
In those heady months following OpenAI’s launch of ChatGPT in November 2022, much of the IT industry’s focus was on huge and expensive cloud infrastructures running on powerful GPU clusters to train the large language models that underpin the chatbots and other generative AI workloads. These architectures could do the job, but were out of range for many enterprises, which didn’t have the money to pay for them or the staff to manage them.
More recently, IT vendors have begun developing products and services that make running AI workloads a more viable proposition, including in their on-premises datacenters and locally on workstations and other devices, as well as in the cloud. The cost of both the systems themselves and transmitting data back to the cloud for processing have become a barrier, and data security and sovereignty has become key issues as business look to include more corporate information through techniques like retrieval- augmented generation (RAG) into the datasets used to train the AI systems.
Doing more AI jobs on premises and moving the processing to where the data is being generated – including at the edge in a range of devices – was a central message at the 2024 Dell Technologies World conference last month. Jeff Clarke, chief operating officer and vice chairman at Dell, noted that 83 percent of all data is on-prem and half of that data is generated by edge devices.
Networking and serving giant Cisco Systems is also pivoting to address the AI workload needs of mainstream enterprises. That will be an important segment as generative AI continues to mature as an enterprise tool, according to Kevin Wollenweber, senior vice president and general manager of networking for datacenter and provider connectivity at Cisco Systems.
“The interesting thing about AI is that AI is not a single application,” Wollenweber tells The Next Platform. “There’s how we train the models. Those are massive, massive sets of GPUs clustered and all connected together and operating in one single environment to perform a specific task. You’ll hear Nvidia co-founder and CEO Jensen Huang talk about AI factories and systems that are set up to do these large trainings in the massive LLMs, so this is going to be done by a handful of extremely large customers. If you look at the spend in the AI space, the bulk of it is it has been there right now.”
He adds that “there’s going to be a kind of subsegment or segment in the middle that’s about fine tuning these models and potentially doing some things with RAG or other techniques to bring in more real-time datasets. Not train these things in one period of time and then move forward, but actually bring in more real-time data. Then you’re going to have the use of the models and inference. All of these require very different things from the network and very different things from the types of compute that you will leverage to go build them.”
