
Hyperscalers and the academics that often do work with them have invented a slew of distributed computing methods and frameworks to get around the problem of scaling up shared memory systems based on symmetric multiprocessing (SMP) or non-uniform memory access (NUMA) techniques that have been in the systems market for decades. SMP and NUMA systems are expensive and they do not scale to hundreds or thousands of nodes, much less the tens of thousands of nodes that hyperscalers require to support their data processing needs.
It sure would be convenient if they did. But for those who are not hyperscalers, like HPC centers or large enterprises, the good news is that they generally do not need tens of thousands of nodes and hundreds of thousands of cores to do analytics or simulation, and that means SMP or NUMA systems that scale to dozens or perhaps hundreds of nodes are particularly useful because the shared memory in these machines, at tens of terabytes, is sufficiently large enough to hold their datasets and do processing across a high speed memory fabric instead of an Ethernet, InfiniBand, or PCI-Express fabric.
And thus, we are seeing the continuing adoption of big memory iron in the market, even in the era of very mature distributed computing that, one might think, should have obsoleted SMP and NUMA iron many years ago. We hesitate to say that we think that SMP and NUMA machines will see a big resurgence, or will take more than a few points of revenue market share in a market utterly dominated by two-socket servers generally employing Intel’s Xeon E5 chips, but the persistence of big iron is still intriguing and demonstrates that the extra hardware and software engineering that goes into creating such machines still pays off for IT vendors and for the customers who pay a premium for such machines.
In the enterprise, no one has done more for the resurgence of NUMA systems than SAP, which is hosting its annual Sapphire user group conference this week. The initial deployments of its HANA in-memory database were aimed at data warehousing applications and could run across clustered machines running Xeon E7 machines of moderate size, and eventually SAP supported Power-based systems. But for production applications running atop HANA, SAP does not recommend using clusters but rather multi-node systems that have a shared memory space, and that has been driving sales of NUMA big iron. It has also compelled cloud computing giants Amazon Web Services to offer its first EC2 instances based on Xeon E7 systems, and Microsoft to do the same for its Azure Cloud.
For AWS and Azure to do something not based on commodity Xeon E5 servers speaks volumes, just as it will be significant when (and if) AWS carves out a piece of its infrastructure to support proper Tesla GPUs for accelerated computing or links nodes through InfiniBand networks for super-low latency. Microsoft added Tesla compute to Azure last October, and has dabbled with InfiniBand for several of its services. The Azure specs claim that Microsoft offers 32 Gb/sec InfiniBand on A8 and A9 instances, but DDR InfiniBand runs at 20 Gb/sec and QDR InfiniBand runs at 40 Gb/sec, so that is a neat trick. Neither has 100 Gb/sec InfiniBand available, which would demonstrate a certain level of seriousness about supporting HPC compute workloads and even clustered or parallel file system storage to go along with it.
The support of SAP HANA and the S4/HANA application stack on the AWS and Azure clouds on top of Xeon E7 iron is perhaps as good of a leading indicator of the need for NUMA for in-memory applications as anything. Of course makers of NUMA big iron want to sell their boxes running in-memory databases like SAP HANA, Oracle 12c, IBM DB2 BLU, and Microsoft SQL Server. But consider that this is just the first step on the NUMA path for the cloud builders, cutting against their hyperscale ethos of homogeneous infrastructure. They will eventually need to offer even larger NUMA machines as their customers workloads grow. Memory capacity will not go down on these systems, after all, and each year brings new data and more applications that drive even more data.
