

If high bandwidth memory was widely available and we had cheap and reliable fusion power, there never would have been a move to use GPU and other compute engines as vector and matrix math offload engines. But unfortunately for Earth and very fortunately for Nvidia – and now, to a certain extent, AMD – neither HBM nor electricity are cheap, which means supercomputer architecture has been shifting to an accelerated model that pairs the CPUs we all know and love with a massively parallel offload engine of some kind.
This week, the International Super Computing 2024 conference is being held in Hamburg, Germany, and we miss those wonderful German breakfasts and a chance to hobnob with our peers and the luminaries in the HPC simulation and modeling community with some fine beers. And this being ISC24, that means the May June Top500 rankings of supercomputers is out.
Rather than pick on the limitations of the list – which we have done many times in the past because we want the list to be more meaningful for HPC and AI – we are going to take the opportunity to do a series of stories on the Top500 that extract some insight from what we have.
We will point out two obvious things that are still stuck in our craw before moving on because the situation is getting worse, not better:
- As we talked about when the November 2023 list was announced, the two of the most powerful HPC systems on Earth – the “Tianhe-3” and “OceanLight” systems in China, which we think are rated at 2.05 exaflops and 1.5 exaflops at peak theoretical performance, respectively – are not officially on the list. And when you are talking about supercomputers these days, there are perhaps dozens of machines ranging in price from hundreds of millions of dollars to more than a billion dollars at the hyperscalers, cloud builders, AI startups, and government agencies that are not on the list. The world is more lopsided than the list makes it look, and there is an enormous amount of “supercomputing” capacity being utilized, mostly to drive generative AI models.
- A very large portion of the list, mostly in the middle, is comprised of machines at various service providers and some of the big cloud builders that do not do either traditional HPC simulation and modeling or the new AI training workloads as their day jobs and therefore should not be on the list at all. These machines are added to boost the market shares of vendors and nations and are not reflective of the real HPC and AI markets. There is a long tail of many small machines that are doing real HPC that haven’t been on the list for years because of this.
Now that we have that off our chest, let’s talk about accelerators.
Because this is the first article in the spring 2024 series, we will frame the analysis of the May Top500 supercomputer rankings with the general trends in capacity embodied on the list for more than three decades now. We will separately talk about the Top10 and Top30 and drill down into the new machines on the list.
Then we will look into the energy efficiency of the machines on the Top500 and its companion Green500 rankings and see what progress in energy efficiency and the desire to boost performance further might portend for the future. We will also take a look at the prevalence of different supercomputer interconnects and how this may change as the Ultra Ethernet Consortium creates a credible alternative to InfiniBand that is based on Ethernet and that is presumably going to be more mainstream than the Slingshot interconnect created by Cray and now controlled by Hewlett Packard Enterprise.
And we want to think about how mixed precision needs to come to HPC workloads and how AI code assists might be a key technology to get the machines we can build for AI to do HPC work better. We may think of one or two more things after that.
The machines on the Top500 list are ranked based on their maximum performance on the High Performance LINPACK, or HPL, benchmark with whatever compute engines are actually used throughout the test, which is called Rmax in the list, not on the peak theoretical performance of the combined compute engines in any given machine, which is called Rpeak. To even get on the list this time around, you need to have a cluster that delivers at least 2.13 petaflops.
Thanks to the addition of a slew of new machines using newer GPU accelerators from AMD and Nvidia, the aggregate Rmax performance on the list is 8.21 exaflops, up 56.7 percent from the 5.24 exaflops from a year ago and up 86.6 percent from two years ago. That is not quite Moore’s Law growth as we knew it, and if you compare back to the November 2021 list, when the aggregate performance on the list was a mere 3.04 exaflops, then the June 2024 list has 2.7X as much total oomph, which is pretty impressive. There is a three year cycle or so in supercomputing, so progress is going to be bumpy, and as machines get more expensive and stay in the field longer, it will be flattening out, too.

This has already been happening, as you can see in the chart above that plots Top500 performance for the aggregate 500 machines and the #1 and the #500 machines since 1993, when the Top500 rankings began.
If you look at the supercomputing machines that are accelerated, as we have been doing since ClearSpeed brought its very innovative floating point accelerator to the excellent (and rarely sold) “Constellation” supercomputer systems from Sun Microsystems back in the wake of the Dot Com Bust, you would get the impression that Nvidia utterly dominates accelerated computing.

