
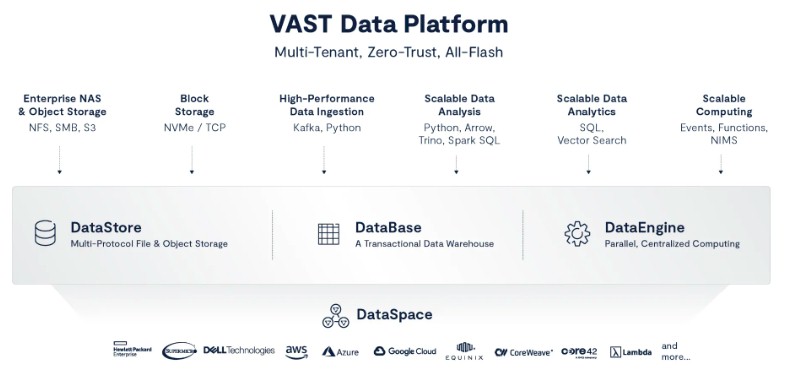
If you are going to be audacious enough to call the thing you are creating Universal Storage, then by definition it has to do everything – meaning support every kind of data format and access protocol, and do so with good performance on all fronts. And that has been the mission of Vast Data since it was founded way back in January 2016.
Creating such a vast data platform – and these days it is indeed called the Vast Data Platform because it is as much a database as it is storage, and now with this week’s announcement it also becomes a Kafka streaming cluster and log store – requires starting with the right foundation.
Co-founders Renen Hallak, the company’s chief executive officer, and Shachar Fienblit, chief research and development officer, laid that foundation, and always had more aspirations than just creating the next flash array.
Hallak cut his teeth at flash array startup XtremIO, which was founded by some of the people who created the first flash storage media and who wanted to take it into the datacenter in a big way. EMC bought XtremIO in May 2012 a few years after Hallak had risen quickly through the technical ranks to become the head of R&D. Fienblit worked at IBM’s Haifa research lab as a storage development architect, and among other things created snapshotting algorithms for IBM’s storage arrays. In 2007, Fienblit joined all-flash array startup Kaminario as vice president of engineering, rising to become chief technology officer.
By the beginning of 2016, with EMC moving too slowly on the flash front for Hallak and not interested in upsetting existing product lines excepting adding flash to them, Hallak and Fienblit joined up with Jeff Denworth, who used to run product management at HPC storage specialist DataDirect Networks, to create Vast Data. And, because EMC liked to hedge its bets, it was one of the seed investors in Vast Data. So there were no hard feelings.
When Vast Data first dropped out of stealth in February 2019, it made a splash to “ban the disk drive from the datacenter,” as we covered at the time, with a clever architecture that wove together cheap and relatively unreliable QLC flash with 3D XPoint storage-class memory, NVM-Express over Fabrics interconnects, and a new low-level construct for storage on flash media that it called Universal Storage, based on a construct called an “element,” to take on the disk array holdouts and the flash array incumbents.
One of the secrets of the Universal Storage architecture was to created a shared-nothing architecture, with flash storage nodes clustered using NVM-Express over Fabrics, but each maintaining its part of the namespace that defines where data is stored. This was in stark contrast to direct-attached, shared-everything storage arrays based on disk or flash media, or a mix of the two.
The other big architectural choice Vast Data made was to disaggregate the compute needed for running storage algorithms (encryption, compression, data reduction, and other techniques as well as the mathematics to break data down into atomic units and spread it out over a huge network of flash devices) separate from the physical flash devices. This way, compute and storage could scale independently as needed. This is not the case with NAS and SAN arrays of the past, or many all-flash arrays for that matter.
The other architectural choice that Hallak and Fienblit made to create Universal Storage was that data could be written to the storage using any protocol and could be read using any other protocol as well as the original protocol with which it was written. All natively, all fast.
At launch, Vast Data supported the NFS v3 file system and the S3 object storage protocol, and we guessed at the time that Server Message Block (SMB) file sharing protocol embedded in Windows Server and used by other client devices would come eventually to what is now called the Vast Data Platform. (SMB might have “block” in its name, but it is a means of accessing the Windows file system, not a block-level storage abstraction.)
Over time, NFS was extended with RDMA and GPUDirect support so data could be fed directly from the flash storage into GPUs without going through the host systems housing the GPUs. And in August 2023, with the full revelation of the Vast Data Platform, the company added an SQL front end and semantic system on top of the NFS file system and the “elemental” object storage underpinning Universal Storage, thereby exposing storage in a tabular format that is also able to be queried with standard SQL. This is really useful for all kinds of data analytics as well as AI training.
This week, block storage and Kafka streaming are going native on the Vast Data Platform, completing the protocol set.
“We are adding block because a lot of our customers have reached the point where everything is on Vast Data Platform except for their block workloads,” Hallak tells The Next Platform. “And they don’t like to have that little island of non-Vast, and we also want all of their data. So we are coming out with an NVMe over TCP interface, and I expect at some point we will also support iSCSI. And of course, in our fashion, everything is multi-protocol. So you can write an object and then read it and boot from it as if it was a volume. You can write a block through a block interface and then query off of it as if it was a table – obviously, depending on the information that’s in there. The point is, we have multi-protocol file, block, object, and database. All the data is accessible. It’s all our code. There’s no open source in the data path, and it is a fully universal storage system.”
Block storage, of course, underpins relational databases and the back-office applications that run the world as well as hypervisors that carve systems up into virtual machines, which in turn are often stuffed with databases and enterprise applications.
Adding the block format to Universal Storage and supporting NVMe over TCP (and eventually iSCSI) means that customers with Vast Data Platform flash arrays can use them as a kind of block SAN and do remote boot of compute infrastructure rather than putting storage in each server node in their datacenter.
Conceptually here is how all of the protocols fit:

