

If the hyperscalers are masters of anything, it is driving scale up and driving costs down so that a new type of information technology can be cheap enough so it can be widely deployed.
The hyperscalers have invented so many new technologies that are synonymous with the second and third wave of the commercial Internet – and many of them were invented first at Google. This stands to reason because Google was the first one to reach hyperscale, and things started breaking for Google first.
Let’s rattle a few of them off for fun, and then get into what Google revealed about its AI inference pressures and innovations at the AI Infra Summit in Santa Clara last week.
The company invented the “BackRub” back-linked style of search engine that transformed the Internet, which made it the de facto search engine for two decades. Then came the Google File System in 2003, followed by the MapReduce method of chunking up and parallel processing what came to be known as “big data” in 2004. (MapReduce was cloned and commercialized as Hadoop.) At the same time, Google created, used, and evolved the Borg and Omega cluster management and container systems that were open sourced (in part) by Google itself as Kubernetes in 2014. For data management and processing at scale, Google created the Bigtable NoSQL database in 2006, the Dremel and BigQuery relational database and the global-scale Colossus successor to GFS in 2010, the Spanner relational database layer that rides on top of it in 2012. Google launched the Dataflow kicker to MapReduce (to do streaming in addition to and rather than just batch processing) in 2014. And, significantly, the company has created custom Tensor Processing Units (TPUs) for AI training and inference concurrent with inventing and improving the transformer large language model that is at the heart of the GenAI revolution.
These days, everything feeds into AI and AI feeds into everything, and Google has transformed BigQuery into the core of its data platform to serve up data its Gemini and Gemma transformer models for internal use as well as for API services for Google Cloud customers. These models are trained on and deliver inference through Google’s fleet of TPUs, which must be huge indeed. Look at the chart that Mark Lohmeyer, general manager of AI and computing infrastructure at Google, showed during his keynote at AI Infra Summit:
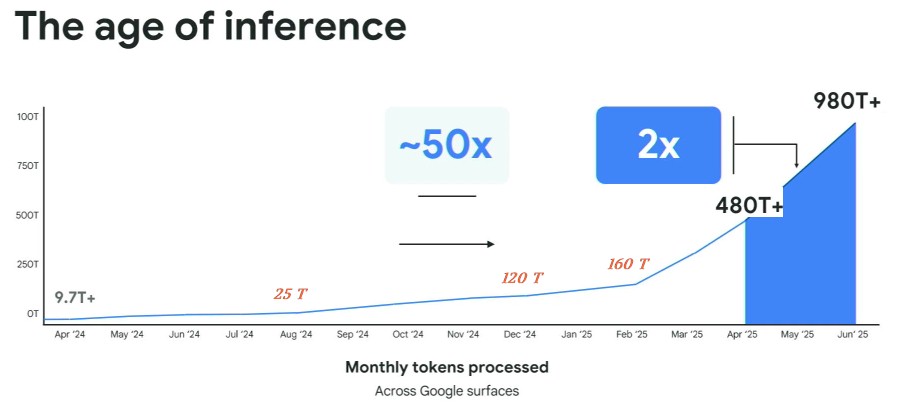
You can see the rate of inference across all Google products that the company has to serve has gone exponential. We have put the Google inference rates above the months they are related to; the original chart had them offset to the left, which was good for formatting but bad for accuracy. We also added in numbers for datapoints where the inference rates changed significantly, shown in red italics.
The inference token rate bent up in August 2024, when it hit 25 trillion tokens per month by our estimation, then steepened again in December 2024, when it hit 160 trillion tokens per month. In February 2025, the token rate across Google apps started to skyrocket, hitting 160 trillion tokens per month, and then went even steeper in April 2025 at more than 480 trillion tokens per second. The token rate was 9.7 trillion tokens in April 2024, and grew by 49.5X through April 2025, which very likely puts a strain on any business model and IT infrastructure fleet. But then again, it doubled to 980 trillion tokens per month by June 2025, and if the curve doesn’t bend at all, it will have risen to 1,160 trillion tokens per month in August 2025. Our guess it has accelerated a little more and Google’s internal inference rate for its apps was closer to 1,460 trillion tokens per month in August.