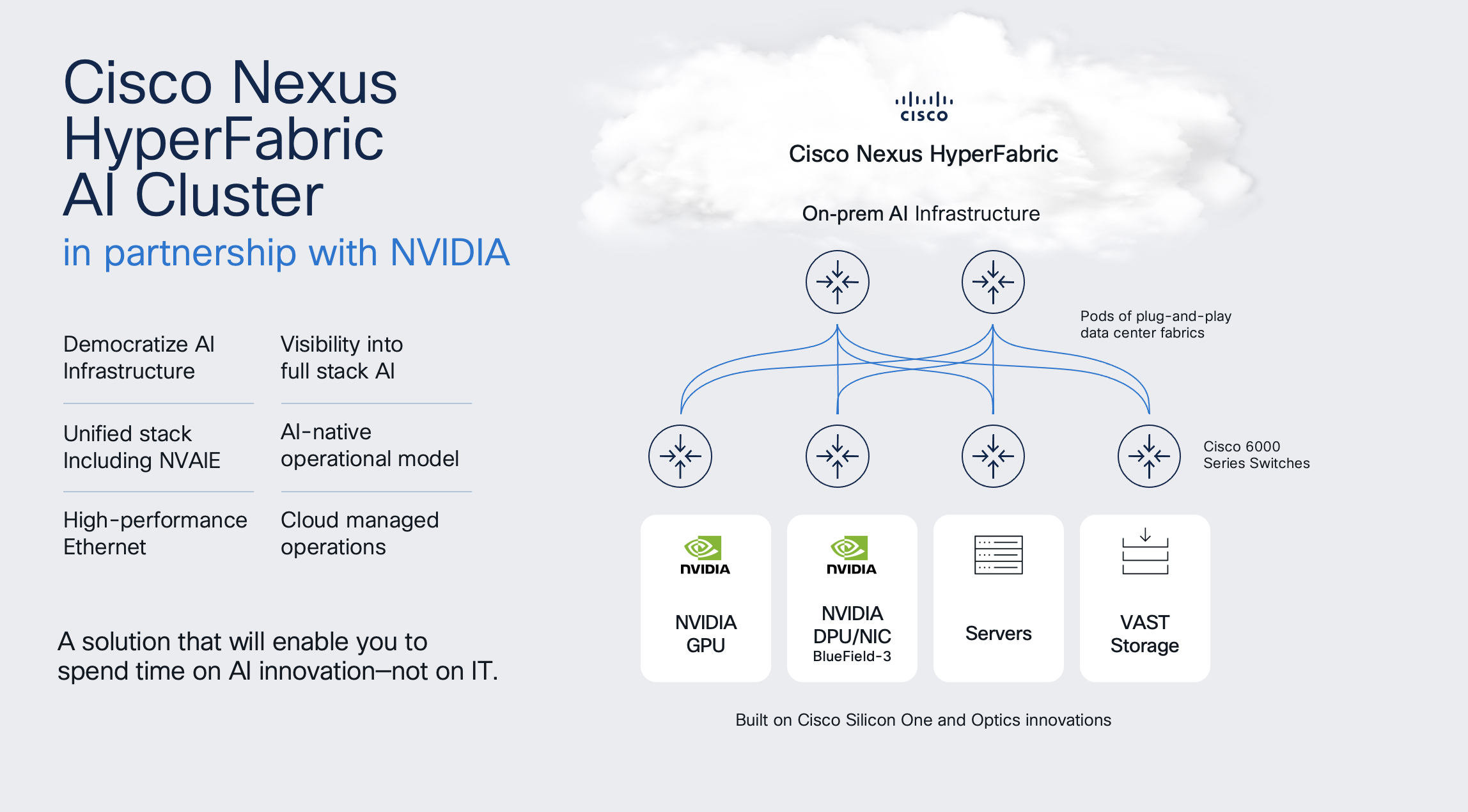
At the Cisco Live show this week in Las Vegas, the company is introducing the Cisco Nexus HyperFabric AI cluster offering that combines its AI networking, Nvidia’s accelerated computing and AI software – such as its AI Enterprise software platform – and storage from VAST Data that will deliver more automation to enterprises that want to run more AI workloads and scale their AI operations. It’s the first engineered package Cisco has developed with Nvidia, with a focus on the automated connectivity to connect the various hardware components together, including the storage and GPU devices, from the servers to Nvidia’s “Bluefield” data processing units (DPUs).
Nvidia has done well addressing the high end of the enterprise market, as illustrated by its dominant position as the go-to provider of accelerators for AI workloads and the high demand for its “Hopper” H100 GPUs – not to mention its bottom line, amassing $26 billion in revenue in the first quarter, a 262 percent year-over-year jump – Wollenweber says.
“But if you look at how they’re built as a company, a lot of their go-to-market to enterprises and some of those fine tuning and inference deployments as well, they don’t reach out directly to the long tail of enterprise and to the large set of enterprise customers,” he says. “What we really saw was an opportunity to take their best-in-class in AI technologies that they have today, marry them with what we’ve been doing for decades around simplifying and building networks and managing networks and operating networks, and build a solution that enables customers that wanted to roll out local small, medium, or large sets of GPU-based compute – whatever they actually need for those applications – and do it in a simple way and focus more on running the applications and actually getting value out of the equipment that they’re deploying.”
Cisco is bringing to the offering its 6000 series switches for spine-and-leaf configurations for the 400 Gb/sec and 800 Gb/sec Ethernet fabrics and its QSFP-DD transceiver modules to improve densities. It also will include Nvidia’s AI Enterprise platform and NIM cloud-native microservices, a container-like component of the platform that houses all the ingredients for running AI workloads, including LLMs, inference engines, and data, running in a Kubernetes Helm chart. Also included are datacenter-class GPUS, starting with the H200 NVL, and Bluefield-3 SuperNICs. There also is a reference design built atop Nvidia’s MGX server architecture.
