

Although the future of exascale computing might be garnering the most deadlines in high performance computing, one of the most important stories unfolding in the supercomputing space, at least from a system design angle, is the merging of compute and data-intensive machines.
In many ways, merging both the compute horsepower of today’s top systems with the data-intensive support in terms of data movement, storage, and software is directly at odds with current visions of exascale supercomputers. Hence there appear to be two camps forming on either side of the Top 500 level centers; one that argues strongly in favor of supporting actual applications in the near term (next five years) and another that is aggressively pushing for the arrival of exascale computers, in part for their usefulness for a select set of “infinitely” scalable workloads—and also as a point of national pride.
 Last week we talked about the now-open assertion that exascale is a bit farther away than was initially speculated (it was 2018 three years ago, then 2020, pushed to 2022, and now 2023-2025), and have heard rumblings about China’s ambitions to take the exascale road (despite a lack of Intel involvement and a specialized, native architecture that at best, might only be able to tackle a few workloads). But for centers that have mandates from government agencies and a wide range of scientific users, reaching exascale first carries far less weight than just having jobs run efficiently and on time. IBM has discussed this at length with their data-centric model of computing. Intel has also described this balance via the single system framework and while these and vendors say these aims mesh with exascale futures, the real focus for users with mission-critical, diverse workload demands, is putting these concepts into practice.
Last week we talked about the now-open assertion that exascale is a bit farther away than was initially speculated (it was 2018 three years ago, then 2020, pushed to 2022, and now 2023-2025), and have heard rumblings about China’s ambitions to take the exascale road (despite a lack of Intel involvement and a specialized, native architecture that at best, might only be able to tackle a few workloads). But for centers that have mandates from government agencies and a wide range of scientific users, reaching exascale first carries far less weight than just having jobs run efficiently and on time. IBM has discussed this at length with their data-centric model of computing. Intel has also described this balance via the single system framework and while these and vendors say these aims mesh with exascale futures, the real focus for users with mission-critical, diverse workload demands, is putting these concepts into practice.
For many centers, especially those that serve a broad user base with a range of scientific applications, having separate large-scale clusters for compute intensive workloads and another for data-intensive applications does not make sense. This is not for purely practical energy, space, and resource considerations either, explains Katie Antypas, who heads scientific computing and data services at the National Energy Research Scientific Computing Center (NERSC), which is the main site for the Department of Energy’s Office of Science unclassified computing projects.
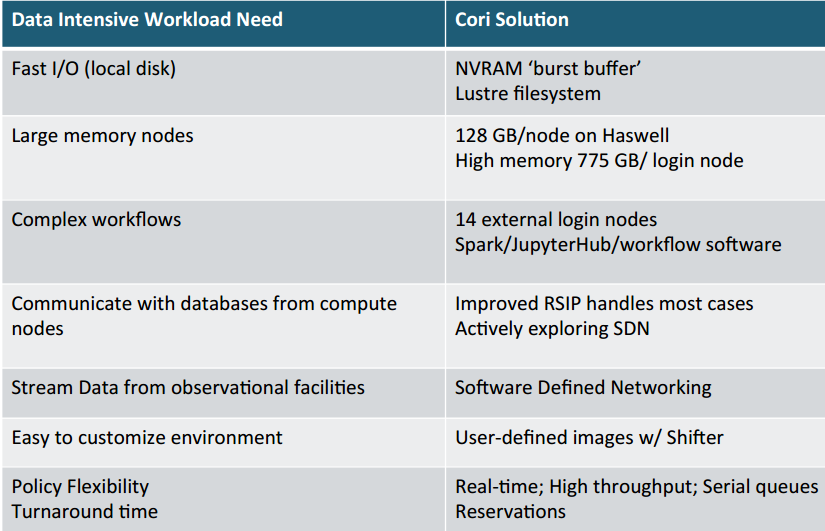
NERSC has traditionally been a leading large-scale supercomputing facility, with top machines, including Edison (a 2 petaflop Cray XC30) and more recently, Cori (another Cray XC machine based on the Haswell processor for now but with Intel Knights Landing coming this year in its second phase, along with a burst buffer). While the Cori system is directed at supporting both compute and data-intensive jobs, this marks a shift in direction for NERSC—and for other centers encountering a need for more diverse supercomputing capabilities. In short, machines that go far beyond just floating point prowess.
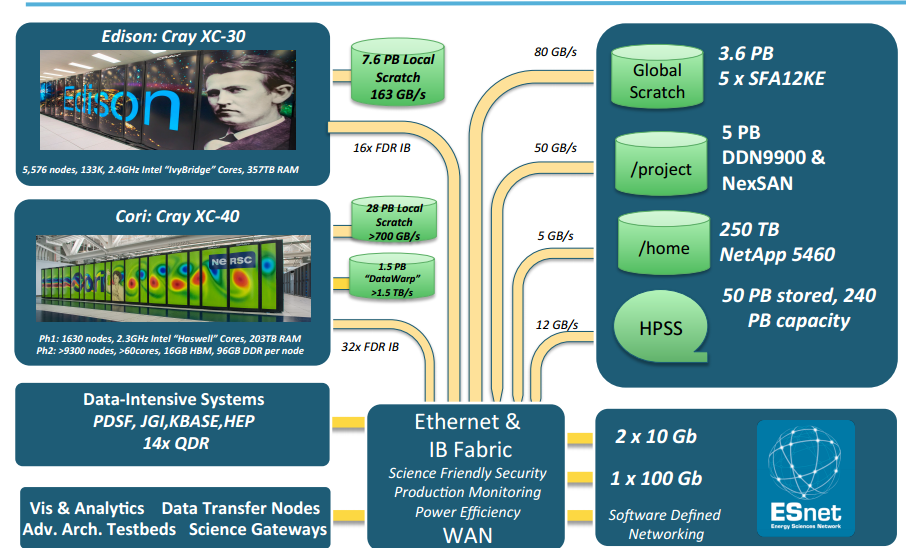
“When you think about traditional high performance computing, we often think of simulation and modeling,” Antypas explained at last week’s International Conference on Massive Storage Systems and Technology (MSST). “Some users need a lot of compute time and don’t write a lot of data, others need small amounts of compute time but need to analyze huge volumes of data…We see scientists now that want to combine large-scale data analysis with traditional modeling and simulation.” The solution to this problem is to build supercomputers that are balanced for both requirements, but of course, this is no easy task, especially for a center that has great variance in the types of applications users bring to the table.
In the past, NERSC and other computing centers have had to build dedicated clusters to support specific projects. For instance, instead of running workloads directly on ultra-large machines that do both data and compute-intensive well, there are specific clusters like PDSF, which handles detector simulation and large-scale analysis for physics, astrophysics and nuclear science collaborations and Genepool, which is set aside for the DoE’s involvement with the Joint Genome Institute’s research.
Compounding the need to build data-intensive supercomputers that can support traditional floating point-reliant applications is the fact that the data sources are driving both compute and data requirements. It will not make sense to put supercomputers next to gene sequencers, lightsource facilities, or next generation electron microscopes, all of which are going to approach a terabyte per second or more in the next five years. And since the requirements to do both traditional modeling and simulation are just as important to pairing such workloads with data-intensive analysis, only one thing makes sense for centers that are in the business of supporting applications as a primary goal (versus racing to exascale and hoping the application base can keep pace). Build systems that are balanced for both compute and data.
The Cori machine is start for NERSC, and should set the stage for other systems at other scientific computing facilities hoping to strike a balance for user demands (versus aim high for top Top 500 ranking), but the real lessons will be visible on the NERSC-9 machine in 2020, which will also focus on data-intensive scientific computing.
This is not to say that other centers with large-scale supercomputers (particularly the CORAL machines that will roll out over the next year) are not aiming for the same balance. However, it does appear the more widely varied the workloads are, the more engaged a lab or center appears to be with trends in data-intensive supercomputing on both the hardware and software side.


