

HPC centers like to boast about the details of their supercomputing systems because they are political machines as much as they are tools for running simulations. Hyperscalers reveal some of the details behind their massive and complex systems to pump up their open source projects and to show their prowess as a means to attract the best talent. But large enterprises tend to be super secretive about their systems, and none more so than the major oil and gas companies.
But if you poke around a bit, you can learn a thing or two. The Next Platform is at the Rice Oil & Gas Workshop in Houston this week, and we did just that. No one, of course, can go on the record and those who are willing to provide insight get freaked out if you mention specific company names when talking about their HPC strategies. So you will have to accept the anonymity.
This time last year, when we attended the workshop, everybody was talking about how the price of a barrel of oil had dropped from around $110 from 2012 through 2014 and had dropped steadily until it was cut in half by March 2015. Prices rebounded a bit, but by June had resumed their fall and the price of a barrel of oil is now hovering around $36 a barrel this week. This is a very hard price cut for all oil companies to absorb, whether they are smaller operations doing hydrofracking or large companies drilling all over the world. The oversupply of oil in the global economy will attempt to right itself through the laws of supply and demand, although Saudi Arabia, which is flexing its reserves, seems intent on being the supplier that drives smaller players from the market so it can ride the inevitable price rise back up again to its own benefit.
These boom and bust cycles have characterized the oil and gas industry for the past century and a half, but computers have only been used in the search for hydrocarbon fuels for the past 60 years or so. The systems on which the major oil companies rely to chew through seismic data that reveals the inner structure of the Earth’s crust where oil and gas lurk and to manage their fields and therefore their fuel reservoirs are expensive and their software amongst the most complex and cranky ever created. The industry is more dependent on machines than ever before to mitigate the risk of drilling for oil and gas, which as we explain in our discussion of the HPC strategies at French oil giant Total, is very expensive indeed.
There is a temptation, we presume, to cut back drastically on IT costs when times get tough, but this is not really an option. Francois Alabert, vice president of geotechnology solutions at Total, gave the keynote at the workshop and flashed this fascinating chart up:
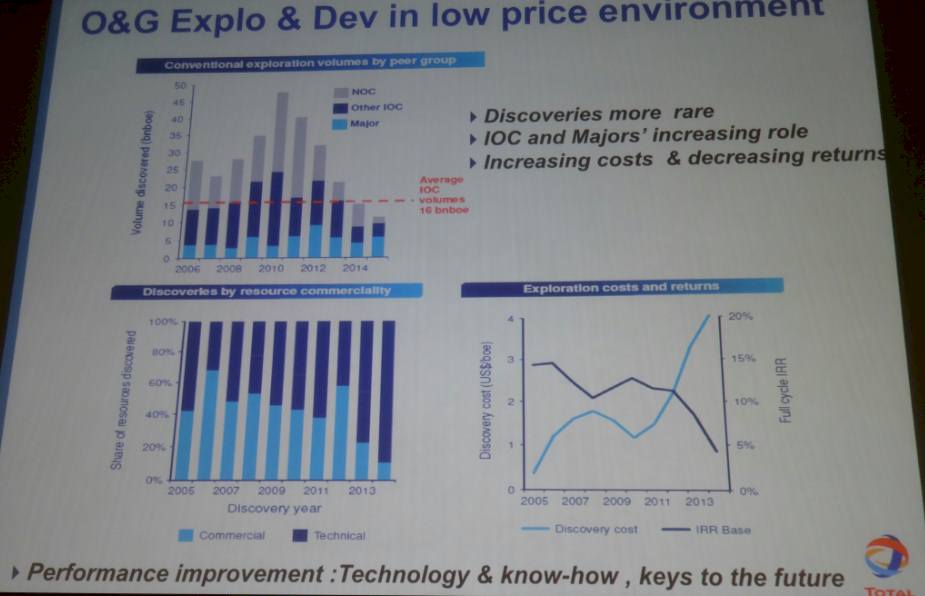
The cut and the dry of the situation is that Earth’s appetite for hydrocarbon fuels is not abating, and at the moment, about 30 billion barrels of oil equivalent are discovered each year but we are burning something on the order of 50 billion barrels. The oil industry is eating into its reserves. To make matters worse, the return on investment from exploration efforts is going down, not up, and there are many who believe that better simulation and modeling during both exploration and drilling will reduce the risks – and therefore the costs – of finding oil and getting it into production. Presumably at a later date when the price of a barrel of oil has risen. That’s the bet, anyway.
