

There is but a small cadre of scalable parallel file systems and while the list might be small, weighing the relative benefits of each option against the available resources can be a challenge, as Sven Breuner and his HPC admin colleagues at the Fraunhofer Institute realized in 2004.
They were certainly not the first or last organization to labor over the inevitable question of which of these scalable parallel file systems to choose, but they did take an interesting route. Notably, the limited choices have not changed over those years, either—nor have the list complaints about each.
To be more specific, despite less common options at scale (Gluster, Panasas, OrangeFS, and others) the HPC parallel file system camps are divided between Lustre and GPFS. But part of the challenge for the Fraunhofer team was that GPFS was too expensive, both that and Panasas required specialized hardware, and Lustre, despite its growing maturity then, still had some stability issues and scalability problems rooted in its single metadata server structure in those early days.
Frustrated with the lack of options, the Fraunhofer team did what anyone else armed with a phalanx of eager graduate students would do—they built their own.
“Aside from those things, what we really needed was a very high performance parallel file system, but one that didn’t take any dedicated staff to manage, which all of the others did,” Breuner tells us. Fast forward twelve years and their creation, BeeGFS, has managed to move from project status to the parallel file system of choice at a number of major supercomputing centers that make Top 500 grade, including clusters at the University of Vienna, the University of Frankfurt, and others on the list. The largest installation to date is at Vienna, where it is installed across over 2,000 nodes, but this is not the limit of its scalability—it simply hasn’t been tested on much larger systems.
To be fair, Breuner says that Lustre and GPFS certainly have their places. For instance, GPFS is well worth the cost when larger organizations or research centers are managing the entire lifecycle of data (i.e., moving data off to tape and around other systems) and Lustre, while bemoaned for its complexity, provides the robustness required at scale. While BeeGFS can scale well beyond that 2,000 node count, for smaller HPC sites without the people required to manage a weighty file system, something like BeeGFS looks quite attractive. For the years ahead, however, it might not only be for the lighter weight management and performance—for ARM HPC clusters, once they do emerge in more volume, BeeGFS might be the de facto standard, at least at first.
Although it is still early days, Breuner says that they are the only parallel file system offering support for ARM. This is not to say they have worked out all the kinks yet, however, although it is a research and development goal for the year that is just underway. With Lustre largely in the hands of Intel and partners, and IBM focused on GPFS and the future of Power, the opportunity for BeeGFS is clear—assuming, of course, there is sufficient demand and they can stay out front in terms of research.
“The fact that the CPUs are slower is a challenge for streaming throughput. The other thing is that people expect that ARM systems are energy efficient. Even though ARM CPUs can go to high clock frequencies now, they want to run lower on the clock, so we will be doing research to see how much clock frequency is needed to get a certain streaming throughput. For example, are all 48 cores needed to get great storage performance?”.
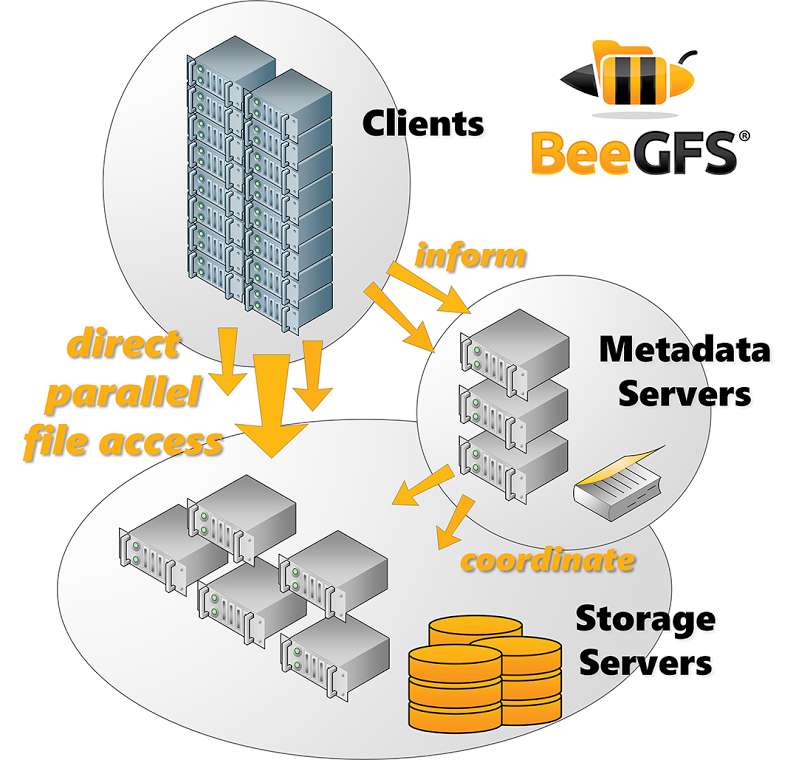 Despite the general architectural features between BeeGFS and Lustre, for example, the differences are more nuanced. For one thing, there is flexibility in their lighter weight approach. Users can run a converged setup, are not bound to a particular Linux distro, and can get easier views into what goes wrong—addressing a common Lustre complaint of cryptic Lustre log files and backtracking problems. “In some senses, BeeGFS is a drop-in replacement for Lustre,” Breuner says.
Despite the general architectural features between BeeGFS and Lustre, for example, the differences are more nuanced. For one thing, there is flexibility in their lighter weight approach. Users can run a converged setup, are not bound to a particular Linux distro, and can get easier views into what goes wrong—addressing a common Lustre complaint of cryptic Lustre log files and backtracking problems. “In some senses, BeeGFS is a drop-in replacement for Lustre,” Breuner says.
Although Breuner described other parallel file systems and their approaches, including other free or open source options like OrangeFS, Gluster, and even Ceph (which is not ready for HPC primetime, even though his team is working on building connectors to it), he says some of the core problems mentioned above, as well as other pesky issues with Lustre and GPFS around shared file writes, have been solved in BeeGFS. “We want to be a good scratch file system where performance is needed; no dedicated staff is required to hack the file system every day.”
In addition to its free license (with supported versions provided by linked company, ThinkParQ) BeeGFS is also available on demand where it can run on a per-job basis. For example, if a job is submitted to run on 100 nodes, the batch system brings up a BeeGFS instance using exactly these 100 nodes as servers and clients at the same time, which is valuable for sites with SSDs in their nodes. In essence, it gives an exclusive, fast parallel file system for the target job, which although temporary, is one way to leverage SSDs.
As of this week, BeeGFS is open source as well, something that has been a long time coming, even if it has remained free since the beginning. Breuner says there are 150 supported end users of BeeGFS and around a factor of ten larger for the free version, although those numbers are hard to track.


Blazing The Trail For Exascale Storage
When it comes to advanced technologies at the high end of compute, networking, and storage, Lawrence Livermore National Laboratory is one of the world’s pathfinding testbeds. Trying new things at scale is a big part of the mandate for the lab, which among other things, is the US Department of …

Divide Deepens Between HPC and Enterprise Storage
The more things change, the more they stay the same in HPC storage. But for the broader enterprise world, the more things stay the same, the quicker companies are to seek out change. As long as it’s easy to manage and provides reliability, cost is not at the top of …

Will DeltaFS Become the File System of Exascale’s Future?
Many have tried, but few parallel file system upstarts have challenge the dominance of Lustre, and to a lesser extent these days, GPFS/Spectrum Scale. It does not seem to be just a matter of open source versus proprietary, but tradition and function. And while both most-used file systems in HPC …
Be the first to comment