VAST is contributing its Data Platform that includes storage and database capabilities along with a data engine built for AI.
Ethernet is a key component, Murali Gandluru, vice president of product management and strategy at Cisco, tells The Next Platform. Most enterprises have built their infrastructure around Ethernet rather than InfiniBand and for years has been a key part of Cisco’s portfolio. Cisco Nexus HyperFabric AI cluster will allow organizations to use technologies that have been in their datacenters for years as part of their AI infrastructures, Gandluru says.
It will take a few months before businesses can get their hands on the offering. Select users will have early trial access later this quarter, followed soon after by general availability, according to the vendor.
Cisco points to its recent Global Network Trends Report as validation for the strategy. In the report, 60 percent of IT pros in the next two years plan to deploy predictive network automation based on AI across their infrastructure improve NetOps environments. In addition, 75 percent expect to use tools that will offer visibility into various network domains – such as the datacenter, public clouds, branch, and WAN – through a single console.
These kinds of packaged offerings are needed for enterprises just starting with their AI efforts or are ready to move from testing to fuller deployments. Companies like Google, Microsoft, and Meta Platforms are using their own GPU-integrated technologies to build out their networks and other infrastructure parts to training massive LLMs in what Wollenweber calls a “piece-part” methodology. Not all enterprises have such capabilities.
“You can think of this as a system that enables them to deploy large fabrics, small, medium, or large numbers of GPUs, but do it in a much simpler way,” Wollenweber says. “This is more than just taking GPUs and putting them onto an internet-based fabric. We actually have an engineering partnership with Nvidia. We’re not just reselling their GPUs and connecting them into the Ethernet fabrics we’ve been building forever. The system actually has agents that run inside of the NICs themselves and help us manage and schedule and get efficiency out of the fabrics when you’re running these AI workloads.”
The big AI companies still get the lion’s share of the headlines. Just think back to January, when Meta Platforms touted plans to spend billions of dollars to buy 350,000 of Nvidia’s H100 chips by the end of the year for infrastructure to pursue research into artificial general intelligence (AGI), the point at which AI can think and reason as well as humans, but with the advantage of doing so at significantly greater speeds.
But with enterprises beginning to move in more numbers from testing to deployment, the industry can expect more packaged architectures like Cisco Nexus HyperFabric AI clusters to automate and streamline the infrastructure to bring generative AI more into their reach.

Vast Data Eyes A Role In The Datacenter Beyond Storage
In its short lifetime, Vast Data has been able to put its stamp on a fast-changing data storage market. The company was founded in 2016 by Renek Hallak, chief executive officer, Shachar Fienblit, vice president of research and development, Jeff Denworth, vice president of products, who collectively saw an opportunity …

Vast Data Sheds Hardware Business to Tackle Largest Users
For storage startups focused on the highest end of infrastructure, removing the costs associated with a hardware business might be the only way to reach potential. But only if you’re not leaving customers to fend for themselves integration-wise. Look as profitable as possible and focus on only the largest deals. …
HPE Converges 3PAR Block And Vast Data File Onto One Alletra MP Platform
If incumbent storage suppliers want to have a business in the hybrid cloud world, they have to find ways to erase the line between what’s in the cloud and what’s on-premises – and increasingly what’s at the edge. Data and applications will be at all three locations, and in a …
Are you sure about this bit “Cisco is bringing to the offering its 6000 series switches”?
I saw the reference to Cisco 6000 series switches in the graphic too, was that a Cisco slide?
If they are being deployed into DC’s then I’d assume they are going to be from the Nexus product line (Cisco have a habit of using x000 series amongst various lines but I doubt they are pushing the NCS 6000 in this role) and the Nexus 6K’s have been EoL for a while.
https://www.cisco.com/c/en_ca/products/switches/nexus-6000-series-switches/index.html
They’re new Nexus 6K models based on Silicon One that are ONLY for this Cisco HyperFabric solution:
https://www.cisco.com/site/us/en/products/networking/networking-cloud/data-center/nexus-hyperfabric/index.html