There is plenty of trepidation about the effect on IT spending in the oil and gas industry, since is it one of the big pillars in the HPC sector.
“We expect to see a decrease in HPC spending in the oil and gas exploration segment any time the price of oil is low, and this time shouldn’t be any different,” Addison Snell, CEO of market researcher Intersect360 Research, tells The Next Platform. “This is only natural, that companies would try to delay or decrease capital IT expenditures, especially if the tradeoff can preserve people’s jobs. However, spending doesn’t go to zero. Another effect of low oil prices is that efficiency becomes even more important. In environments like that, smart HPC usage can be even more important, and exploration has to continue to move forward.”
According to the people we spoke to at the workshop, the natural cycle of system upgrades, which is tied more or less to Intel’s processor cycles and to a lesser extent to the rhythms of the network equipment suppliers that provide the gear to lash servers into clusters, was already going to be a bit slow in 2016 anyway.
One of the big majors that has a datacenter in the Houston area did a $1 million proof of concept machine in 2014 and spent over $100 million on a system rollout last year. This is an exceptionally large deal, and was timed to the rollout and ramp of Intel’s “Haswell” Xeon E5 processors and 100 Gb/sec InfiniBand networking. Another big major spent $50 million to upgrade several of its server clusters, with the largest machine having around 3,600 nodes. These are hefty machines even by the standards of the major oil companies, sources tell us, and they tend to buy smaller clusters that cost on the order of $5 million to $25 million under normal circumstances. (You will never see such machines on the Top500 supercomputing rankings, and Total is unique among the majors in that it actually ran the LINPACK benchmarks on its Pangea system.) Like other large enterprises, many of them roll out a piece of their cluster every year and roll in new nodes with much faster gear. But in the two cases cited above, these expensive machines were apparently rolled in all at once, not piecemeal over three years.
Most of the majors use a mix of InfiniBand and Ethernet, and it is unclear what they are thinking about 25G Ethernet products or Intel’s Omni-Path follow-on to True Scale InfiniBand. Ditto for the next generation of “Pascal” GPU accelerators from Nvidia and the “Knights Landing” Xeon Phi accelerators and processors from Intel. The oil companies have a diverse set of code that has been tuned for the X86 architecture at this point, even if the code was running on Power, MIPS, Itanium, Sparc, or even FPGA or DSP architectures in the past. The majors play with every technology and they don’t like to talk about which ones they have committed to because, again, their hardware and the software they develop for seismic analysis and reservoir modeling is proprietary and integral to their success in the oil and gas fields.
The one thing that most of the majors do not do is use proprietary interconnects from Cray or SGI to build their systems. (The one exception that we know about that has been publicly stated is a Cray XE6 system that was deployed by ExxonMobil several years ago to handle its reservoir models and that uses Cray’s “Gemini” interconnect. We have no idea if this machine is still installed and operational.) For the most part the majors stick with standard networking and server parts as much as possible so they can pit vendors against each other and drive the price down. They are not at a scale like Google or Facebook where it makes sense to design their own machines and farm them out for manufacturing.
While many of them won’t talk about it, the majors took a shining to GPU acceleration and were early adopters of the technology, and we dug out this chart out of an Nvidia presentation from 2012 to prove it:
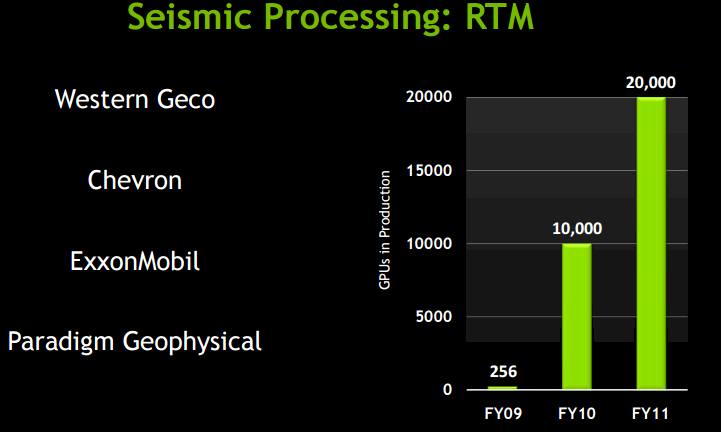
We presume that as more reservoir modeling code has been ported to GPUs that sales of Tesla coprocessors have continued to grow exponentially from the data shown above.