In-Memory In The Clouds
The new X1 instances from AWS make good on a promise that Amazon made last year to add heftier systems for supporting SAP HANA. The x1.32xlarge instance is based on a four-socket “Haswell” Xeon E7-8880 v3, which have a total of 64 cores running at 2.3 GHz and deliver 128 virtual threads across the custom Xen hypervisor used by AWS to carve up and virtualize its systems. The E7-8880 v3 chip, as you can see from our analysis of the Haswell Xeon E7s from their launch last May, have 18 cores so the four-socket system actually has 72 physical cores. Our guess is that Amazon is using two of the cores on each socket to run its own Xen virtualization software stack and specifically to boost the performance of the virtual networking that links the SAP HANA apps to the outside world and to the Elastic Block Storage that interfaces with HANA as a backup for the information stored in main memory. The X1 instance has 2 TB of virtual memory, which is nowhere near the 12 TB limit that a physical four-socket Xeon E7 v3 machine has using 128 GB memory sticks. (Each Xeon E7 socket can support 24 DIMMs at three DIMMs per channel, for a total of 96 memory sticks in a four-socket machine.) Our guess is that AWS is populating two-thirds of the memory slots in this machine with 32 GB sticks to get that 2 TB, which leaves it room to expand memory by 50 percent just adding more sticks. When AWS moves to “Broadwell” Xeon E7 v4 machines, probably a year from now, it will no doubt offer much fatter memory configurations with an X2 instance.
The X1 instance has two 1.92 TB SSD flash drives for high I/O operations for journaling data from main memory as HANA and other in-memory databases run, and it has a 10 Gb/sec Ethernet link to EBS that has been optimized (at no cost) for HANA and other in-memory systems and a 10 Gb/sec Ethernet link to the outside world. The Haswell Xeon E7 supports transactional memory, which has significantly sped up the performance of SAP HANA. In benchmark tests last year, moving from SAP HANA SP8 to the more tuned SP9 boosted transactions by 1.8X, and then upgrading from “Ivy Bridge” Xeon E7 v2 to Haswell Xeon E7 v3 processors with their more threads, larger cache, and other improvements increased the OLTP throughput of HANA by another 1.5X on top of that. The transactional memory eliminated a lot of the contention in the database and boosted throughput by another 2.2X, for an overall performance boost of 6X.
The X1 instances are available in only selected AWS regions to start, with the US East (Northern Virginia), US West (Oregon), Europe (Ireland), Europe (Frankfurt), Asia Pacific (Tokyo), Asia Pacific (Singapore), and Asia Pacific (Sydney) regions getting them first. AWS plans to add the X1 instances to other regions and with other capacities “before too long.” In the US West and US Regions, the X1 instances cost $3.97 per hour for a three-year partial upfront reserved instance. You can pay all three years up front for $98,072, which works out to $3.73 per hour. If you want to think in terms of a one year commitment, the X1 instance costs $9.16 per hour if you make that commitment and don’t pay upfront, $7.83 per hour if you pay half upfront, and $7.67 per hour if you pay all upfront. If you want to buy the X1 instance on demand and on a whim, it costs $13.34 per hour.
An EC2 r3.8xlarge instance, which is based on Xeon E5 processors and that was certified for production HANA workloads even though it is not based on a Xeon E7, delivers 32 vCPUs and 244 GB of virtual memory with two 320 GB SSDs; it costs $2.66 per hour. The x1.32xlarge instance delivers 3.4X the performance using the EC2 Compute Unit (ECU) of the r3.8xlarge at a price per hour that is 5X higher. Considering that the Xeon E7 iron is not useful for generic workloads, this does not seem unreasonable. To many people, the cost of a virtual Xeon E7 server will be ridiculously high compared to buying one, but AWS is carrying it on its balance sheet and paying for power, cooling, space, and management and these are not free. Amazon is suggesting that customers who are using multiple R3 instances now to run distributed HANA clusters will be able to run these applications on a single X1 instance and save money. This only makes sense if they were memory bound on those R3 instances, which is more of a function of the skinny memoried E5 machines AWS was using than anything inherent in HANA. AWS should have been using fat memory to begin with for HANA, and we would argue it probably should be allowing it to run on all Xeon E5s.
