

There is never enough bandwidth in a datacenter that is the size of a football field and that is expected to work more or less like a single computer. While 10 Gb/sec Ethernet on the server and 40 Gb/sec Ethernet on the backbone is fine for many enterprises today, hyperscalers, cloud builders, and service providers are pushing up against these limits and crave more bandwidth.
Getting an entire industry to agree on standards and to produce products that must meet an increasingly diversifying set of needs is a challenge, and the Ethernet Alliance, an industry group that has been working with the IEEE and other standards bodies for the past decade to help shape the networking realm, has been putting out a roadmap each year to give us all a sense of where we are going. The latest roadmap was put out this week in conjunction with the Optical Fiber Communication conference, and it has a few tweaks compared to last year’s roadmap, which we walked through in detail last March.
Scott Kipp, who is director of engineering at Brocade, which makes Fibre Channel and Ethernet switches and who is also president of the Ethernet Alliance, gave us the rundown on what has changed in the past year on the roadmap. There is not a lot of change in the datacenter space, but there are some interesting things that will change the future of networking in the glass house as we approach what Kipp calls the Terabit Mountains off in the distance.
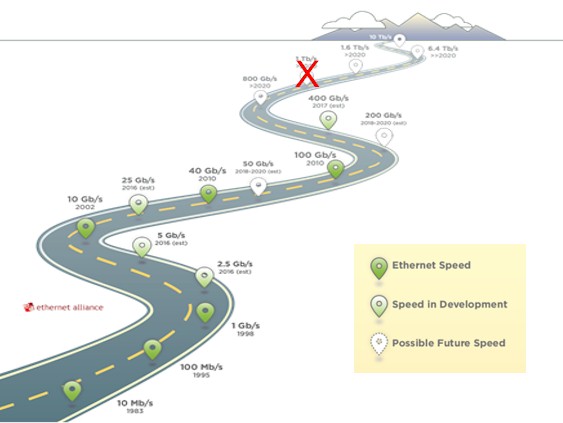
The first big change on the Ethernet roadmap is that 1 Tb/sec has been dropped as a future speed, and Kipp says that this is because the industry does not want to have to support ten lanes of traffic on devices to get to that speed. Initial 100 Gb/sec products (mostly routers, backbone switches, and uplinks on aggregation switches in the early days) were based on 10 Gb/sec lanes and had ten of them to reach that bandwidth. (These are the same lanes that were used in the stopgap 40 Gb/sec products that a portion of the market compelled the networking industry to make and that hyperscalers have largely deployed in their fabrics for the past several years.) These 10 Gb/sec lanes were hot and expensive, and the idea going forward is to push lanes to 25 Gb/sec speeds, as the current crop of Ethernet switches are doing, and then ramp up to 50 Gb/sec lanes and then 100 Gb/sec lanes and keep the lane count down around eight. So that gives us future router and switch ports running at 200 Gb/sec and 400 Gb/sec using 50 Gb/sec lanes and then 400 Gb/sec and 800 Gb/sec using 100 Gb/sec lanes.
Another change with the 2016 roadmap is that the industry has now moved from speculation to actually defining the specifications for 50 Gb/sec serial links used in downlinks to servers and leaf switches (with SFP ports), 200 Gb/sec uplinks on top of rack switches and spine or aggregation switches (with QSFP ports), and 400 Gb/sec links on routers (using CFP ports).
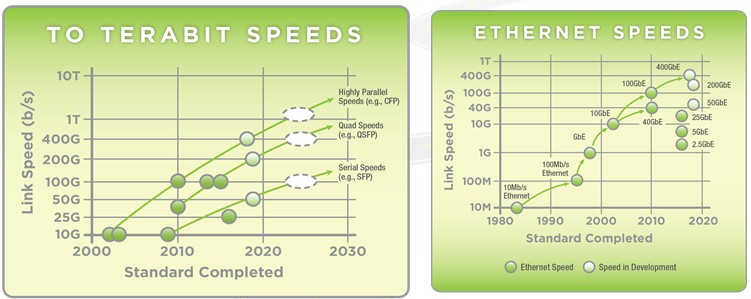
As you can see from the roadmap, the industry is still looking pretty far out to set the next serial link speed bump to 100 Gb/sec, which Kipp says is coming well after 2020 for sure, with the related 400 Gb/sec bump for spines and perhaps 1.6 Tb/sec for routers coming more or less around the same time. (In the chart above, the bullets on the lines are for when the standards are completed, not when a product will ship.) The thing to note is that the power of ten rule for Ethernet is gone, and so is the old rule for the industry, which was that each Ethernet generation gave 10X the bandwidth for 3X the cost, which was a big net improvement in cost per bit that drove the establishment of Ethernet as the dominant networking standard and that made the Internet possible.
