits. In any event, the Minsky machine crafted by Wistron for IBM has a memory ranging from 128 GB to 1 TB, and for most HPC workloads, Boday says that customers will go for 128 GB or 256 GB per system, typically.
As for CPUs, the Minsky server has two processor options: an eight-core Power8 chip running at 3.25 GHz or a ten-core Power8 running at 2.86 GHz. This processor is rated at 190 watts, which is a little hot but consistent with other Power7, Power7+, and Power8 chips.

The L4 cache maxes out at 64 MB per socket with all the main memory full, and each core has 8 MB of L3 cache and 512 KB of L2 cache. The system can use NVM-Express (NVMe) over PCI-Express to talk to flash, and there are Coherent Accelerator Processor Interface (CAPI) ports to more tightly link peripherals into the Power8 compute complex. (CAPI ports debuted with the Power8 chip and offers coherent memory addressing across the Power8 processors and accelerators and network cards linked to the system over the PCI-Express bus.) The Minsky server has two PCI-Express 3.0 x16 slots and one x8 slot, and all are able to run the CAPI protocol. The system has two 2.5-inch drive bays that support either disk or flash storage.
Here is the interesting bit. With two of the ten-core Power8 chips running at 2.86 GHz, 128 GB of main memory, and four of the Tesla p100 accelerators, Boday says IBM will charge under $50,000. Nvidia is charging $129,000 for a DGX-1 system with eight of the Tesla cards plus its deep learning software stack and support for it. In other words, IBM’s Minsky pricing is consistent with Nvidia’s DGX-1 pricing. Assuming IBM is charging around $12,000 for the base Power8 machine (as it did with the Firestone system), then Big Blue is charging around $9,500 for each Tesla P100 card. We guessed back in April that Nvidia was charging around $10,500 for the Tesla P100s.
The Power S822LC for HPC system will be generally available starting September 26, and Boday says that IBM can ship them in volume and has customers in the pipeline for them. Customers who want a water-cooled option for the CPUs, GPUs, and memory can pay IBM an extra $1,500 for water blocks and piping. This water cooling will allow the Power8 chips to run in Turbo mode and the Teslas to run in GPUBoost mode in a sustained fashion and offer about a 15 percent performance bump over the air-cooled version of the Minsky machine.
Enter Supermicro And Volume Power8 Boxes
IBM has been hinting that motherboard and whitebox server maker Supermicro has been working on two Power-based machines through the OpenPower Foundation, and two machines, code-named “Briggs” and “Stratton” after the two-cycle engines a lot of us know from lawn mowers and go carts in our youth, are the first machines that Supermicro is building on behalf of IBM. (This is significant because Supermicro is the supplier of systems for IBM’s SoftLayer public cloud, and Big Blue wants to add Power compute alongside of Xeon compute on that cloud.)
As we go to press, all of the details on the Briggs system, which is known as the Power S822LC for Big Data, and its Stratton companion are not yet revealed, but here is what we know.
The Briggs machine has more storage options and capacity than the Power S822LC Firestone machine it replaces, and as you can see, it has that Supermicro feel, but with black enclosures and blue buttons instead of the gray enclosures and magenta buttons of Supermicro:

The Briggs machine uses a Supermicro motherboard, and uses a normal Power8 merchant chip and does not support NVLink ports. The system offers the same processor options – eight cores running at 3.32 GHz and ten cores running at 2.92 GHz and burning around 190 watts for both – and puts two processors in a 2U form factor. The machine has a maximum capacity of 512 GB across 16 DDR4 memory sticks, and memory bandwidth per socket is cut in half with 57.5 GB/sec of bandwidth into L4 cache from the chip and 85 GB/sec per socket going from L4 cache to DDR4 main memory. Briggs has has a maximum of 96 TB of disk storage in a dozen 3.5-inch drive bays. The system has five PCI-Express slots, with four of them CAPI-enabled, and can have two Nvidia Tesla K80 coprocessors installed. (You could install a Pascal Tesla GPU card if you want, obviously, since they come in PCI-Express versions, too. But they are harder to come by, we hear, than the SMX2 versions.)
The Briggs Power System is available starting today and has a base price of $5,999 with a configured system with two ten-core processors and 128 GB running about $11,500, according to Boday.
The Stratton machine is a lot skinnier, and uses a geared-down 130 watt Power8 part to pack more cores into a smaller space. Here it is:

The Power S821LC is, as the name suggests, a scale-out Power8 machine with two sockets that comes in a 1U form factor. This machine uses an eight-core Power8 chip that runs at 2.32 GHz or a ten-core Power8 chip that spins at 2.09 GHz; both fits in a 130 watt power envelope. The Stratton machine has four 3.5-inch SATA slots and supports up to 512 GB of memory across 16 memory sticks implemented on four memory risers, and has half the memory bandwidth into L4 cache and DDR4 memory as the Minsky machine just like Briggs. Stratton has four PCI-Express 3.0 slots, three x16 and one x8, with the x16 slots being CAPI-enabled, and has room for one Tesla K80 GPU as a coprocessor option. (Again, IBM is selling Tesla K80s with these Supermicro machines, but any Tesla that fits in a 300 watt envelope can plug into the Power S821LC.
Boday says that the base Power S821LC price is around $5,900, with a configured system (two processors and 128 GB of memory) costing around $10,500.
All three of the new Power Systems LC machines run Canonical Ubuntu Server 16.04, which is the current release, and will be able to run Red Hat Enterprise Linux 7.3 in the fourth quarter. No word on when SUSE Linux Enterprise Server will be supported on these machines, but it is looking increasingly unlikely unless a lot of customer clamor for it.
Next up, we will be looking at how IBM compares these new Power Systems LC machines against Intel Xeon boxes.


Ceph Gets Fit And Finish For Enterprise Storage
Ceph, the open source object storage born from a doctoral dissertation in 2005, has been aimed principally at highly scalable workloads found in HPC environments and, later, with hyperscalers who did not want to create their own storage anymore. For years now, Ceph has given organizations object, block, and file-based …

