

It is not news that offloading work from CPUs to GPUs can grant radical speedups, but what can come as a surprise is that scaling of these workloads doesn’t change just because they run faster. Moving beyond a single node means encountering a performance wall, that is, unless something can glue everything together so it can scale at will.
There are already technologies that can take multiple units of compute and have them share work from supercomputing and other areas (consider ScaleMP, for instance) but there are limitations to these approaches and thus far, they haven’t extended to meet the capabilities of accelerators and custom processors in a flexible, accessible way across different deployment mechanisms (cloud, bare metal, via containers, etc.). However, as we described last week in our story about GPU database company, MapD, and its effort pool GPU nodes to create a distributed accelerated database that runs over 70X faster in a cloud environment (IBM/SoftLayer) via an “interposer” from “software defined supercomputing” startup, Bitfusion.
The MapD GPU database story captured a great deal of attention, but the Bitfusion piece of the puzzle left some readers scratching their heads about how it actually works. After all, anything that can circumvent hardware investments, especially for expensive accelerators, is worth a closer look.
We talked to Bitfusion late last year when they first emerged as one company that could get GPUs, FPGAs, and specialized processors to pool together and play with larger clusters. Since that time, the company has received wider attention, in part because of their availability in the AWS Marketplace for test and dev users and GPU acceleration (for a mere approximate 10% of the infrastructure cost), and also because real users (like MapD) are showing what can happen when resources can be pooled, sliced and diced, and reconfigured into specific machine sizes and specs with features layered on top including fault tolerance and performance optimization.
The idea is simple. For instance, imagine you have 1000 CPU only nodes and have only invested in 10 GPU servers. Bitfusion’s Boost layer allows you to make those 10 GPU servers attach to any of those 1000 CPU nodes. From then, one can slice and dice since many applications only need a small amount of GPU and memory (as in the MapD case). This is useful for those wanting to create large machines for deep learning, to slice and dice for prototyping, or pool their GPUs. And indeed, while the per node pricing for bare metal on those GPU nodes is (list) $6,000, consider the cost of scaling by adding more GPU nodes in the datacenter—and look too at how low the utilization probably is compared to the CPU only nodes.
The Boost software works by intercepting the application at the API level. When this happens, all the data associated with each function is known—so every CUDA call (for instance) is done in a semantic way, meaning it’s a rich intercept with all data requirements for all functions intact. Once that is done, the data is rounded up, sent over the standard network, processed on the other side, and all results are combined. Under this is a performance and optimization layer that can automatically introduce performance optimizations, which is necessary in a cloud environment—a place where Bitfusion is doing around 80% of its business with bare metal clouds and servers for analytics and deep learning comprising the other approximate 20%.
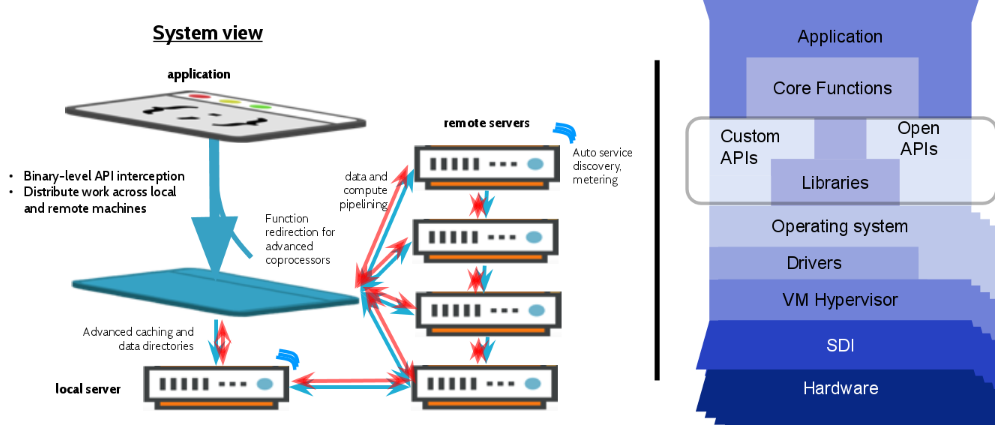
As a side note, part of what makes this all broadly useful is that all of this happens in user space with no special privileges or lifting from the kernel, virtual machine, hypervisor or any other part of the infrastructure. There is no need to install some Bitfusion version of an operating system image; it all sits on top of the OS, which gives the team flexibility in terms of what they can work with, both on the device level (GPU, FPGA, ASICs, etc.) and in terms of adding new features and capabilities. This position on top of the operating system without special work means they can be deployed on bare metal, virtual machines, VMware, Xen, and different container technologies—it doesn’t matter because of this placement in the stack.
“Our background is in the semiconductor and HPC spaces,” Bitfusion’s CTO, Mazhar Memon, tells The Next Platform. His background in HPC systems at Intel and the company’s CEO, Subbu Rama’s experiences at Dell on the low-power CPU and cloud sides combined give the team valuable perspective about what is needed at scale for accelerated computing. While their beginnings were focused on HPC given the emphasis on accelerators and large-scale systems, the rise of machine learning and analytics has given Bitfusion a unique boost since FPGAs, GPUs, and custom ASICs are the stars of the new crop of AI-driven applications.
“At the very beginning we thought HPC was hard to use for the average end user. Think about all the things that need to be built, tuned, and connected—not to mention the mundane things like driver versions and compatibility. These are big things. So this Boost layer, which sits right on top of the OS can add compatibility across all environments. There is no published API to port code to. We don’t have OS requirements that force you to use our image. Users are not stuck with Infiniband, which can be prohibitive,” says Memon. “We wanted this to be latency sensitive but easy for use in cloud, offices, or in datacenters with standard networking and infrastructure. It’s a new kind of virtualization that allows you to introduce new functionality into software, get scale, and let applications see more hardware than what is physically attached to the current node. It’s about getting full use out of HPC hardware.”
While Bitfusion has built something useful, even MapD, which couldn’t have reached their impressive numbers without Boost, they are looking beyond Bitfusion and working on their own distributed framework, one that parallelizes and pools both CPU and GPU resources. Where MapD is targeting for the scale of its eponymous database is to span up to hundreds of billions of rows and maybe a few racks of machines. While it is possible that others can take a similar tack for various applications, Bitfusion stands alone in what it is able to do.
Of greater interest now, however, is the company’s position in the market. Like so many other HPC-focused companies that had to work hard to stand out among the supercomputing set, deep learning and machine learning hardware expertise is now in great demand. Companies that carved out a niche in this hardware space have a unique in with deep learning customers—a fact that is not lost on Bitfusion’s CEO.
Rama says that they have shifted beyond HPC workloads in this direction and in advanced analytics, propelled by an early emphasis on HPC accelerators like GPUs. While FPGAs are still on the horizon for real users, they are also early adopters and enablers there too. Even more noteworthy is the fact that we are seeing a rise in interest in custom ASICs for the above mentioned workloads. Although it takes some heavy lifting on the Bitfusion side to get these hardware devices ready for their software, it is well worth the effort and lets small hardware makers come out of the gate with a software interface that can speak across multiple platforms.