By the way, only a year ago, the industry was expecting to formalize the standards for 50 Gb/sec serial links and 200 Gb/sec quad links around 2020 or so, and the fact that they are heading towards approval by now is a good sign that the industry is ramping up the pace of development. There is still a lot of engineering work to turn a spec into a reliable product, of course.
But the industry is getting better at this, as is evidenced by the rapid turnaround for 25G Ethernet products (about two years). We will all have Google and Microsoft to thank for much cheaper and more energy efficient networking, since it was them who compelled Mellanox Technologies and Broadcom to adopt a non-standard Ethernet speed of 25 Gb/sec at the serial link and 50 Gb/sec and 100 Gb/sec upstream on the network. The reason was simple: the 25 Gb/sec lanes that were created for a new generation of 100 Gb/sec routers were better than the 10 Gb/sec lanes used in initial 100 Gb/sec routers and switches. The resulting 25G products have 2.5X the bandwidth of 10 Gb/sec Ethernet at somewhere between 1.2X and 1.3X the price per port (and therefore a significantly lower cost per bit moved) and use about half the power consumption with a very high port density that was not available using the hotter 10 Gb/sec links.
The networking industry has heeded this lesson, and hence the ten lane 1 Tb/sec exit on the Ethernet roadmap, which would not have the right power and density profile, has been removed. The plan is to just keep doubling up lane speeds with each jump rather than trying to get to some base ten number for overall bandwidth that makes everyone feel consistent with history before the 40 Gb/sec heresy.
If you look carefully at the presentation made by Ethernet Alliance, 3.2 Tb/sec speeds have been added for somewhere well after 2020 and before 6.4 Tb/sec speeds, but it was not on the image above for some reason. Trust us, it is there unless the industry changes its mind. Also, it still says 10 Tb/sec off in the mountains (that’s a legacy base ten number right there), but really, it should be 9.8 Tb/sec or maybe 12.8 Tb/sec if we are keeping to the theme of never having more than eight lanes of traffic per link and doubling up the lane speeds with every generation.
It is hard to conceive of a single lane running at 1.6 Tb/sec, but this is what that bandwidth implies. It is also daunting to think of the bisection bandwidth of the network fabric that might use switches with ports running at such speeds, and what kind of device that might be, and what kind of applications would require this. It is also kind of fun. . . .
It also looks like the industry is going to try to push out the widespread adoption of forward error correction – something we have talked about with Cray regarding supercomputing interconnects – as long as possible. But inevitably, with the higher bandwidths will come the need to scrub the data and forward error correction can do that with complex algorithms that do not require retransmission of data when bits inevitably get flipped, but it does impose some latencies on transmissions that customers may not be happy with.
“Up until now, there has not been much of a latency hit, data just pretty much flies through,” Kipp explains to The Next Platform. “We have been discussing this and we have not made an objective for it with 50 Gb/sec, 200 Gb/sec, or even 400 Gb/sec Ethernet yet, but it is something we consider a lot. We added it to 25 Gb/sec Ethernet, and some customers, especially those running high performance networks, said they didn’t want it because the latency can add up quite a bit. So we defined a FECless version of the standard for copper cables up to three meters, and they are asking for it again at 50 Gb/sec, too. They might be able to keep it out, I am not sure.”
Forward error correction is built into switches and routers that use multimode and single mode fiber optic cables for longer hauls connecting racks in rows and rows to other datacenter rooms and datacenters to each other.
Another part of the Ethernet roadmap that has changed this year concerns the interface modules that are used in switches and routers. Here is a diagram of the current ones and the possible additional ones:
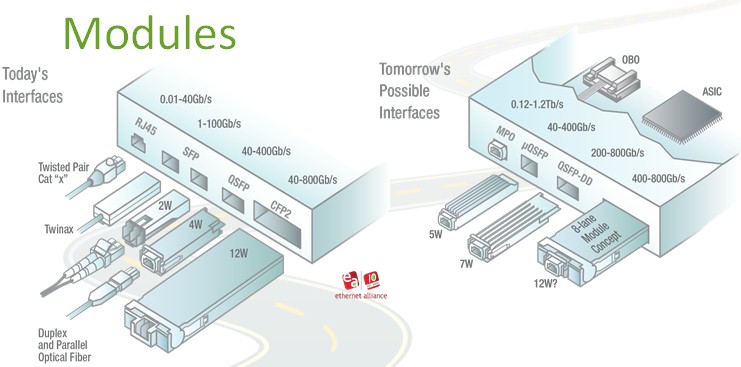
The microQSFP interface module gives a QSFP port in the form factor of an SFP port with a higher but still acceptable 5 watt thermal envelope compared to a real QSFP port that comes in at 4 watts but eats up more space. The QSFP-DD module is a double data rate device that will scale up to 800 Gb/sec in the same form factor as the current QSFP module, which scale up to 400 Gb/sec. Again, you see the wattages going up but you can’t get higher bandwidth in a lower power envelope and a smaller form factor all at the same time.
