

Training a machine learning algorithm to accurately solve complex problems requires large amounts of data. The previous article discussed how scalable distributed parallel computing using a high-performance communications fabric like Intel Omni-Path Architecture (Intel OPA) is an essential part of what makes the training of deep learning on large complex datasets tractable in both the data center and within the cloud. Preparing large unstructured data sets for machine learning can be as intensive a task as the training process – especially for the file-system and storage subsystem(s). Starting (and restarting) big data training jobs using tens of thousands of clients also make severe demands on the file-system.
The Lustre* file-system, which is part of the Intel Scalable System Framework (Intel SSF), is the current de facto high-performance, parallel/distributed file-system. According to Brent Gorda (General Manager, Intel HPC Storage), “Lustre currently runs on 9 out of 10 of the world’s largest supercomputers and over 70 of the top 100 systems”. “Lustre owns the high ground” Gorda said as he pointed out how machines like the Fujitsu K-machine can sustain a 3 TB/s (terabytes per second) read performance and 1.4 TB/s write performance [1]. This makes it attractive for commercial companies who are using Lustre for machine learning in a big way.
Lustre currently runs on 9 out of 10 of the world’s largest supercomputers and over 70 of the top 100 systems – Brent Gorda (General Manager, Intel HPC Storage)
Lustre is an open-source project as is the forward thinking DAOS (Distributed Application Object Storage). Both projects position Intel to deliver high-performance data for an exascale supercomputing future.
As the Intel General Manager for the Intel HPC Storage, Gorda can definitively say that, “Intel takes open-source very, very seriously”. His long history with Lustre (Brent co-founded and led Whamcloud, a startup focused on the Lustre technology which was acquired by Intel in 2012) substantiates the success of the Intel Lustre effort when he says, “There is a lot of confidence in Lustre after the Intel acquisition”, as exemplified by “a convergence to the Lustre single source tree supported by Intel. This was recently amplified with the Seagate announcement that it will adopt Intel Enterprise Edition for Lustre (IEEL) as its baseline Lustre distribution.”
Data handling for machine learning
It is possible to train on large and complex data sets using an exascale capable mapping such as the one by Farber discussed in the first article in this series. The following graph shows the performance and near-linear scaling to 3,000 Intel Xeon Phi™ coprocessors SE10P observed on the TACC Stampede supercomputer. Each of these Intel Xeon Phi coprocessors contains 8 GB of GDDR5 RAM. In other words, this hardware configuration can support training using nearly 24 terabytes of high-speed local Intel Xeon Phi processor memory.
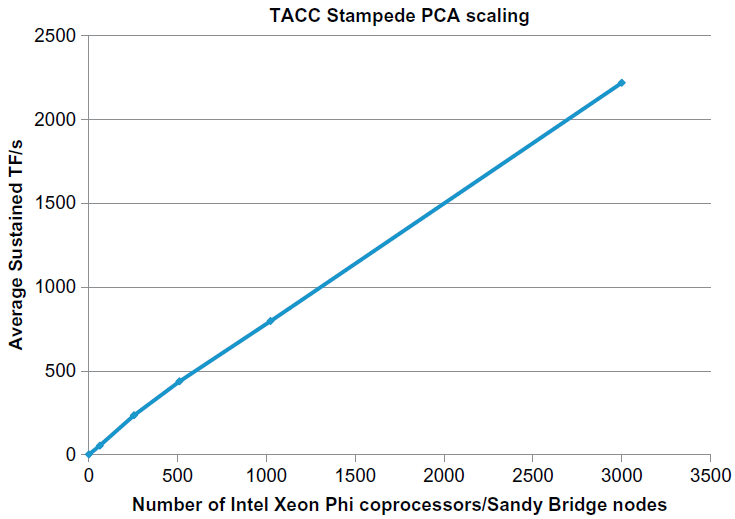
The slight bend in the graph between 0 to 500 nodes has been attributed to the incorporation of additional layers of switches into the MPI application, meaning data packets had to make more hops to get to their destination. The denser switches provided by Intel OPA will reduce that effect.
