

When it comes to deep learning innovation on the hardware front, few other research centers have been as forthcoming with their results as Baidu. Specifically, the company’s Silicon Valley AI Lab (SVAIL) has been the center of some noteworthy work on GPU-based deep learning as well as exploratory efforts using novel architectures specifically for ultra-fast training and inference.
It stands to reason that teams at SVAIL don’t simply throw hardware at the wall to see what sticks, even though they seem to have more to toss around than most. Over the last couple of years, they have broken down their own benchmarking process into a set of operations that can be generalizable across certain problem areas while still offering a drill-down into which hardware performs best.
These efforts culminated today in a new open source deep learning benchmark that could help shift hardware and device makers toward the real-world needs of shops that are focused on high performance, efficient training and inference for models powering speech and image recognition, computer vision, and other areas. This effort, called DeepBench, is interesting in that it does not look at entire models, but rather operations, so users and hardware makers alike can see where the bottlenecks lie in dense matrix multiplication, convolutions, recurrent layer, and all-reduce operations.
As SVAIL’s Sharan Narang says, “Although the fundamental computations behind deep learning are well understood, the way they are used in practice can be surprisingly diverse. For example, a matrix multiplication may be compute-bound, bandwidth-bound, or occupancy-bound, based on the size of the matrices being multiplied and the kernel implementation.” In addition, there are also many different parameters and ways to tune the hardware, so coming up with the most efficient and high performance configuration itself is a big challenge.”
“DeepBench attempts to answer the question, ‘Which hardware provides the best performance on the basic operations used for training deep neural networks?’. We specify these operations at a low level, suitable for use in hardware simulators for groups building new processors targeted at deep learning.”
The point then is to provide a benchmark where the various elements of deep learning workloads can be examined from a hardware performance perspective, then understood by users in the context of their own applications. “The goal was to build a list of operations the hardware vendors can use to learn more about what is important in deep learning and to draw a line in the sand to encourage them to do better,” Narang tells The Next Platform. “We chose to benchmark the operations themselves because benchmarking a model is tricky and besides, models themselves are not transferrable. We wanted something a level below the model itself.”
As is generally the case at Baidu’s research arm in the U.S., there is a strong Nvidia presence. This is not surprising in that GPUs were the first accelerator for deep learning and still dominate the training space in particular. Narang now focuses on performance and programmability for the many devices Baidu explores for next generation tools for boosting deep learning training and inference. Before coming to Baidu’s lab, he focused on memory requirements for various machine learning models at Nvidia on the Tegra line as well as in work he did at Georgia Tech. His colleague, Greg Diamos, who also talked to The Next Platform this week, was previously on the research team at Nvidia, where he went after developing the GPU Ocelot dynamic compiler tool at Georgia Tech.
As Diamos adds, “Many of these higher level models for speech, computer vision, and so on, might map down to the same set of primitives. We did this internally to see what operations those models map to and collected them together into the first release of the benchmark. Those working on different applications can see what is missing for their applications and we can work with them to grow the benchmark to encompass the many building blocks of deep learning.”
In looking at these common threads for determining the right hardware for the deep learning task at hand, the duo have run the benchmarks for various deep learning elements on the TitanX Pascal variant alongside the Intel Xeon Phi. It would have been most interesting to see results for the P100 Pascal part, but Baidu is not ready to spill on those numbers yet since the test Pascals they have are not ready for prime time. “Even though we have a few of those parts, they’re not factory clocked, so they’re not fair to include in a benchmark like this because they are not what you would buy if you want to a store. We are going to add more hardware and results to this, so the P100 based systems would be an obvious candidate eventually,” Diamos says.