Last but not least, the Flexible Ethernet method of link aggregation, which has been proposed by the Optical Interconnect Forum, is looking like it will be adopted as an Ethernet standard at some point because some very big players (like Google) are getting behind it.
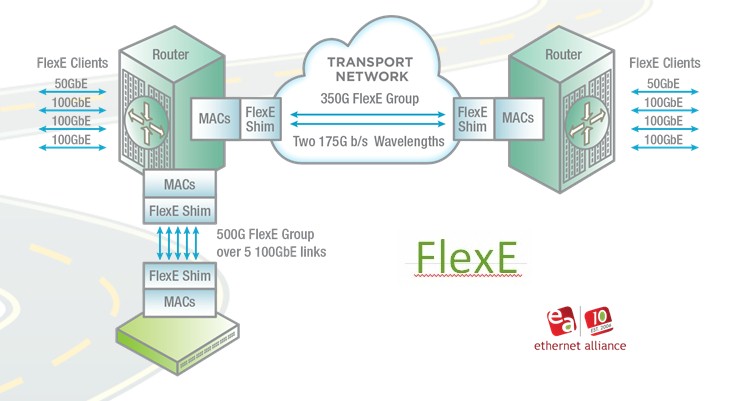
With link aggregation, multiple ports can be grouped together to provide a pipe that has much more bandwidth. But the MAC addressing is still not unified, and with FlexE, as this is called, the ASICs in the chips will be able to have multiple Ethernet pipes aggregated behind a single set of MAC addresses in the device. For all intents and purposes, this will look like a single pipe as far as the network is concerned.
Interestingly, FlexE will allow for the links between routers and between routers and either spine or leaf switches to be dialed up and down with unconventional speed bumps that meet the specific traffic needs between two points, such as the 500 Gb/sec links and 350 Gb/sec links shown in the diagram above. This is just another example of virtualization on the network, in this case separating the Ethernet layer from the MAC layer. It is not clear when this FlexE functionality will be added to router and switch ASICs, but you can bet hyperscalers, cloud builders, and service providers are itching to get it.

The Sugar Daddy Boomerang Effect: How AI Investments Puff Up The Clouds
Here’s a question for you: How much of the growth in cloud spending at Microsoft Azure, Amazon Web Services, and Google Cloud in the second quarter came from OpenAI and Anthropic spending money they got as investments out of the treasure chests of Microsoft, Amazon, and Google? We think this …
Why Would HPE Buy Juniper Networks?
It looks like Hewlett Packard Enterprise might be having a datacenter networking revival. The word on the street, as reported by the Wall Street Journal, is that HPE is getting ready to shell out $14 billion to acquire Juniper Networks, the company that played the gadfly for Internet routing and …

Hyperscalers Set The Pace For 800G Ethernet
The hyperscalers and the largest public clouds have been on the front end of each successive network bandwidth wave for more than a decade, and it only stands to reason that they, rather than the IEEE, would want to drive the standards for faster Ethernet networks. That is why the …
Pictures are too small.
Interesting bias in this article. As an FYI, neither Google nor Microsoft “compelled” Mellanox or Broadcom to adopt a non-standard speed of 25G or 50G Ethernet. In March 2014, IEEE 802.3 was offered the first opportunity to develop a standard for 25G Ethernet. There was very vocal opposition from the leadership of the Ethernet Alliance and from specific members of 802.3. In July 2014, there was a reversal of position by those same folks opposed to it in March, but by that time Microsoft, Google, Broadcom, Mellanox and Arista had partnered to form the 25G and 50G Ethernet Consortium.
Facebook are implementing 100GE Lite this year in all its data centres. See ICP Summit 2016 presentation in the Open Compute Project YouTube Channel. It uses duplex singlemode and has a reach of 500 metres. Its ten times lower cost than the 10km version. Methinks this spells the end of multimode in large data centres.