

As we have seen with gathering force, ARM is making a solid bid for datacenters of the future. However, a key feature of many serer farms that will be looking exploit the energy efficiency benefits of 64-bit ARM is the ability to maintain performance in a virtualized environment.
Neither X86 or ARM were built with virtualization in mind, which meant an uphill battle for Intel to build hardware support for hypervisors into its chips. VMware led the charge here beginning in the late 1990s, and over time, Intel made it its business to ensure an ability to support several different hypervisors. For ARM, the challenges of virtualization across several hypervisors are still relatively new (compared to Intel’s early start in this area), but there has been a great deal of work to ensure comparable virtualization performance to X86 over the last few years.
According to Christoffer Dall, an early pioneer in virtualization research with an emphasis on the ARM architecture, everything you’ve heard about inferior virtualized performance on ARM should be taken with a grain of salt, especially when it comes to KVM. While there is some validity to KVM’s reputation on ARM as lackluster, this is not a generalizable truth–it is more nuanced, at least as some benchmarks have shown.
ARM builds their virtualization support in hardware similar to X86, but the way these approaches are architected are quite different. “ARM virtualization support for running hypervisors is designed to favor one hypervisor over another and ARM clearly favors the Xen way of doing things. It’s almost like it was built for Xen specifically,” he says. Getting KVM to work on ARM was a major hurdle, Dall adds, and even with the additions for virtualization support in ARM v.8, one still has to look at the performance between hypervisors.
With that said, Dall says many people have the vague opinion that ARM doesn’t perform as well with hypervisors as Intel, but in recent research highlighting these differences, it becomes clear that there are some obvious bottlenecks that can and have been broken. For instance, the biggest bottleneck, which can most simply be described as exiting a virtual machine (a common operation) has been where much of the performance overhead has been incurred. This transition time can vary 4X faster or slower depending on the architecture/hypervisor combination and at scale, can lead to massive traffic jams performance-wise when such transitions are part of a workload.
Dall is now at Columbia University where he is keeping with his research focus following stints at VMware (and now as the technical lead for Linaro, an ARM industry group). He is also the original author and current maintainer of KVM on ARM efforts. In the absence of any objective analysis of real performance of ARM versus X86 on various hypervisors, Dall and his Columbia team have published benchmark and other results to highlight how ARM is not as far behind on the virtualization support front than popular opinion might suggest.
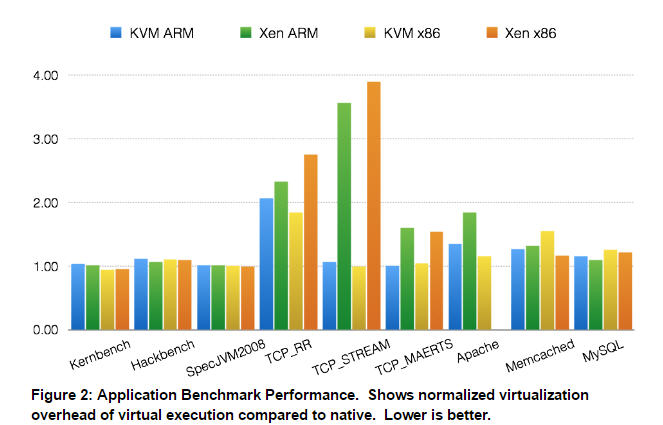
Among the team’s peer-reviewed findings (noteworthy because of Dall’s investment in KVM on ARM) they found that the overall hypercall (the bottleneck-inducing transition/overhead) of KVM on ARM cost 6,500 cycles while Xen on ARM cost only 376 cycles. Before that raises too many eyebrows, remember that there are new improvements to the ARM architecture, including the Virtualization Host Extensions (VHE) which might allow KVM (and similarly built hypervisors) to lower that cost.
“ARM can be four times faster than Intel for Xeon but up to four times slower for KVM, which is extreme, or that is the intuitive premise everyone had been describing for ARM hypervisor performance,” Dall says. “We have concluded that in the real world, with actual application benchmarks, it doesn’t look like this at all–in these benchmarks, KVM on ARM turns out to be faster than Xen on ARM. Overall ARM and X86 are on par with each other in terms of virtualization overhead,” Dall notes.