It is hard to guess how many TPUs might be driving that rate, given our lack of knowledge about text or video or image data that is being contexted and generated or the models being used. On the MLPerf inference test, a “Trillium” TPU v6e generated about 800 tokens per second on a Llama 2 70B model. That works out to about 2.07 billion tokens per month per Trillium TPU. If Llama 2 70B was the only model and MLPerf datacenter inference was the only workload, that would work out to a fleet of 704,090 Trillium equivalents in August if our very rough guess is right, and only 4,678 Trillium equivalents for the token rate just for inference in April 2024. Google still has TPU v5 and TPU v5e gear in its fleet as well as a growing installation of its new “Ironwood” TPU v7p machinery, which we detailed back in April and which we compared to the big AI supercomputers that have been installed around the world as well.

Lohmeyer did not divulge much new about the Ironwood systems, but did make a few comments that are interesting.
First, in addition to supporting the JAX AI framework, native PyTorch is now supported on TPUs. Google AI researchers now seem to prefer JAX over TensorFlow, which is used to support most production workloads at Google (so we hear). JAX is an AI framework that runs on Python and that Google, Nvidia, and others develop together.
The thing to process is that Ironwood has 5X the peak performance and 6X the HBM memory capacity of the Trillium systems it will eventually replace. And more importantly, an Ironwood cluster linked with Google’s absolutely unique optical circuit switch (OCS) interconnect can bring to bear 9,216 Ironwood TPUs with a combined 1.77 PB of HBM memory capacity on training and inference workloads. This makes a rackscale Nvidia system based on 144 “Blackwell” GPU chiplets with an aggregate of 20.7 TB of HBM memory look like a joke. (But not one that AMD or Intel can laugh at because they are still stuck down in eight-way nodes.) That OCS interconnect, Lohmeyer explained, has dynamic reconfiguration capabilities and can heal around TPU failures without having to restart entire training and inference jobs. This latter bit is huge.
So is liquid cooling, which Lohmeyer talked a bit about in his keynote:
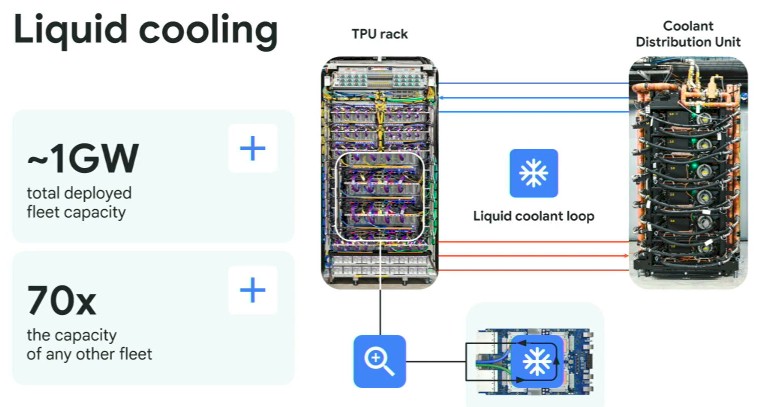
“Google has been working on liquid pooling since 2014,” Lohmeyer explained. “And we are now in our fifth generation cooling distribution unit, and we are planning to distribute that spec to the Open Compute Project later this year. To give you a rough idea of the scale here, as of 2024, we had around a gigawatt of total liquid cooled capacity, which was 70 times more than any other fleet at that point in time. We created this first for TPUs and now we will replicate it for a GPUs.”
(We are working on a deep dive into liquid cooling for XPU racks. Stay tuned.)
The feature image at the top of this story shows a system board with four Ironwood TPUs, and the Ironwood chart above shows a row of seven Ironwood TPU racks with one CDU per row and one networking rack per row. This is the first time Google has showed a row of the Ironwood machinery.
We stared at this for a bit, and it bothered us.
When we count, seven racks of iron with 16 systems per rack, with four TPUs per system, is 448 TPUs per row, not the 256 that we expected. The 256 TPU count is equivalent to a base pod, which has a 3D torus interconnect linking each TPU to all of the others in the pod. We know that the full-on Ironwood system, which is also called a pod for some reason, has 144 racks with a total of 9,216 TPU v7e accelerators. So that means this full-on machine has 36 pods interlinked in a 4D torus.