Data preprocessing
Lustre plays a key role in the pre-processing and handling of big-data training and cross-validation sets as it provides scalable high-performance access to storage. Not surprisingly, the preprocessing of the training data, especially using unstructured data sets, can be as complex a computational problem as the training itself, which is why the performance, scalability, and adaptability of the data preprocessing workflow is an important part of machine learning.
There are a variety of popular workflow frameworks for data pre-processing. In my classes and via online tutorials [2], I teach students using a click-together framework that I created at Los Alamos National Laboratory that is illustrated in the schematic below. This framework incorporates “lessons learning” while performing machine learning at the US national laboratories and in commercial companies since the 1980s.
This is but one example of a distributed data pre-processing framework that can run across a LAN, via the WAN, or within a cloud as there are many popular work flow frameworks. I teach the click-together framework due to its simplicity and efficiency. Workflows can utilize as many computational nodes as are made available and codes can run on both Intel Xeon and Intel Xeon Phi hardware as well as other devices. The freely available Google Protobufs [3] with its serialization format lets programmers work their favorite language of choice from C/C++ to Python and R to name a few [4]. As I point out to my students, there are a few performance disadvantages to using protobufs – namely extra copies – when using offload mode devices. Intel Xeon and the newest Intel Xeon Phi processors (codename Knights Landing) when booted in self-hosted mode will not have this issue. Aside from that, Google protobufs are an excellent, production-proven in the Google data centers serialization method for structured data that is quite fast.
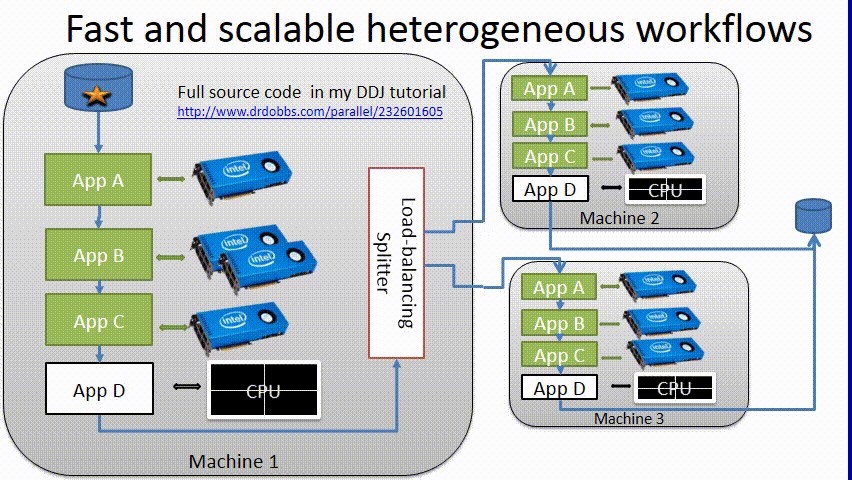
The disk icons in the schematic show that data can originate from storage and eventually be written back to storage for later use in training and for archival purposes. This particular framework performs streaming reads and writes which can scale to the largest supercomputers and achieve high performance on a Lustre file-system. Archival resilience is also provided by both Lustre and this framework. Lustre HSM (Hierarchical Storage Management) can migrate data to and from petabyte archival products from a number of vendors. The click-together framework utilizes redundant information (to guard against bit-rot) and version numbers to ensure seamless use of data. For example, I still use data from the 1980s on modern machines with the current framework.
Succinctly, data preprocessing for machine learning (as well as other HPC problems) needs to scale well, which requires a high-performance, scalable distributed file-system such as Lustre. These file-systems also need to have seamless access to archival storage to minimize data management issues for data scientists.
