

It is hard to believe that Amazon Web Services has been selling compute, storage, and networking capacity for nearly two decades. And it is easy to mistakenly think of AWS as mostly a subsidiary of Amazon that rents hardware capacity on the fly. But renting third party software like operating systems, middleware, databases, and applications represents about half of its revenues these days, and the company has a growing managed services business as well.
Drawing the lines between hardware, software, and services is, in fact, difficult, which is probably why Amazon does not do this in its quarterly financial results for AWS. AWS has recently announced a new managed service for supercomputing that is going to blur the lines even further, but continues to trajectory of the AWS business to absorb an increasing amount of IT complexity for customers in exchange for charging a pretty good premium for that.
The new Parallel Computing Service is an expanded version of the AWS ParallelCluster cloudy supercomputer that AWS announced back in 2016, a mere ten years after the EC2 compute and S3 object storage was first fired up by the world’s largest online bookstore store (at the time) and brought on the third wave – and ultimately successful wave – of utility-style computing to the world.
With the Parallel Computing Service announced last week, techies and automation tools at AWS helps HPC and AI customers of AWS infrastructure to set up and manage clusters comprised of AWS compute, storage, and networking and under control of the open source Slurm workload manager and cluster scheduler.
Slurm, short for Single Linux Utility for Resource Management and originally developed by Lawerence Livermore National Laboratory to provide an open source tool for HPC cluster management, is one of the more popular cluster managers and workload controllers in use today, with about half of the supercomputer clusters in the world tasking Slurm with babysitting applications that run on supercomputers. Since 2010, development of Slurm has been shepherded by SchedMD, which also offers commercial-grade support for the workload manager. But plenty of other organizations, include some of the world’s largest HPC centers, contribute to Slurm.
According to Ian Colle, general manager of advanced computing and simulation at AWS and, among other things, formerly director of engineering for the Ceph block storage system at Inktank, AWS is looking at all of the HPC workload managers as plug-ins for this new service. Altair PBS Pro and now Altair Grid Engine (in the wake of the acquisition of Univa back in September 2020) could be plugged into the Parallel Computing Service as needed, as can IBM’s Spectrum LSF (which it got through its acquisition of Platform Computing in October 2011), Bright Cluster Manager (which Nvidia acquired in January 2022), and Adaptive Computing’s Moab, which has not being snapped up by a cloud provider or hyperscaler just yet.
“We are in discussions with all of them to see where it makes sense,” Colle tells The Next Platform, “Because the idea about this service is reducing friction from those customers that have built up these monolithic script bases and an entire workflow around a particular workload manager. They tell us that if we want to move their workloads to the cloud, we have to make it easier for them.”
AWS has thousands of customers that have moved traditional HPC simulation and modeling workloads to its cloud, and we strongly suspect that many of them are using the ParallelCluster preconfigured HPC system configurations. ParallelCluster includes AMD and Intel X86 compute instances as well as Amazon’s own Graviton Arm CPUs as their compute engines. ParallelCluster instances can also be augmented with Nvidia and AMD GPU accelerators as well as Amazon’s own Trainium accelerators aimed at AI training. AWS instances used in a ParallelCluster are interconnected by the Elastic Fabric Adapter implementation of Ethernet developed by AWS, which includes support for RDMA memory addressing over the network. ParallelCluster also includes a managed parallel file system based on the open source Lustre stack, called FSx.
Here is what a ParallelCluster setup to run the Simcenter Star-CCM+ computational fluid dynamics application looks like:
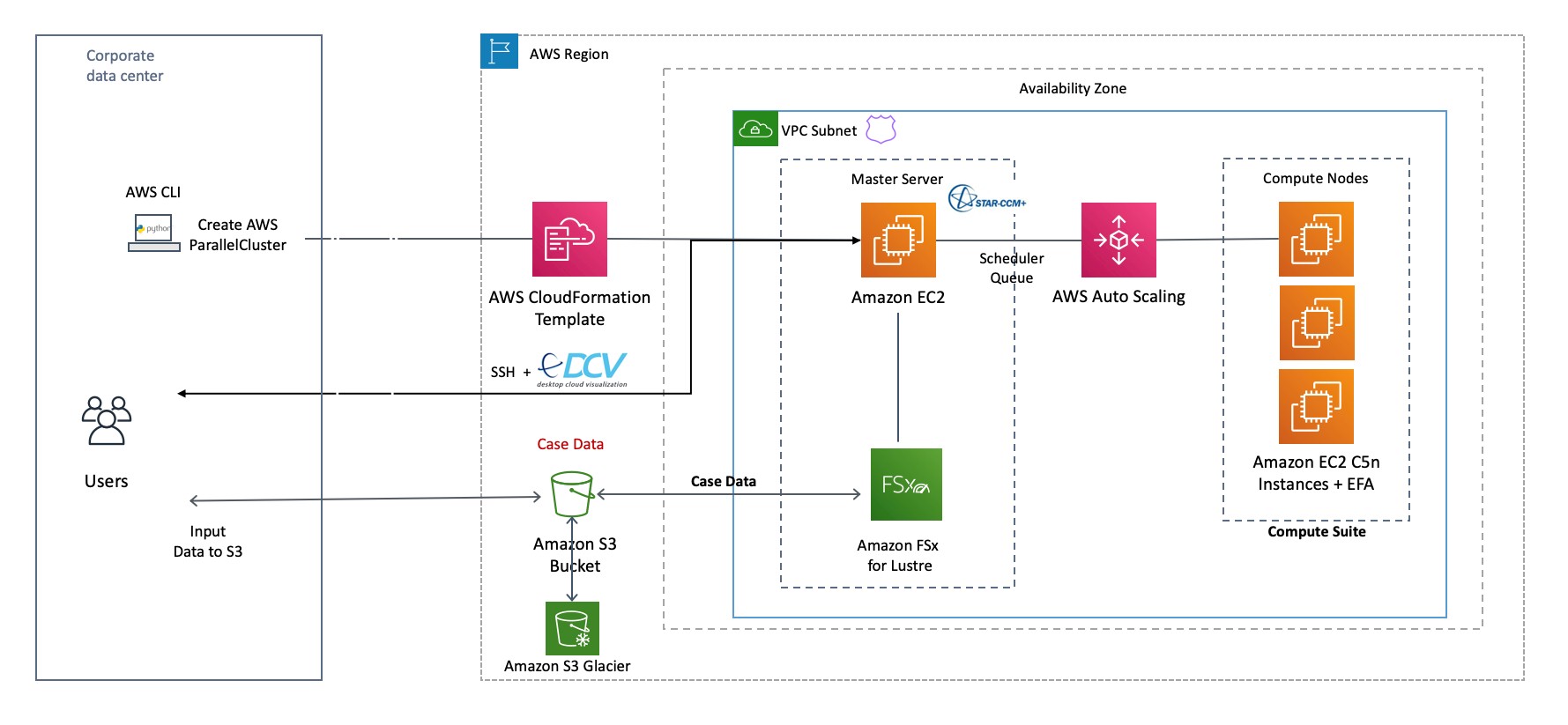
Here is the crux of the issue. These ParallelCluster cloudy HPC systems also have AWS Batch, which is a layer on top of containerized HPC and AI workloads running inside of Kubernetes containers that manages how podded applications are deployed on ParallelCluster. While some HPC shops have moved to Kubernetes containers, many still run in bare metal mode on their clusters and they don’t want to have to introduce Kubernetes to their workflows just so they can move to the cloud. And those who are using Slurm to do their application scheduling on their clusters do not want to try to shoehorn their applications onto AWS Batch. They want to keep using Slurm, and hence they have forced the hand of AWS to support Slurm alongside AWS Batch – and we think, in many cases, in place of AWS Batch.
Setting up an HPC cluster is relatively easy, but upgrading it can be a pain in the neck. And that is another reason why Slurm is now being offered as a service, according to Colle.
“One of the challenges that HPC users face is that every time they had to upgrade, they would have to shut down their whole cluster, upgrade everything by patching all versions of software, and then start it back up,” Colle explains. “Now, with the managed Slurm service that we are offering, we handle all that for them, and we are able to do the upgrades in the background with very minimal downtime. We have removed what we at AWS call undifferentiated heavy lifting. We take that off the customer and put it into the service.”
The other benefit is that customers use the same exact commands to run the cloudy cluster they rent on AWS as they currently use on their on-premises HPC cluster. And they can do something on the cloud that they can’t do on-premises: They can fire up a very large number of nodes at the same time and run their jobs much faster, save off the data from the simulation, and turn it off until they need it again. And if they have special tweaks to Slurm to set up and track resource allocations, all of this moves over with them when they fire up ParallelCluster capacity.
The Parallel Computing Service is available now in the US East (Ohio), US East (N. Virginia), US West (Oregon), Europe (Frankfurt), Europe (Stockholm), Europe (Ireland), Asia Pacific (Sydney), Asia Pacific (Singapore), Asia Pacific (Tokyo) regions.
The Slurm service requires for customers to have a Slurm management node running all of the time, which can be scaled up and down as capacity needs require and to limit the cost of this node. There is also an additional charge for Slurm management for the EC2 instances that are put into a ParallelCluster, and Colle says that depending on the use case and instances, that could be somewhere between 5 percent and 10 percent additional cost for the cluster. So far, says Colle, early adopter customers have not been balking at the cost of the Slurm service.