It is very odd that this is not an eight TPU rack setup per row, which would mean two base pods per row. We think this means that there are three pods for every two rows, with a rack per row used as redundant, hot spare TPUs. That would mean that a full physical Ironwood system has 10,752 TPU v7e devices across 168 racks across 24 rows, with 1,536 TPU spares. The spares, of course, could be interleaved across the full seven racks in each of the 24 rows, and we strongly suspect this is the case.
Google may use TPUs for most of its internal workloads, but as a cloud builder, it also has to have large fleets of GPU-accelerated systems and particularly those based on Nvidia GPUs, which are the industry standard. And it does, and Lohmeyer was sure to point this out. In fact, Google calls the hybrid approach to compute, networking, and storage embodied on Google Cloud the “AI hypercomputer,” and pointed out that Google Cloud had compute instances based on the Blackwell RTX 6000 Pro (G4) as well as eight-way B200 nodes (A4) and 72-way B200 rackscale nodes (A4X). The GB300 NVL72 is the one really aimed at lowering the cost of inference, and that was not on the Google Cloud instance list – yet. Lohmeyer also made a point that Nvidia’s Dynamo inference application – Nvidia is calling it an operating system, but we are not – has been added as an option for the custom inference stack on Google Cloud.
We strongly suspect that Google prefers to use its own inference stack, which Lohmeyer walked everyone through but we also do not know if the Google inference stack works on anything other than its own TPUs. (Given its history of porting things to multiple architectures, if that Google inference stack has not been ported to both Nvidia and AMD GPUs, we would be surprised. It may be a work in progress.
Here is what it looks like:
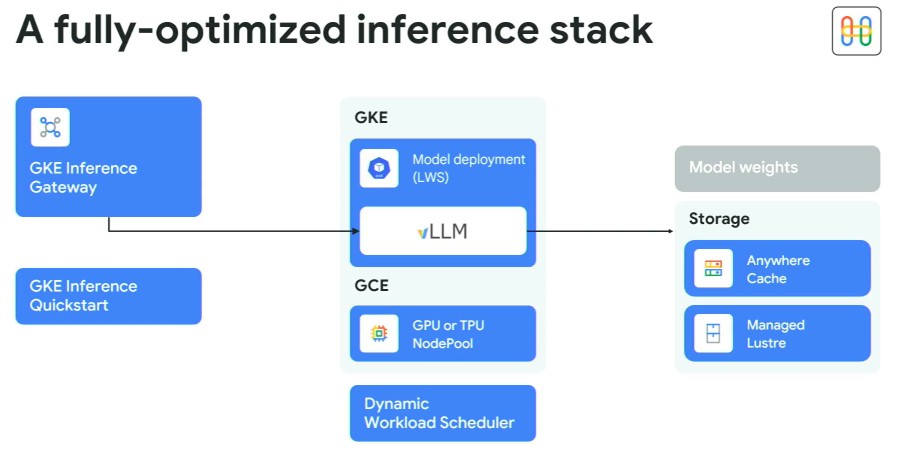
GKE is the managed Kubernetes container service on Google Cloud, and is analogous to the internally used Borg and Omega controllers. vLLM is at the heart of this inference stack, as it is with Dynamo.
The service is back-ended with a caching service called Anywhere Cache, which is a new flash memory caching service that acts as a front end to the various Google storage services. Lohmeyer says that Anywhere Cache can boost cut read latencies by 70 percent within a Google Cloud region and by 96 percent across multiple regions. (He did not say what those latencies are, but we suspect they get a lot longer the further you are away.) The caching can also be used to lower networking costs because once the data is cached you are not going across the network to get data. The Managed Lustre service is a high performance file system for feeding data into the GPU and TPU clusters.
The GKE Inference Gateway is new and uses AI-infused load balancing and routing to spread inference requests across pools of compute engines. The idea is to not let stuff queue up in the first place so utilization can be driven higher.