Loading data in a scalable manner with Lustre
Once the big data training set is prepared, the focus then becomes on the scalability and performance of the data load. Happily with Lustre, the data load can scale as needed to support the needs of today’s leadership class supercomputers, and institutional compute clusters as well as future systems.
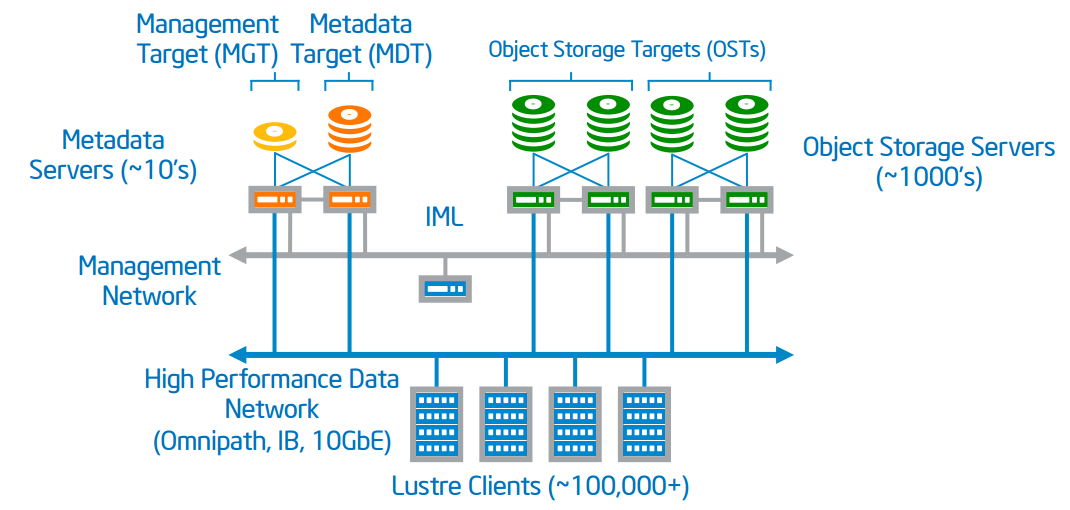
The schematic below shows that the data load can occur in an MPI (Message Passing Interface) environment simply by having each client open the training file, seek to the appropriate location and then sequentially read (e.g. stream) the data into local memory.

The scaling graph in Figure 2 shows that the filesystem will receive the open requests from 3,000 MPI clients. These open requests are referred to as meta-data operations. The Lustre meta-data architecture is designed to handle tens of thousands of concurrent metadata operations. Gorda notes that, “Lustre has grown to scale up to 80,000 metadata operations per server, which can scale-further by adding of metadata servers”. In other words, a single metadata server can handle 80k metadata operations per second while a ten metadata server configuration can manage a far greater number of metadata operations per second. Further, high-demand portions of the filesystem tree can be isolated so they don’t have a performance impact for other users of the filesystem, which is perfect for data intensive HPC workloads like machine learning.
Lustre in the cloud
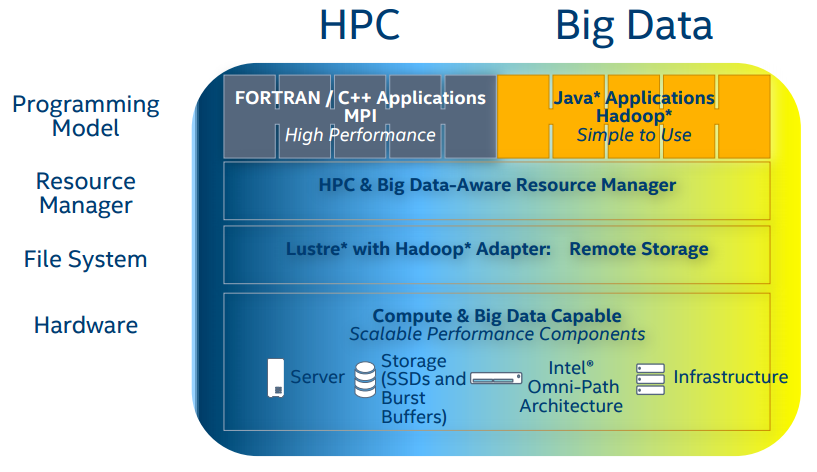
For cloud-based machine learning, Lustre provides the storage frameworks for big data in the data center as well as the cloud. For example, both Microsoft Azure and AWS let users configure their cloud instances to use Lustre as the distributed filesystem. The challenge with running in a cloud environment is that HDFS, which is written in Java, appears to be a bottleneck. As can be seen in the graphic below, Lustre provides a Hadoop adapter to provide high-performance storage access.