Going Beyond Exascale Computing
One thing is certain: The explosion of data creation in our society will continue as far as pundits and anyone else can forecast. In response, there is an insatiable demand for more advanced high performance computing to make this data useful. The IT industry has been pushing to new levels …

Using Bayesian Inference To Reverse Engineer Decades Of HPC
A collaboration including the University of Oxford, University of British Columbia, Intel, New York University, CERN, and the National Energy Research Scientific Computing Center is working to make it practical to incorporate of Bayesian inference into scientific simulators. The project is called Etalumis, which is the word “simulate” spelled backwards, and …

Python Delivers Big On Complex Unlabeled Data
A collaboration of researchers from the University of California Davis, the National Energy Research Scientific Computing Center, and Intel are working together on the DisCo project to extract insight from complex unlabeled data. DisCo is short for the Discovery of Coherent Structures, and it discovers the inherent structures in unlabeled …
IBM was the first to say that we needed data centric systems… now, all folliwing them. They are the leaders in HPC! I’m looking forward the new openPOWER based CORAL machines! any report on that?
I’m curious when they said that in reference to modern supercomputers.
Especially since SGI, Cray(YarcData), Fujitsu and NEC have all been talking about the convergence of analytics and HPC for years now and have delivered some very large scale systems specifically for that kind of data centric computing.
The new Power 9 and GP100 machines seem more compute focused than data centric to me, but it remains to be seen how they perform in HPCG tests. NVLink lets the four GPUs talk to each other and two CPUs within a node, but for large systems, communication between those nodes is usually the real bottleneck.
Everyone will have to migrate to silicon photonics if they want to keep up performance between nodes at exascale and not blow the power budget.