And here is another block diagram that provides some finer granularity on the access methods to data:
With this block support, Vast Data Platform can span up to 32,000 NVM-Express subsystems, up to a million volume elements, and up to a million hosts. All of the data services available for file, object, and tabular storage in the Vast Data Platform – snapshots, clones, replication, and quality of service – are automatically inherited by block volumes.
The Ceph object store (which was eaten by Red Hat which was eaten by IBM) famously added block and file layers to an underlying object storage, but Ceph does not have native tabular formats and at least several years ago had performance issues when adding file services. There are a slew of storage arrays from the OEMs or independents that offer file and object support and that can, in theory, add block support. As far as we know, Vast Data is the only vendor that is covering all four storage bases.
Well, technically, five storage bases now that the company is also adding support for Kafka APIs as another access method to the Universal Storage.
No one would actually try to run the Kafka pub/sub streaming front end on the CNodes that make up the compute layer in a Vast Data Platform cluster. That would be silly.
The smart thing to do is to make applications that depend upon Kafka streaming to think they are talking to Kafka when, in fact, they are really just accessing Universal Storage. And that is what Vast Event Broker does.

By hooking Kafka APIs into the Vast Data Platform, you don’t have to buy a bunch of X86 servers, each with their own local storage and needing to replicate and synchronize data using brokers that talk over their own network. You stream data into the Kafka interface, and it hits the NVM-Express Fabric as it streams. And, because this streaming data is a peer, it is immediately searchable using SQL queries or accessed by any of the four other data access methods supported by Universal Storage. You don’t have to log the streaming data and ETL it into another storage platform before you can analyze it. The data has been streamed into the Universal Storage database tables, and you can query away.
Vast Data says that the largest clusters it has running Kafka streaming APIs support 500 million messages per second and on like-for-like hardware running the actual Kafka run 10X or faster on the Vast Data Platform software and hardware.


A Database For All Locations, Models, And Scales
Enterprises are creating huge amounts of data and it is being generated, stored, accessed, and analyzed everywhere – in core datacenters, in the cloud distributed among various providers, at the edge, in databases from multiple vendors, in disparate formats, and for new workloads like artificial intelligence. In this fast-evolving space, …
Accelerated Databases In The Fast Lane
Hardware accelerated databases are not new things. More than twenty years ago, Netezza was founded and created a hybrid hardware architecture that ran PostgreSQL on a big, wonking NUMA server running Linux and accelerated certain functions with adjunct accelerators that were themselves hybrid CPU-FPGA server blades that also stored the …
HPE Converges 3PAR Block And Vast Data File Onto One Alletra MP Platform
If incumbent storage suppliers want to have a business in the hybrid cloud world, they have to find ways to erase the line between what’s in the cloud and what’s on-premises – and increasingly what’s at the edge. Data and applications will be at all three locations, and in a …
Be the first to comment