DAOS and the future of Lustre
Lustre is part of the forward thinking DAOS (Distributed Application Object Storage) project. DAOS (Distributed Application Object Storage) is a forward-thinking open-source next step in HPC file-systems that utilizes objects rather than files. Lustre is a component in the DAOS effort. Both projects position Intel to deliver high-performance data for an exascale supercomputing future.
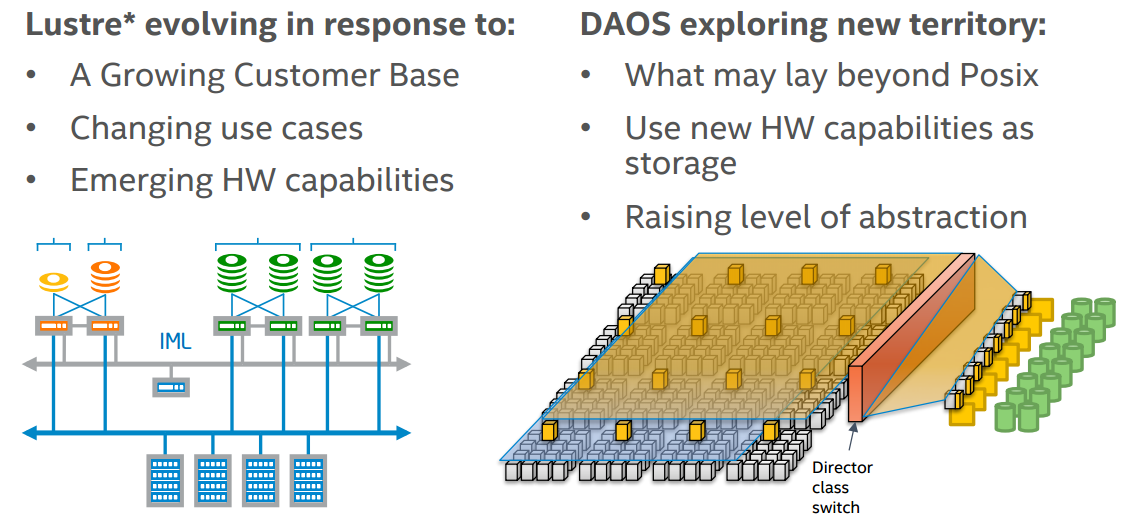
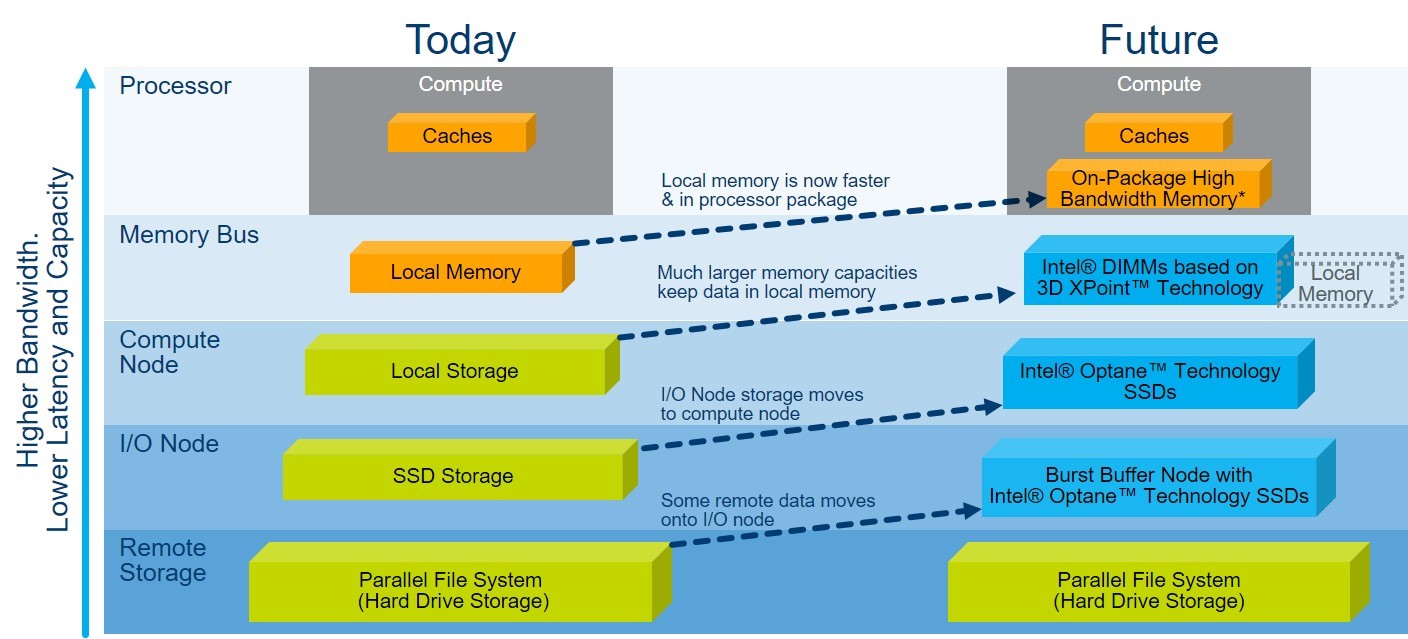
Through the use of innovative technologies such as 3D XPoint™, Intel OPA and DAOS that will keep hot data local to the processors, Gorda believes it will be possible to get much bigger speedups for short I/O’s (vs. large streaming checkpoint files).
This is the third in a multi-part series on machine learning that examines the impact of Intel SSF technology on this valuable HPC field. Intel SSF is designed to help the HPC community utilize the right combinations of technology for machine learning and other HPC applications.
Succinctly, exascale-capable machine learning and other data-intensive HPC workloads cannot scale unless the storage filesystem can scale to meet the increased demands for data. This makes Lustre – the de facto high-performance filesystem – a core component in any machine learning framework and DAOS a storage project to watch.
Rob Farber is a global technology consultant and author with an extensive background in HPC and in developing machine learning technology that he applies at national labs and commercial organizations. He can be reached at info@techenablement.com.


Blazing The Trail For Exascale Storage
When it comes to advanced technologies at the high end of compute, networking, and storage, Lawrence Livermore National Laboratory is one of the world’s pathfinding testbeds. Trying new things at scale is a big part of the mandate for the lab, which among other things, is the US Department of …

Intel Targets DAOS Object Storage At More Than HPC
Intel is looking to position itself as a leader in AI and HPC through a holistic approach that plays to the company’s strengths across a broad swath of the IT ecosystem. This covers not just silicon hardware such as CPUs and ASICs, but also the firm’s expertise in open software …

Divide Deepens Between HPC and Enterprise Storage
The more things change, the more they stay the same in HPC storage. But for the broader enterprise world, the more things stay the same, the quicker companies are to seek out change. As long as it’s easy to manage and provides reliability, cost is not at the top of …
Be the first to comment