Nutanix Stretches Across The Hybrid Clouds
Surviving in an ever-evolving and fast-changing industry like IT requires companies to understand the landscape, see where the trends are going, and be willing to adapt to what’s happening in front of them. IBM has been a master of this. Punch cards are long gone, and while the company still …

Vertical Integration Is Eating The Datacenter, Part Two
It is funny to think of the modern datacenter as an appliance, like an iPhone, but in the cases of the hyperscalers and the very largest public cloud builders, this is more or less what they are building. As we pointed out in the first part of this series, best …

Porting to AMD GPUs in the Corona Age
“Times were simpler not so long ago” is an understatement these days, but when it comes to supercomputing, this has yet another meaning. The early days of GPUs brought some challenges, but dedication from developers and Nvidia to make sure as many HPC codes were ported and CUDA-ready over the …
Please do Google Futurama and Slurm and Colossal Worm Hiney!
Superb! Indeed, in UCRL-MA-147996-Rev-1 (2002), LLNL’s Jette et al. use the following p.2 footnote to anchor the acronym: “A tip of the hat to Matt Groening and creators of Futurama, where Slurm is the highly addictive soda-like beverage made from worm excrement.” ( https://www.osti.gov/servlets/purl/15002962 ).
They toned it down some by Rev 3 (2003, the ClusterWorld Expo version), to “[…], where Slurm is the most popular carbonated beverage in the universe.” … ( https://slurm.schedmd.com/slurm_design.pdf ) … eh-eh-eh!