As far as the people we talked to at the Rice workshop know, all of the majors are using GPU accelerators in some form or another. Western GECO, which is now part of oil services giant Schlumberger, has a massive complex of clusters that all told weigh in at 40 petaflops, and we hear that it went in big for GPUs six years ago to help drive up the efficiency of the seismic processing that it does on behalf of the majors and other oil and gas companies. We also know that one of the majors has nodes that are cramming eight Tesla K80 GPUs into a single server node as part of its clusters.
With many of the majors having upgraded their systems in early 2015, and most of them on a three-year cycle for upgrading those systems, the following year and a half will be about planning for their next platforms. This is a good time for such planning, and the action this year will be mostly centered around proofs of concept as the major test out new compute and networking options. But as we had it explained to us, reservoir modeling is inherently dependent on memory bandwidth, and therefore the future Pascal Tesla and Knights Landing options are going to be interesting toys for the oil companies to play with. In fact, some reservoir modeling clusters at the majors have already downshifted from two-socket machines back to single-socket machines to get the compute and memory bandwidth numbers back closer in synch. (Just like Intel itself has done with its own clusters for running its electronic design automation software, by the way.)
It is hard to generalize, but here is what those in the know tell us about the engines that the majors prefer for their clusters. During last year’s upgrade cycle, the Haswell Xeon E5-2680 v3, which has twelve cores running at 2.5 GHz, was the most popular processor installed in clusters for the oil and gas majors; the Xeon E5-2690 v3, which also has a dozen cores but runs at 2.6 GHz and has a 30 MB cache, also saw some action. No one is going for the 14-core or 18-core Xeon parts, and the reason is simple: they cost three times as much to get that extra compute in the cores, and the bang for the buck does not make sense for the seismic analysis and reservoir modeling applications that the majors run. (It makes us wonder who does use these high end SKUs from Intel.) The typical server node at a major installed last year had 128 GB of main memory, which is not very much on machines that can scale to 768 GB, and in some cases they take the Xeon E5-2690 processors and pair it with 256 GB or 512 GB to make fat nodes for a portion of their workload where a little more compute, cache, and memory can speed things up.
No one we spoke to expected for 2016 to be a big year for spending among the oil and gas majors, and everyone said that they expected for a lot of testing and then big investments in late 2017, when a new wave of processors and interconnects would become available and could be put into systems in early 2018. Intel’s “Skylake” Xeon E5 v4 processors will be out then, for one thing, and so will be IBM’s Power9 processor and its companion “Volta” Tesla GPU accelerators from Nvidia and 200 Gb/sec InfiniBand interconnects from Mellanox Technologies.
This is also not coincidentally when a lot of the systems installed under leases by the majors in 2015 will be coming off lease. We were not aware that many of the majors lease rather than buy their machines, but this makes a certain amount of sense from a financial as well as a practical point of view for all companies, not just oil and gas majors. (We discussed the benefits of leasing rather than buying a supercomputer in a recent story.) The other interesting thing we learned is that a lot of the majors do not run their own datacenters, but in Houston at least they rent space from CyrusOne, which has four facilities in the Houston area catering to the needs of the industry.
In the end, maybe 2016 was going to be a boring year for investment for the oil and gas industry anyway, so it is good that the oil glut is hitting now rather than in 2017 or 2018. The issue is, what happens if energy prices fall further?


The Most Complex Chip Ever Made?
Historically Intel put all its cumulative chip knowledge to work advancing Moore’s Law and applying those learnings to its future CPUs. Today, some of those advanced processors are destined for the forthcoming “Aurora” supercomputer at Argonne National Laboratory. However, demanding simulation and modeling workloads also benefit significantly from GPU acceleration. …
Intel Puts Its Xe GPU Stakes In The Ground
For about a decade, Intel has sold GPUs, in recent years with its integrated CPU-GPU devices used in client and entry servers. But for the most part, at its heart and despite acquisitions of FPGA and NNP makers, Intel is still a CPU maker. Nvidia and AMD have for years …

Dell Tackles AI Infrastructure With Disaggregated Servers And Storage
It is funny how companies can find money – lots of money – when they think IT infrastructure spending can save them money, make them money, or do both at the same time. This is the hope with AI, and everyone is trying to benefit from it in those ways. …
Be the first to comment