
The computational capability of modern supercomputers, matched with the data handling abilities of the Hadoop framework, when done efficiently, creates a best of both worlds opportunity. This pairing is happening as traditional high performance computing (HPC) struggles with unprecedented volumes of data that are not always well suited for HPC architectures–and as the Hadoop ecosystem enters a golden age of maturity.
There have been numerous attempts on the systems software side to create tools that make using both HPC and data-intensive applications work well on the same cluster, but it is still early days on that front. Hadoop and HPC, while tied together with the thread of some common needs, are not exactly peas in a pod. The distinct architectural differences between the two creates big challenges when it comes to integrating the use of both on the same cluster resource.
In other words, to provide the ability for HPC centers to use Hadoop without setting up a separate cluster (and incurring separate acquisition and management overhead) takes some special blending of what both architectures offer. This, according to a team at HPC Wales, is something that can be done efficiently by building up a YARN-based cluster that can manage both traditional HPC and “big data” workloads.
“Hadoop and HPC workloads share common high-level goals—to ensure the optimal distribution of computation across all the available compute resources while minimizing the overhead caused by I/O,” the HPC Wales team says in a recent paper that outlines their approach and provides Terasort benchmark results to validate their strategy.As the group highlights in the graphic below, there are significant differences in how both HPC and data-intensive computing approaches address the need for high utilization of available compute.
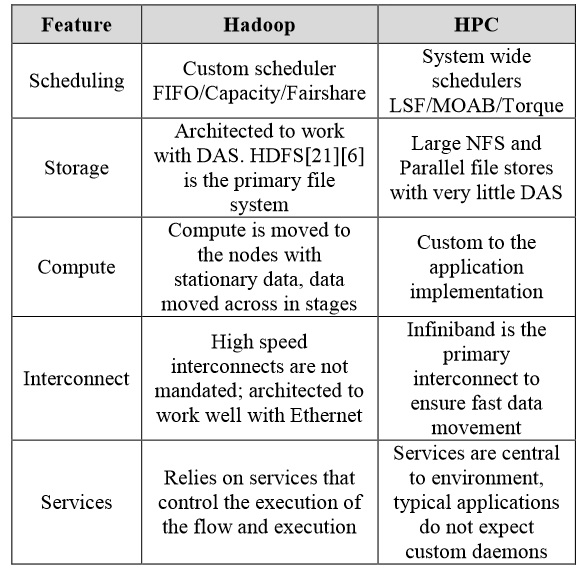
Even though there are common performance and capability goals for HPC and data-intensive jobs, the way HPC and Hadoop achieve these ends is quite different, with HPC focusing on the use of both hardware and interconnects and Hadoop’s reliance on its internal file system (HDFS and other variants) and the way it operates on the data.
With this in mind, the team had to balance the needs of both HPC and data-intensive applications and leverage or diminish the features of both HPC and Hadoop frameworks accordingly, depending on workload. The ultimate unified platform they build includes the expected data-intensive tools (Hive, MongoDB, Pig, Hive, etc.) that work seamlessly when stitched together with YARN. These can then be hooked into traditional HPC applications that use things outside the typical big data set, including MP, OpenMP, and CUDA. For this platform, and in harmony with the YARN work, the management is handled with IBM Platform LSF. It is notable as well that the backend file system of choice on the team’s cluster is Lustre.
Ultimately, the scalability of the dataset was as good as they expected, but the bottleneck cropped up around I/O performance that the team says can be tuned by refining key parameters inside both Lustre and the Infiniband network. The performance, according to HPC Wales, was “modest” and while a good base for future efforts, they also need to target how they are using containers for some of the HPC workloads as well as expanding the APIs for users to tap into various capabilities in the system.
HPC Wales is home to the UK’s largest general purpose supercomputing source. With around 17,000 cores available for research and industry on the Fujitsu SynfiniWay systems and many hundreds of users, it is critical for the center to be able to support expanding application areas. Among these is certainly the broad class of data-intensive applications, something the HPC Wales intends to push in their continued development of pushing HPC and Hadoop together with the existing research and benchmarking efforts.


Why the Fortune 500 is (Just) Finally Dumping Hadoop
Remember how, just a decade ago, Hadoop was the cure to all the world’s large-scale enterprise IT problems? And how companies like Cloudera dominated the scene, swallowing competitors including Hortonworks? Oh, and the endless use cases about incredible performance and cost savings and the whole ecosystem of spin-off Apache tools …

The Supercomputing Efficiency Curve Bends In The Right Direction
Things get a little wonky at exascale and hyperscale. Things that don’t matter quite as much at enterprise scale, such as the cost or the performance per watt or the performance per dollar per watt for a system or a cluster, end up dominating the buying decisions. The main reason …

Intel Targets DAOS Object Storage At More Than HPC
Intel is looking to position itself as a leader in AI and HPC through a holistic approach that plays to the company’s strengths across a broad swath of the IT ecosystem. This covers not just silicon hardware such as CPUs and ASICs, but also the firm’s expertise in open software …
Be the first to comment