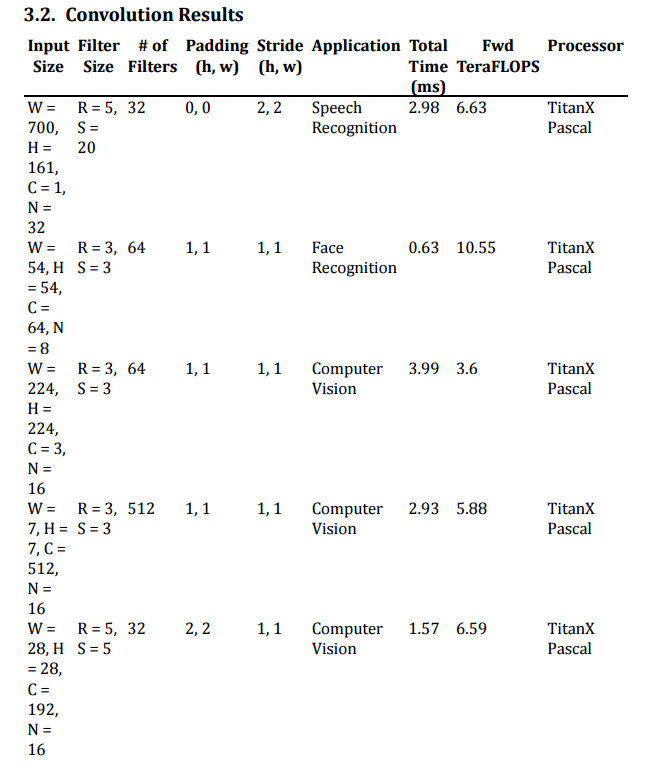
Out of the several deep learning operations that are part of the benchmark set, Diamos says the convolutional results are the most interesting simply because computer vision is where the real user momentum seems to be as of late. More details about the hardware and software enviornments behind these results can be found here.
As a side note, we haven’t covered the TitanX Pascal much here. In essence, the big difference between this and the P100 is that this one is still a big GPU with a lot of single precision throughput but it does not have full double-precision or half precision capabilities. The benchmark only tests for single precision since that is what most real applications are using now, which showcases its capabilities well for now, but we do look forward to seeing how the P100 with high bandwidth memory (the current is the regular DDR5) performs on the operations listed.
Both Narang and Diamos say that the goal at this stage of the benchmark is not to offer a true head to head comparison of different processors on these elements. It’s still early days and there are many architectures to add to the list, including some of the non-general purpose ones we’ve talked about here from Wave Computing and Nervana Systems, among others. It is also designed to help hardware makers see what areas they are succeeding and falling behind in, and to push them to work with the user community for new features–to move general purpose into the realm of special purpose.
The full benchmark code and results can be found on GitHub; Narang and Diamos are looking forward to working with all hardware makers.

In A Peer-To-Peer Datacenter, PCI-Express Fabrics Will Be Pervasive
Supercomputers are expensive, and getting increasingly so. Even if they are delivering impressive performance gains over the past decade, modern HPC workloads require an incredible amount of performance, and this is particularly true of any workload that is going to blend together traditional HPC simulation and modeling with some sort …
AMD Plots Interception Course With Nvidia GPU And System Roadmaps
To a certain extent, Nvidia and AMD are not really selling GPU compute capacity as much as they are reselling just enough HBM memory capacity and bandwidth to barely balance out the HBM memory they can get their hands on, thereby justifying the ever-embiggening amount of compute their GPU complexes …
Different GPU Horses For Different Datacenter Courses
If the semiconductor business teaches us anything, it is that volumes matter more than architecture. A great design doesn’t mean all that much if the intellectual property in that design can’t be spread across a wide number of customers addressing an even wider array of workloads. How many interesting and …
Interesting to see how Pascal falls of the rail when you’re doing some actual real work in the CV tasks. Rather shocking, only a third of the promised performance end up, That’s pretty lousy conversion rate. Even more so when you considering a 224×224 input image is still tiny and without a previous region extractor or attention/ gaze director in many real application cases pretty useless.
It would only be interesting in such a way if comparison scores were given to show how those same benchmarks performed on other architectures. You also can’t claim that a benchmark on one card (TitanX in this case) is generalizable to an architecture as a whole (Pascal) without considering where the bottlenecks are.
If no one has done it by the weekend my goal is to benchmark the AWS GPU instances.