Here is what a HANA Quick Start configuration looks like on AWS:
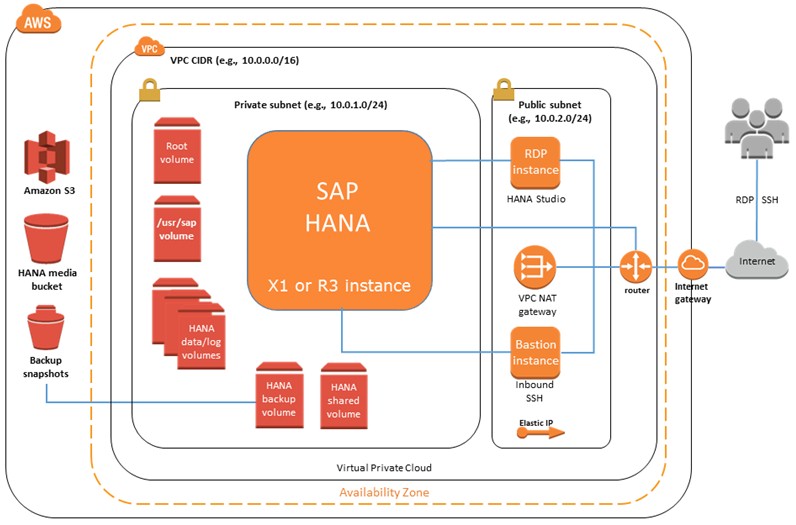
Over at Microsoft, Azure is getting four Large Instance types running Linux that are explicitly being delivered to run SAP HANA and applications like the S4/HANA ERP suite. Microsoft is going for the slightly faster Xeon E7-8890 v3 processor from the Haswell line, which spin at 2.5 GHz. Two of the Azure VMs for HANA have two processor and two have four processors, with the following memory and storage configurations:
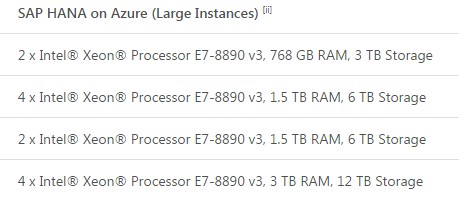
Microsoft did not provide pricing for these HANA instances, which will be available in the third quarter, but it was clearly putting a stake in the ground knowing that AWS was making its announcements. Rockwell Automation and Nortek were trotted out as early adopters of the HANA on Azure services, but details of their setups were not divulged.
Microsoft has also committed to offering multi-node support for HANA scaling up to 32 TB of memory across the cluster and aimed at data warehousing and analytics workloads as well as single node instances for OLTP and OLAP workloads on Azure GS5 instances (which are based on Xeon E5 processors) with up to 3 TB of memory. So it looks like Xeon E7 is not the only game in town for HANA, at least on the clouds. Or there will be instances based on Xeon E7s. Microsoft was not clear, but if AWS can run HANA on Xeon E5s, then it looks like Azure will be able to as well.
Getting Your Own Bigger Iron
For in-memory jobs that require more shared memory than clouds like AWS and Azure can deliver, customers have to buy their own NUMA systems. As we have chronicled since SGI revamped its all-to-all topology in the UV 300 series machines and created a special version aimed at SAP HANA, the company believes that somewhere between 6 percent and 10 percent of HANA shops running OLTP workloads (rather than data warehouses) will need something larger than an eight-socket Xeon E7 machine, which tops out at 6 TB of shared memory with the Haswell generation. (It is not clear if the memory will be extended with the impending “Broadwell” Xeon E7 v4 processors, which are looming.)
With over 291,000 ERP customers who could potentially move from Oracle, DB2, or SQL Server databases to HANA, this is a very large potential addressable market, which is one reason why Dell signed up to resell the UV 300s last July and why HPE did a similar deal in February of this year, even though it sells its own “Project DragonHawk” Superdome X systems using the Xeons and extending to sixteen cores and 12 TB in a single image. When SGI did its projections last year, it estimated that HANA represented an opportunity of around $230 million in 2015, around $700 million in 2017, and north of $1 billion in 2018. With HPE and Dell peddling the UV 300s, and perhaps others joining up to get machines with up to 32 sockets and 48 TB of shared memory, SGI has a good chance of taking down a lot of that opportunity both directly and indirectly.
