

As the needs for ever faster analytics on growing datasets continue to mount, the overwhelming number of projects, startups, and pushes from established companies to find new ways to process and manage data climb as well. While it can be difficult to sort and categorize these efforts, there are a few approaches that stand out.
Among these is a relatively small effort (in terms of the size of the team) that has some rather big backing, including the corporate support from companies like Facebook, Microsoft, Google, and Oracle Labs, which add financial backing to the existing National Science Foundation grant funds. The Next Platform is called Hyracks, and the goal is to provide an accessible data parallel runtime basis for large-scale data processing using standard clusters of shared-nothing commodity nodes.
Both of the leads behind the project, Dr. Mike Carey and Dr. Chen Li from UC Irvine have extensive backgrounds working with large-scale data platforms. Carey, for instance, was a database researcher and manager at IBM Almaden (in addition to various corporate chief architect and engineer roles) and Li is a former visiting research scientist at Google. Both have watched as the limitations of standard relational databases became apparent at scale, and both too witnessed the march of new tools and languages, all aimed at making analytics at large scale more robust—but at the same time, adding more complexity via variability.
While the Hyracks platform itself could command a much more in-depth piece, especially since there are multiple components, one more recently developed piece of the stack caught our eye here at The Next Platform. This layer is called Algebricks and it is aimed at condensing the many diverse tools that are part of the analytics stack into one via a compiler using a data model-agnostic approach. This sits on top of Hyracks which, at the high level, is a push-based data parallel runtime that is not unlike Hadoop and includes its own scheduler and libraries.
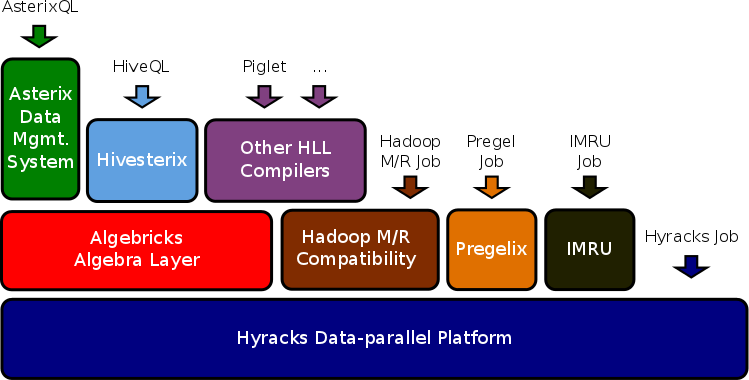
Put quite simply, there is no shortage of high-level query languages (Flume, Hive, Pig, Jaql, etc.) that are aimed at making the lives of data analysts simpler, but when it comes to seamlessly hopping between these or using them in a more condensed way, the options are limited. The team behind Hyracks and Algebricks says that for all of these languages, there is a complete data model-dependent query compiler even though many of the optimizations are similar. Accordingly, Algebricks extracts both halves—the language-specific and data model aspects from “a more general query compiler backend that can generate executable data-parallel programs for shared-nothing clusters and can be used to develop multiple languages with different data models.”
The team has shown how this can be implemented using HiveQL, AQL and XQuery, but they note that users are not limited to these tools. This can be extended to meet Spark and Tez, although the results from testing on these platforms has yet to be published. Still they were able to show how all three of the tested examples can benefit from the Algebricks parallelization and optimizations and “thus have good parallel speedup and scaleup characteristics for large datasets.”
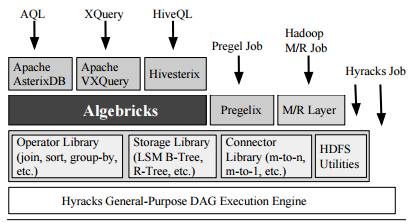 According to the Hyracks team members who spun out Algebricks, there is a definite need for a platform (within a platform in this case) that can be recycled to build different languages for large-scale data processing. The Algebricks effort has managed to do this by providing interfaces that can, as they describe, “be implemented by the developer of a high-level language to stitch in the data model specifics of the target high-level language.” This is tied to a rule-based rewriting tool that can carry over relevant information for the target language using the operators provided by Algebricks—the point is, the data model is separated.
According to the Hyracks team members who spun out Algebricks, there is a definite need for a platform (within a platform in this case) that can be recycled to build different languages for large-scale data processing. The Algebricks effort has managed to do this by providing interfaces that can, as they describe, “be implemented by the developer of a high-level language to stitch in the data model specifics of the target high-level language.” This is tied to a rule-based rewriting tool that can carry over relevant information for the target language using the operators provided by Algebricks—the point is, the data model is separated.
While there are only so many alternatives to Hadoop needed on the planet, and only so many approaches to addressing large-scale data, easing the flow between languages is a critical part of making the move toward large-scale data analysis more accessible for developers.


The Endless Pursuit Of Scale At LinkedIn
There is nothing at all wrong with legacy application and system software as long as it can deliver scalability, reliability, and performance. Changing from one software stack to another is so difficult and so risky — the proverbial changing of the front two tires on the car while going down …
The Opposite Of Snowflake: Analytics Without The Data Warehouse
As we have pointed out before, large enterprises have to deal with a different kind of scale issue than the hyperscalers, and in many ways, the hyperscalers have it easier. The hyperscalers have dozens of core applications that they have to run at massive data scale – pushing up to …

Getting Hadoop to Jump Through AI/ML Hoops
Just a decade ago, the enterprise IT push was to make Hadoop the platform for storage and analytics. At that time, cloud hesitancy was still looming for large on-prem organizations. Hadoop, no matter how that ecosystem played out over the years, became a major source of investment with the idea …
See “Abstraction without regret in database systems building: a manifesto” https://infoscience.epfl.ch/record/197359/files/preprint.pdf for further insights,
IMHO machine learning needs a powerful programming model but better it be based on
– functional programming
– algebraic data types
allow for distribution of both computation & data and for domain/application specific optimizations.
Without being stuck in a database.