

SPONSORED FEATURE: Back before there were AI factories, there were two generations of the AI Bridging Cloud Infrastructure supercomputer, built by the National Institute of Advanced Industrial Science and Technology (AIST) in Japan. AIST created what is arguably the first AI factory, merging accelerated computing platforms with cloud infrastructure software to forge a shared utility for researchers in Japan to do AI experiments.
Way back in March 2017, when the AIST AI Cloud (AAIC) prototype for the ABCI supercomputer was built by NEC for the lab, GPU accelerated computing that was fungible and rentable was not yet common in Japan, and indeed, was not widely available even on the larger clouds built in North America, Europe, and China.
The AAIC machine had 50 two-socket “Broadwell” Xeon E5 v4 nodes, each with eight NVIDIA “Pascal” P100 SXM GPU accelerators. The AAIC machine had 4 PB of clustered disk storage from DataDirect Networks running IBM’s GPFS file system, and used 100 Gb/sec EDR InfiniBand director switches to glue them all together.
The AI cloud concept was proved out on a variety of AI and data analytics workloads, and a much larger pool of funding was put together to build something that had sufficient scale to do heavier AI research.
After competitive bidding, AIST tapped system maker Fujitsu in October 2017 to create ABCI 1.0, a supercomputer that was in essence the world’s first AI factory – a term that NVIDIA has coined to talk about production-level, cloud-style AI clusters at scale. ABCI 1.0 is also an example of what people now talk about as “sovereign AI,” by which is meant AI aimed at bolstering the capabilities of nation-states that do not want to depend solely on the hyperscalers and cloud builders for their AI compute capacity.
The cost of the ABCI 1.0 machine was ¥5 billion. A new datacenter was built to house the ABCI 1.0 machine at the Kashiwa II campus of the University of Tokyo.
It was fitting that the ABCI 1.0 machine was based on server sled designs first created by hyperscalers and cloud builders to drive up the density of their infrastructure. ABCI 1.0 had 1,088 of Fujitsu’s Primergy CX2570 server nodes, which are half-width server sleds that slide into the Primergy CX400 2U chassis. Each sled had two Intel “Skylake” Xeon SP processors and four of the Nvidia “Volta” V100 SXM2 GPU accelerators. 2,176 CPU sockets and 4,352 GPU sockets. The Volta GPUs were the first to offer 16-bit half-precision tensor core units on the GPUs, which radically boosted their AI training and inference performance compared to the P100 GPUs used in the AAIC prototype.
ABCI 1.0 system had two EDR InfiniBand ports running at 200 Gb/sec, all linked in a three-tier fat tree with 3:1 oversubscription.
The ABCI 1.0 system was operational in August 2018, and included an amalgam of software that came from the HPC community as well as hyperscalers and cloud builders, as you might expect. The system supports Singularity and Docker containers to package up applications and manage them concurrently for diverse workloads and many users running simultaneously. The ABCI stack, which is always evolving and changing as AI research itself evolves, included:
- The Lustre and GPFS parallel file systems
- The BeeGFS, BeeOND file systems
- The Scality RING object storage
- The Altair GridEngine job scheduler
- The Apache Hadoop
- The MPI, OpenMP, OpenACC, CUDA, and OpenCL parallel programming environments, notably including NVIDIA NCCL and Intel MPI
- Various programming languages, and other tools, with Python, Ruby, R, Java, Scala, Go, Julia. and Perl being important along with Jupyter notebooks
- The spack package manager
- The Open OnDemand web interface for supercomputers
- A slew of machine learning libraries, and AI frameworks
In May 2021, AIST adding an extension onto the ABCI 1.0 cluster, called ABCI 2.0 of course, that added 120 nodes based on Fujitsu’s Primergy GX2570-M6 servers. The ABCI nodes used a pair of Intel’s “Icelake” Xeon SP processors and Nvidia Quantum 200 Gb/sec InfiniBand interconnects (four per node) to lash the nodes (each with eight Nvidia “Ampere” A100 SXM4 GPUs) to each other. The InfiniBand interconnect was a two-tier network with full bi-section bandwidth in a fat tree topology.
Here is a block diagram of the ABCI 1.0 and ABCI 2.0 machines:

The ABCI 2.0 extension cost ¥2 billion. With the upgrade, the resulting cluster was boosted to 56.2 petaflops at FP64 precision, 224.4 petaflops at FP32 precision, and 850 petaflops at FP16 precision. This represented more than a 50 percent boost in performance for about 40 percent more budget. Interestingly, the Singularity container platform created for the HPC crowd was added to the ABCI software stack with the 2.0 extension. Singularity supports NVIDIA inference tools deployed in NIM formats, which is important for ease of use.
The new ABCI 3.0 system, which is a brand new cluster and not an extension of the ABCI 1.0/ABCI 2.0 hybrid, was announced in July 2024 and has been operational since January of this year. This time around, Hewlett Packard Enterprise won the contract.
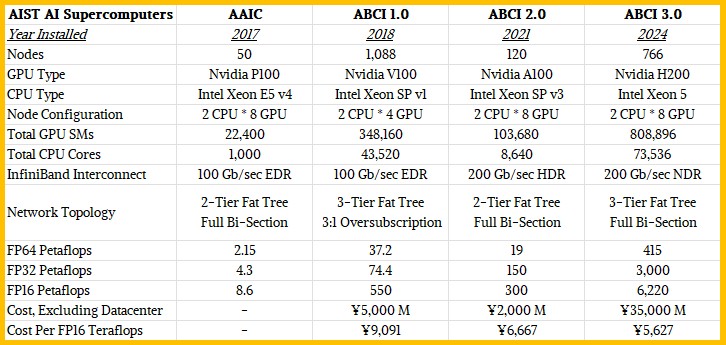
The AI supercomputer system is based on HPE’s Cray XD670 server platform, and in this case has a pair of “Emerald Rapids” Xeon 5 processors with 48 cores each, coupled to eight Nvidia “Hopper” H200 SXM5 GPU accelerators from NVIDIA. The H200 GPUs have 141 GB of HBM3e, which delivers 4.8 TB/sec of memory bandwidth. Both the memory capacity and the memory bandwidth are important for AI workloads. And so is the fact that, with that extra memory and bandwidth, the Hopper GPU can get closer to its peak theoretical performance on real workloads than prior H100s could, which had 80 GB or 96 GB of HBM3 memory and either 3.35 TB/sec or 3.9 TB/sec of memory bandwidth.
There are 766 Cray XD670 nodes in the ABCI 3.0 system, while the 6,128 GPUs in the ABCI 3.0 system are linked by 200 Gb/sec NDR Quantum InfiniBand interconnects. There is one 200 Gb/sec port for each GPU, and they are cross-connected by a three-tier, full bi-section bandwidth fat tree InfiniBand network. An additional 100 Gb/sec HDR InfiniBand port is in each node for host communication and management.
The ABCI 3.0 cluster cost ¥35 billion, which is the cost of a high-end HPC or AI system these days. The ABCI machine is rated at 415 petaflops at FP64 precision, 3.0 exaflops at FP32 precision, and 6.22 exaflops at FP16 precision.

The ABCI 3.0 machine offers better price/performance than the combined ABCI 1.0 and ABCI 2.0 machines, with 7.4X more FP64 oomph, 13.4X more FP32 oomph, and 7.3X more FP16 oomph. The ABCI 3.0 machine cost 5X to build as the combined ABCI 1.0 and ABCI 2.0 machines, but delivered 31.7 percent better bang for the buck on the FP16 work that is critical for AI workloads.
Perhaps most interestingly, AIST’s mission with the ABCI machines has changed with the times just as its hardware configurations have moved ahead.
“In Japan in 2017, despite strong interest from the industry, AI adoption was not progressing as expected,” Ryousei Takano, deputy leader at AIST, tells The Next Platform. “There was no place where large-scale AI experiments could be carried out effectively. Providing AI infrastructure for everyone was our strong motivation for creating the ABCI 1.0. Over the years, the landscape has changed, with domestic commercial cloud providers, such as Sakura Internet, Softbank, KDDI, and GMO Internet, now offering AI datacenters. We believe that our role also needs to be reconsidered. With ABCI 3.0, the resources are primarily allocated to public and strategic R&D purposes, especially national institutions, universities and startups.” “By sharing and transferring our experience with domestic cloud providers, we aim to help them become more competitive in the AI datacenter market.”
The ABCI systems serve a diverse user base of approximately 3,000 users, ranging from AI startups to large electronics manufacturers. The primary use case is training AI models, of course, notably large language models. The LLM Building Support Program was launched by AIST in August 2023, and has facilitated the development of state-of-the-art Japanese LLMs such as PLaMo and Swallow.
“As a next step, we want to use ABCI to support the realization of a cyber-physical system, or physical AI, in which the real world is sensed, the data is analyzed and simulated using AI technology, and the results are fed back to the robot,” explains Takano.
As you might imagine, AIST is looking forward to seeing how it might reduce the precision of its models down to the FP8 quarter-precision floating point format that is inherent in the Hopper GPUs.
Looking ahead, there is no definitive plan to upgrade to ABCI 4.0 – not yet, anyway, says Takano. The intent is to update ABCI 3.0 gradually over the next few years, says Takano, “aligning with user demands and technological advancements.” Any decisions regarding the adoption of future GPUs or network interconnects will be made based on emerging trends and projected requirements of the ABCI system users.
Sponsored by NVIDIA.

Be the first to comment