The SAP environment has some even richer targets, Brian Freed, vice president and general manager of high performance data analytics at SGI, tells The Next Platform. As it turns out, SAP has a real-time financial analysis tool called Bank Analyzer, which has around 300 customers in the financial services industry using today. But SGI estimates that something on the order of 25 percent to 30 percent of its users need a heftier Xeon E7 system than a stock machine using Intel chipsets can deliver.
SGI announced this week at Sapphire Now that it has attained official certification for SAP HANA running on UV 300 machines ranging in size from 12 TB to 20 TB, and also said that to date it has sold systems for running HANA with a total 600 TB of main memory capacity, which is three times the capacity it had in the field back in September 2015. “This growth is not only sustainable, but will accelerate,” Freed predicts, based in part on the partnerships with HPE and Dell and the need for larger systems as enterprises shift over from relational databases to HANA and from Business Suite to S4/HANA.
To give you a sense of the base, Freed says that SGI has a few UV 300 machines in the field at the top-end 48 TB capacity (using very expensive 128 GB memory sticks) running HANA, and adds that the average machine has somewhere between 7 TB and 8 TB of capacity – significantly above the upper limit on a stock eight-socketer.
“This is one of those situations where the more you have, the more you want,” Freed says with a laugh. About 90 percent of its high performance data and analytics business on the UV platform is being driven by HANA, with the Oracle 12c in-memory database starting to see traction but somewhere between 18 and 24 months behind HANA in terms of customer engagement as far as SGI is concerned. About half of the UV revenues (which SGI does not break out separately from clusters, storage, and services) are driven by in-memory databases and data stores going into the enterprise, Freed estimates, and says that the pipeline for UV 300 business is five times what it was at the beginning of this year.
From all of this activity, it looks like NUMA still has a place in the datacenter and will find adoption for accelerating Spark and other in-memory frameworks, too.
In an idea world, NUMA links would be done by software and the underlying inter-node networks would be fast enough to provide good NUMA scaling across multiple nodes. But the networks are never quite fast enough to keep up with the cache and memory subsystems on the processor complex, so specific NUMA hardware always seems to be inevitable.
So HPE, Lenovo, SGI, NEC, IBM (with Power iron), and a handful of others may see some good business from the cloud builders who do not want to create their own machines that scale beyond eight sockets. Or, they may surprise us all and come up with their own NUMA architectures that scale to 16, 32, or 64 sockets or license technology from the likes of HPE, SGI, IBM, Numascale, or ScaleMP (which does NUMA in software over InfiniBand networks) to try to build larger shared memory systems. If anyone wants to open source a NUMA chipset that works with Xeon processors, that would probably cause a whole lot of upheaval in the big iron space. . . .

Move Over X86, Amazon’s Arm HPC instances Are Live
When it comes to deploying Arm in the cloud, a lot of the talk of late has centered on things like efficiency, core density, or predictability of performance. However, Amazon Web Services believes that its Arm chips can compete on performance and price/performance, and in the very picky HPC market …
The Big Clouds Get First Dibs On AMD “Genoa” Chips
The expanded lineup of AMD’s 4th generation “Genoa” Epyc server chips – built atop “Zen 4” core and some with the chip maker’s L3-boosting 3D V-Cache – unveiled at a high-profile event in San Francisco this week is quickly making its way into the cloud. Microsoft and Amazon Web Services both …
Combining AI With HPC To Find Better Battery Designs
The melding of low and high precision mathematics to accelerate the pace of scientific discovery has been a topic of discussion for some time now. During her keynote at ISSC last year, AMD chief executive officer Lisa Su mused that the combo could vastly reduce the energy requirements to scale …
Microsoft will bring SQL Server on Linux, so there is an option for potential customers to go with big NUMA machines based on Numascale or SGI high tech servers.
10Gb/s network to a machine with 2TB DRAM and 4TB of SSD really isn’t sufficient for many workloads!
Microsoft is just being honest. QDR is a 40 Gbit/sec signalling rate, but a 32 Gbit data rate. So for a fair comparison to 10G ethernet (which uses 12 Gbit signalling) Microsoft mentions the data rate, not the signal rate.
It looks like one interesting SAP HANA certified appliance is missing in this article: Bull bullionS 16 socket Broadwell E7 24TB.