The Appetite For Datacenter Compute Is Ravenous
It has been an invaluable asset for AMD as it re-engaged in the datacenter in the past decade to have Forrest Norrod as the general manager of its datacenter business. Norrod ran the custom server business at Dell for many years after working on X86 processors at Cyrix and being …

Sizing Up Compute Engines For HPC Work At 64-Bit Precision
If you want a CPU that has the floating point performance of a GPU, all you have to do is wait six or so years and the CPU roadmaps can catch up. This seems like a long time to wait, which is why so many HPC centers made the leap …

Chiplet Cloud Can Bring The Cost Of LLMs Way Down
If Nvidia and AMD are licking their lips thinking about all of the GPUs they can sell to the hyperscalers and cloud builders to support their huge aspirations in generative AI – particularly when it comes to the OpenAI GPT large language model that is the centerpiece of all of …
I read so much about HPC and find it very interesting, but despite all the hype/performance claims, I’ve yet to come across an article that does a good job articulating the “non-industry” specific journey of turning unstructured data sources into a structured topology that can actually leverage the high degrees of parallelism needed for HPC. Or let’s even say a company’s line of business applications already use content from a well designed data warehouse. If 3-5+ years ago HPC simply meant scaling their infrastructure via more on-premise load balancing hardware, then trying to achieve HPC today w/ the advent of GPUs and cloud technology would require a complete overhaul/transformation of ones data warehouse strategy right? Furthermore, if the data isn’t purely made of scientific numbers in nature, then should companies assume there’s no opportunity here? I know they’re plenty of well documented use cases for HPC and cloud accelerators, but it appears like we’d have to stack API’s on top of API’s to get something like this to work while continually having to worry about the point of diminishing returns with performance.