Hot On The Heels Of Mellanox, Nvidia Snaps Up Cumulus Networks
Last week, when we talked to Nvidia co-founder and chief executive officer, Jensen Huang, about how the datacenter was becoming the unit of compute and in such a world networking was critical, it was obvious that acquiring Mellanox Technologies for $6.9 billion was just the beginning of the strategy that …
Spectrum-4 Ethernet Leaps To 800G With Nvidia Circuits
When Nvidia announced a deal to buy Mellanox Technologies for $6.9 billion in March 2019, everyone spent a lot of time thinking about the synergies between the two companies and how networking was going to become an increasingly important part of the distributed systems that run HPC and AI workloads. …
The fact that some graphics are written with bidirectional bandwidth while others use directed bandwidth is very obfuscating. Can’t they pick a convention and stick to it? Or at least be explicit which they mean?
Briggs/Stratton and those blades of grass, It would be nice if it could cut the lawn while figuring the derivatives! So what about any new Tyan/other offerings, and can AMDs GPUs be used on the PCIe only versions? AMD always packs more FP units on its consumer SKUs relative to AMD’s professional GPU SKUs, and lots more than Nvidia provides on Nvidia’s consumer GPU SKUs. I’d like to see what some low cost power8/9 licensee’s product could do at Linux/Vulkan/OpenGL Graphics for Blender 3d rendering, or gaming for also. AMD has open sourced its ProRender(Graphics and GPU accelerated Ray Tracing software). So I’d love to see some Power8/AMD GCN GPU rendering over a PCIe connected AMD GPU, I’d imagine the drivers could be a problem, but maybe some Power8 licensee could brand a Linux OS power8 workstation SKU for rendering workloads.
“The L4 cache maxes out at 64 GB per socket with all the main memory full…” Should the L4 cache not be 128 MB max ?
64MB, actually. 16MB per Centaur, of which this machine has 4 per socket.
“All three of the new Power Systems LC machines run Canonical Ubuntu Server 10.04, which is the current release,”
I suspect that number is off by about 6 🙂
Wow! Massive bandwidth. Looking forward to try them!
I would be cautious with the IBM bandwidth claims, as POWER8 has an excellent bandwidth of 230GB/sec. But in practice, POWER8 only achieves 70GB/sec or so. This is 30% of the claimed bandwidth. It is possible that this NVLink also achieves 30% of the performance in practice. So look for benchmarks first and do not trust IBM marketing?
https://blogs.oracle.com/BestPerf/entry/20151025_stream_sparcm7
Hey Keb, how’s the shill life treating you? You’re notably late on this article and for once you’re not posting at the top of the comments! I’m impressed! Then again, it was that kind of marketing that drew my company away from SPARC anyway.
So, you claim that POWER8’s memory performance doesn’t hold up to the claims, yet you seem to forget that system configuration plays quite a significant part in these things. See, POWER8’s memory is buffered, but not just off-the-shelf Registered DDR3 here, they have their own cache and buffering chip called Centaur. POWER8’s memory system is split into 2 parts, you have the on-processor memory controller and you have the Centaur. The on-processor controller handles allocation of memory to the Centaurs, and requests the data from the Centaurs which then handles the request to the DDR3/4. Under an ideal situation a system will use 8 Centaur buffers per socket. This allows for 230.8GB/s of bandwidth per socket.
Now that we have the basics of POWER8 memory defined, lets go through the problems with that benchmark. First of all, I want to point out that you linked to an Oracle ran benchmark on Oracles own site touting the supremacy of Oracles own products. This should strike anyone as suspicious.
Second, I need to point out that the memory configuration for every system tested was listed. Except the IBM S824. We know the number of DIMMs used in every system but that one. That doesn’t sound very important but it actually is. IBM don’t use off the shelf DIMMs for their POWER8 machines, they use what they call CDIMMS (This is only true for their own systems, 3rd party systems use standard DIMMs). CDIMMs are special in that they have the Centaur memory buffer on each DIMM. This means that in an ideal system you will have 8 CDIMMs occupied per socket. You have less than that, and you’re running at lowered performance. So, Oracle only lists the memory capacity and not the amount of DIMMs used in the system, yet they do for every other system. Just a bit of a red flag here, bud.
Third, the benchmark lists the 2 socket IBM systems as having 4 chips, and pits them against 4 socket systems because of this. The systems listed use the Murano DCM. Basically a POWER8 die sliced in half, created when early yields were poor; a full POWER8 SCM has twice the cores and bandwidth of a single Murano die. The other available POWER8 dies are Venice and Turismo. Both SCMs. Both with full core counts. Turismo is used in OpenPOWER systems while Venice is used in high-end Enterprise systems like the E880. Turismo has notably only been used in systems with only 4 Centaurs or less per socket/chip. Take the Core i7. It scales from dual-core ULV laptop chips to 10-core enthusiast monsters, POWER8 scales to its own range of configurations. Looking at half of a Murano socket and claiming it’s representative of all POWER8 is disingenuous.
Fourth, this bisection bandwidth is nonsense. I’ll put it in simple terms. No one cares about this. It’s a thing Oracle made up that does not accurately measure anything. In fact, do something for me. Google “STREAM Bisection”. You know what you’ll find as the top result? That benchmark. And you know what else you’ll find? Nothing of relevance. See, here’s the thing. Not even Oracle has used the benchmark before. They used it one time. Once. Only ever for this benchmark. No one cares. No one ever has. This is not a real world benchmark that reflects actual performance.
Have fun, Keb. I’ll be seeing you around correcting your anything-not-Oracle FUD wherever I see it.
I will seek to explain this using very small words, so as to be comprehensible even to Oracle shills.
There are different types of Power8.
Amazing, huh?
Top-end Power8 – Venice, the die used in E870/E880 – has the full 230GB/s of memory bandwidth, as it has eight Centaur links. Other P8 dice and configurations have less, as meets the needs of the machines they go into. See on this page how some configurations are marked as “115GB/s” and “57GB/s”? Those are configurations with four and two Centaur links respectively. I’ve run Stream on a four-Centaur, one-CPU machine myself – it gets 95GB/s STREAM Triad roughly. (And that’s a system you can buy for under US$5k!) That’s 82% of what IBM promises for peak bandwidth on these machines, which is a fairly respectable result. An 8-Centaur machine, like E870 or E880, would (scaling from that) get ~180-190GB/s STREAM Triad per CPU.
You constantly like to compare to the Murano DCM, which as the other poster explains, was basically a way of making Venice-class perf/socket out of a pair of smaller dice when early yields weren’t so great. A single Murano die is not somehow the be-all and end-all of Power8 performance.