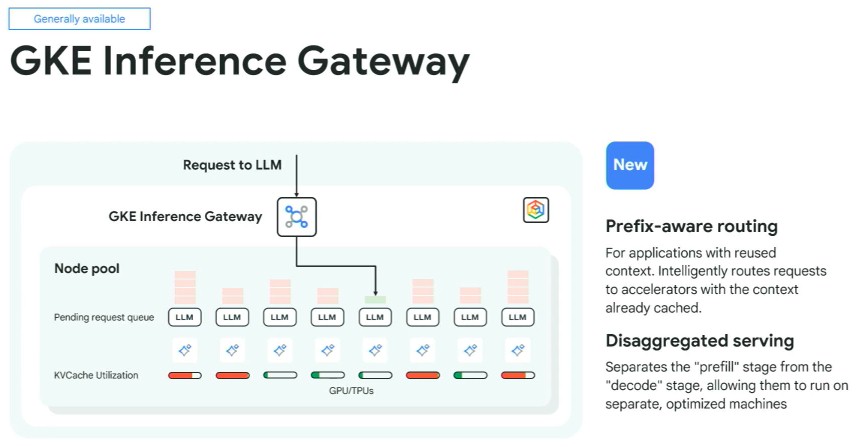
One way to do this is to have a router sitting on the front end of the pool of XPUs and find a device that already has the context you need in its memory. As we have seen in Nvidia’s announcement last week of the “Rubin CPX” GPU accelerator, which is aimed at processing long context queries, Google’s gateway breaks the “prefill” context processing stage from the “decode” query response stage so they can be done on compute engines optimized for each task.
Figuring out what those configurations should be for different parts of the inference hardware and software stack is a daunting task, and so Google has created the GKE Inference Quickstart tool, which is also new and now generally available:

Google struggles with all of these parameters internally, and is fully aware that decisions made early can be made wrongly with dire consequences for the economics of inference.
Taken together, Lohmeyer says that customers on Google Cloud can lower their inference latency by as much as 96 percent, drive throughput up to 40 percent higher, and cut the cost of a token chewed on or spit out by up to 30 percent.
Lohmeyer also showed off another technology called speculative decoding, which it has used to boost the performance of its Gemini model and drop its energy consumption by around 33x:
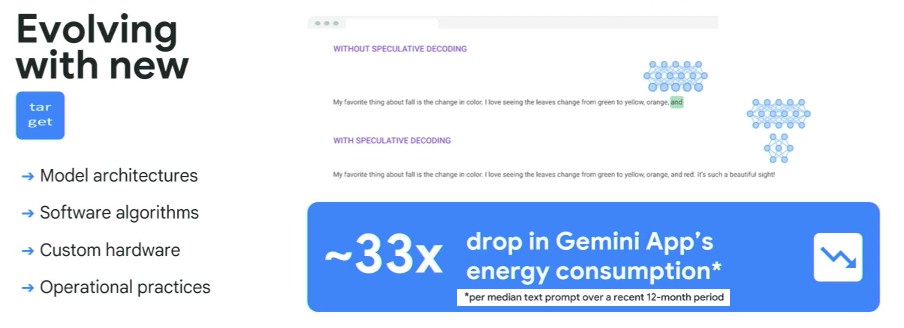
At these prices, all those percentages are real money, and that 33X could be absolutely huge since power budget is inversely proportional to profits in this inference racket. We need to find out more about this.

Ampere Arm Server CPUs To Get 512 Cores, AI Accelerator
With all of the hyperscalers and major cloud builders designing their own CPUs and AI accelerators, the heat is on those who sell compute engines to these companies. That includes Intel, AMD, and Nvidia, of course. And it also includes Arm server chip upstart Ampere Computing, which is taking them …
One Laser To Pump Up AI Interconnect Bandwidth By 10X
According to rumors, Nvidia is not expected to deliver optical interconnects for its GPU memory-lashing NVLink protocol until the “Rubin Ultra” GPU compute engine in 2027. And what that means is that everyone designing an accelerator – particularly the ones being designed in house by the hyperscalers and cloud builders …
Intel Takes The Big Restructuring Hits As It Looks Ahead
It is beginning to look like chip maker Intel hit the bottom in its products and foundry businesses in the second quarter of this year and that revenues are slowly – we won’t go so far as to say surely – improving. But now the restructuring charges and cost cutting …
Be the first to comment