While Nvidia certainly deserves credit for creating a usable and reasonably high volume general purpose GPU compute engine and a software stack that was aimed at HPC simulation and modeling – setting up a platform that AI researchers could grab in 2010 to push early image recognition models beyond human limits – Nvidia absolutely does not own this market for accelerated HPC if you drill down into the Top500 list and if you think this list is representative of the future – not the present – of more general purpose HPC that has been pushed off this list by marketing and political shenanigans.
We think it is more useful to look at the peak performance or the number of “cores” in these accelerators – actual cores in the CPUs and actual streaming multiprocessors in the GPUs – rather than the machine count.
We love the treemap function in the Top500 site, and this one shows the distribution of Rpeak of accelerated and non-accelerated machines on the list.
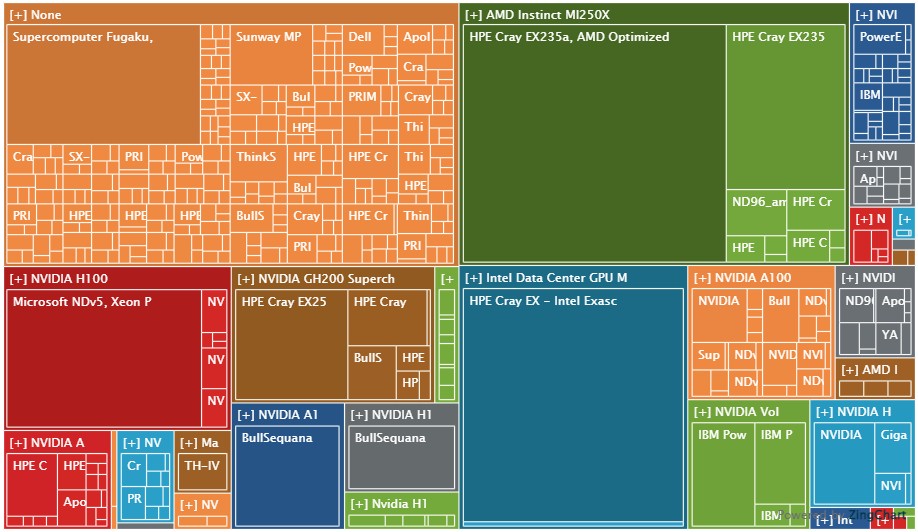
That big burnt orange section in the upper right is for the CPU-only machines, and obviously some of those machines have CPUs that have been significantly enhanced with mixed precision vector math engines – notably the A64FX Arm processors created by Fujitsu for the “Fugaku” supercomputer in Japan and the Sunway family of processors created for the “TaihuLight” machine that is on the list and the much more powerful “OceanLight” machine that is not.
In the lower right, the blue boxes are for machines accelerated by Nvidia “Ampere” A100 GPUs, the gray boxes are for those accelerated by Nvidia “Volta” V100 GPUs, and the nearby brown boxes are using Nvidia “Grace-Hopper” GH200 CPU-GPU complexes. The various reddish boxes to the right of these are using regular Nvidia “Hopper” H100 GPUs. The slate blue boxes are accelerated by Intel “Ponte Vecchio” Max GPUs, and above that is a group of various shades of green boxes that are based on AMD “Aldebaran” MI200 series and “Antares” MI300 series GPUs. That little blue border on the upper right of this treemap is for systems accelerated by Nvidia “Pascal” P100 GPUs.
Presumably this treemap chart is based on Rmax, not Rpeak.
We like to think in Rpeak when comparing across architectures and workloads because as the various tests used in HPC and AI show, the efficiency of any given benchmark on any given architecture can vary pretty wildly. While Rpeak represents a peak that cannot in practice be reached, it is a at least a measure of absolute potential from which reality is derived.
So we built this table to lay some hard numbers down on the prevalence of acceleration on the Top 500 list:

If you look at the systems only on the current June 2024 list, there are 193 machines that have some kind of accelerator. (The press release says 195, but the actual data says 193.) Of these, 7.3 percent of the systems are accelerated by AMD GPUs.
Intel has another 2.1 percent of systems with its Max GPUs, notably the “Aurora” supercomputer at Argonne National Laboratory that is still waiting to get the full machine tuned up but which has finally broken through 1 exaflops of Rmax performance on the HPL test, making it the second official exaflops machine on the Top500 rankings and as far as we can tell the fourth exascale machine behind the 1.56 exaflops “Tianhe-3” machine at the National Supercomputing Center in Guangzhou, the 1.22 exaflops “OceanLight” machine at the National Supercomputing Center in Wuxi, and the 1.19 exaflops “Frontier” machine at Oak Ridge National Laboratory. (Those are all Rmax numbers, not Rpeak.)
Yes, Nvidia has 89.1 percent of the accelerated systems on the current Top500 list, thanks in no small part to the new machines based on H100 GPUs and G100-H100 hybrids and a lot of older iron. But accelerated supercomputers using any and all Nvidia GPUs only comprise 50.3 percent of aggregated Rpeak at 64-bit precision.
And AMD and others are just getting started, and we remain convinced that the HPC market is looking for an alternative to the Nvidia stack for price/performance reasons as those buying AI training systems. So the future “Falcon Shores” compute engines from Intel have a chance of taking more share – especially with Intel cleaning up its foundry mess – and AMD pushing steady and hard with future Instinct MI400 and MI500 GPU accelerators. And in the near term, the “El Capitan” supercomputer at Lawrence Livermore National Laboratory will be coming into the November 2024 list at more than 2 exaflops using AMD “Antares” MI300A hybrid CPU-GPU complexes.
We are looking at peak Nvidia in both the HPC and the AI realms, as hard as that might be to believe. Nvidia may hold 50 percent share of performance for accelerated HPC for a long time, but it will not hold its share of systems over the long haul. Competitive pressure is too great and Nvidia GPUs and networks are too expensive for the penny-pinching HPC market, and after the GenAI hype is over, AI users will be squeezing those pennies hard enough to hear Abe Lincoln yelp. There is a reason why every hyperscaler and cloud builder is designing its own CPUs for general purpose workloads and HPC/AI hosts and are also designing XPUs for AI training and inference. This will have a huge implications for Nvidia’s future revenue streams.

Now Comes The Hard Part, AMD: Software
From the moment the first rumors surfaced that AMD was thinking about acquiring FPGA maker Xilinx, we thought this deal was as much about software as it was about hardware. We like that strange quantum state between hardware and software where the programmable gates in FPGAs, but that was not …
Meta Platforms Crafts Homegrown AI Inference Chip, AI Training Next
As we pointed out a year ago when some key silicon experts were hired from Intel and Broadcom to come work for Meta Platforms, the company formerly known as Facebook was always the most obvious place to do custom silicon. Of the largest eight Internet companies in the world, who …
What Will AMD Do With Programmable Logic And Other Xilinx IP?
AMD has finished its acquisition of Xilinx, which ended up costing close to $49 billion instead of the original $35 billion projected when the deal was announced in October 2020 thanks to the rise of AMD’s shares over the past year and a half. And now, with AMD getting the …
Interesting angle and provocative suggestion! Seeing how shares of peak teraflops match those of total cores, one may infer that the best bang-for-the-buck will come from using an appropriate number of the least expensive cores (if any), irrespective of vendor (between AMD, Intel, and Nvidia) — effectively neutering potential high price premiums commandeered by the most publicized option. In the current context, this could indeed lead to peak Nvidia for this computational space (particularly when coupled with HPL-MxP leadership of Aurora and Frontier). Quite insightful!
One would probably also want to consider energetic efficiency of the cores, for TCO, as planned for upcoming articles in the introductory paragraphs.
A true gastronomic HPC pleasure, for the finest of palates, to finally get a taste of the value-meal compute-combos as they freshly entered the menu at that Top500 hole-in-the-wall, with the GH200 grasshopper chef special, and the meditative instinct MI300A entree!
Well … that entree was really represented by identical triplets of appetizers, not enough to nourish a full-fledged swashbuckling buccaneer on its own, but an early deliveroo, with Grizzly Adams and the American Cro-Magnon of Tuolumne as conjoined computational acolytes. The El Capitan clearly decided to exhibit its stronger swagger in tip-toe motion this time, wearing a red hat (but no tutu), which is more pleasing than doing so in no-show motion as had happened before. Appetizers are meant to whet your appetite they say … well, am I thirsty for some serious rhumba now (and suplex)!
Meanwhile, the locust plague of the ARMageddon, the East Coast cicadas’ ARMpockyclypse and its 2024 double-brood of doom, them, they did show up with a gut-bomb army of swiss cheese graters, red-nosed rocket sleighs, and even telekinetic warrior-monks of the jedi persuasion — an impressive set of HPC kitchen staff and utensils, spanning the 4 to 270 range in cricket-pancake petaflips, per second! “Tastes great. Less filling”? No silly, tastes great, more filling! 8^b
“…cheap and reliable fusion power…”
A fantasy that may never happen (ALWAYS 10-20 years away, the reports of nearing grid power are deceitful.) Meanwhile, we have cheap and reliable Molten Salt Reactors (fission) that have never been rolled out.