Arm Aligns Its Server Ambitions To Those Of Its Partners
There are just two Arm-powered supercomputers on the latest TOP500 rankings: the “Astra” system at Sandia National Laboratories and Fujitsu’s new A64FX prototype. The latter captured the number one spot on the Green500 list, becoming the first non-accelerated system to do so since 2012. There are also a handful of …

For Arm-Driven Supercomputing, Nvidia is Right on Time
While Marvell’s ThunderX family of server-class processors might not have taken high performance computing by storm from the outset, where there was interest and demand, it was fierce and committed. Luckily, all that effort on optimizing Arm-based architectures for HPC isn’t lost, and in fact, it might have a better …

Qualcomm Probably Not Pursuing Arm Servers With Nuvia Purchase
Hot on the heels of our overview of the state of the Arm server CPU landscape yesterday, chip maker Qualcomm, which dabbled in Arm server chips a few years back, announced that it was acquiring startup Nuvia for its Arm chips and design team. But don’t get all excited about …
Who is this ARM, as there are many custom designed cores engineered to run the ARMv8A ISA. I would like to see the actual custom and ARM holdings reference design cores listed, as the underlying custom micro-architectures that are engineered to run the ARMv8A ISA may very well be doing things differently. AMD’s x86 32/64 bit ISA implementation is different from Intel’s x86 32/64 bit ISA implementation with respect to some differences in each maker’s underlying micro-architectures with Intel’s cores being SMT enabled, and AMD’s current SKU’s lacking in any SMT capabilities until the Zen designs are on the market .
What about the differences in any server based SKUs that may be using a custom micro-architecture that is engineered to run the ARMv8A ISA. And in addition to that will there be any custom ARMv8A running micro-architecture that have SMT capabilities that will show better CPU core execution resources utilization and be able to have better throughput for any virtualization instructions that may benefit from SMT. I would rather see the custom ARM server cores listed individually, as well as any makers’ designs that utilize the ARM Holdings reference design cores that both run the ARMv8A 32/64 ISA. There has to be differences just as there are between AMD’s and Intel’s x86 32/64 bit ISA micro-architectures that run the X86 32/64 bit ISA.
I do hope that AMD still has plans for its custom K12 Arm cores in the server market once Zen is released to the market, and there needs to be as much comparison of the among the various custom ARMv8A running designs that have their makers own custom micro-architectures that are engineered to run the ARMv8A ISA as the is between AMD’s and Intel’s respective X86 32/64 bit micro-architectures that are engineered to run that X86 32/64 bit ISA.
There really is no singular ARM to speak of as quite a bit of completely custom micro-architectures are now available that can run the ARMv8A ISA, and there will be more of that in the future, in addition to any designs that use the off the design shelf Arm Holdings reference designs. Maybe SoftBank will help with more development financing for it ARM Holdings(Now in the held by Soft Bank) to field and even wider order superscalar ARM holdings reference design with some SMT capabilities more towards the Power8 end of the RISC spectrum, and I am very interested in what AMD’s custom K12 micro-architecture may bring to the ARMv8A ISA running server market(SMT, and other features maybe).
Why are they comparing against a 4 year old Xeon? It would be much more interesting to see a comparison between the most recent designs for both architectures.
Up to 4 DDR memory channels for octa xGene 2 and 3 for octa E5 2400 Sandy or Ivy?
In HP MS system that with many cartridges becomes interconnect bandwidth limited?
I agree an up to date platform comparison is useful. But have no objection with v8 comparison to 2600 v2 and v3 as there is so much Ivy and Haswell surplus sitting in channels eyed by enterprise on application utilities of price : performance which v8 can be competitive.
Not everyone buys newest E5 Broadwell’s from Intel price maker when the open market is ripe for v2 and v3 price taking fit for application use.
Mike Bruzzone, Camp Marketing
Point of fact : There are no demonstrated “energy efficiency benefits of 64-bit ARM” … quite the opposite in fact as demonstrated here.
http://www.anandtech.com/show/9956/the-silver-lining-of-the-late-amd-opteron-a1100-arrival
It is a myth conjured up by people with ARM based smartphones that can’t bring themselves to believe their chosen toy isn’t the little bundle of energy-efficient goodness that their self-esteem demands (even if they do have to charge it every day).
Its is also a convenient “false promise” used to sucker investors and governments into funding dubious research projects.