

In the ten years since Google released Kubernetes to the open source community, it has become the dominant platform for orchestrating and managing software containers and microservices, along the way muscling out competitors like Docker Swarm and Mesosphere. (Remember those? In a decade, you won’t.)
Those building software stacked embraced Kubernetes to create their own container platforms, like Red Hat with OpenShift and VMware with Tanzu, and almost every cloud service provider was offering Kubernetes underneath their vast numbers of services and did so very quickly.
And today, more than 5.6 million developers use Kubernetes, which has a 92 percent share of the container orchestration tools space, according to the Cloud Native Computing Foundation. Kubernetes is a beast. According to Laurent Gil, co-founder and chief product officer at Cast AI, a startup whose AI-based automation platform aims to help organization optimize their Kubernetes use, Kubernetes and containers are critically important for software developers and DevOps engineers in an increasingly distributed and accelerated IT world.
“Think of Kubernetes as a fantastic toolbox,” Gil tells The Next Platform. “We used to have monolithic applications. The good thing about Kubernetes is you break up applications into smaller pieces, and the nice this with this is that some pieces can be duplicated, so you can scale easily. Imagine you are Netflix – they actually use Kubernetes – and you have millions of people coming in and looking in at the same time. If you use Kubernetes, you can duplicate these containers infinitely so you can handle that kind of traffic. Containers are fantastic for this. You can scale it. It’s almost designed this way.”
That said, there are challenges for developers when using Kubernetes in the cloud, with a key one being provisioning CPUs and memory for applications. Last year, the five-year-old company took a look at the ability of developers and DevOps staff to forecast the amount of IT resources they need for Kubernetes applications and what it found wasn’t good.
Developers typically are requesting far more compute and memory than they really need, leading to significant overspending, Gil says. In 2022, there was a wide gap – 37 percent – between the CPUs requested and provisioned, and the company found that gap widened even more last year, to 43 percent. That was the amount of overprovisioning based on what the developers thought.
“It means that in the space of one year, the waste has actually increased, not decreased,” he says. “This should be pretty well understood now. If you need two CPUs, just provision two. Don’t provision three. But it’s worse than last year.”
Average CPU Use At 13 Percent
Cast AI researchers also took a look at how many of the provisioned CPUs developers actually use. That number came in at 13 percent on average. They looked to see if the numbers were any better in larger clusters, but in those with 1,000 CPUs or more, CPU utilization only reached 17 percent.
Clusters with 30,000 or more CPUs reached 44 percent utilization, but only represented 1 percent of the systems they looked at.
All this pointed to huge CPU overprovisioning, with the bulk of compute power sits idle.
“I was expecting something not great, but I was not expecting something that bad,” he says. “On average, you have an 8x overprovisioning. The one that is really used. Out of 100 machines – CPUs being the most expensive component in Kubernetes – you only use 13. You use zero of the rest on average. If you have 100 machines, they’re all used, just at 13 percent each. Kubernetes is like gas in a room. It fills the space. If you have an application that runs on this machine, they will all be used. They will just be used at 13 percent.”
For the 2024 Kubernetes Cost Benchmark Report, Cast AI looked at 4,000 clusters running on AWS, Azure, and Google Cloud Platform between January 1 and December 31 last year before the they were optimized with the vendor’s platform. They eliminated clusters with fewer than 50 CPUs for the analysis.
Another area looked at: the utilization rates on individual cloud managed Kubernetes platforms. On both Elastic Kubernetes Services (EKS) at AWS and Kubernetes Service (AKS) at Microsoft Azure hovered around 11 percent, while it was better on Google Cloud’s Google Kubernetes Engine (GKE), at 17 percent. Clusters on GKE tend to be larger than on the other two and the service offers custom instances.
“Google being the source of Kubernetes, it probably has sophisticated users on it and that can be translated this way,” Gil says. “But you know what? Frankly, even 17 percent is not great. It’s still more than five times overprovisioning. Think of this: You go to your CTO and you say, ‘You know what? You could reduce your cloud cost by five times because you actually don’t need more than that.’”
Memory Utilization Not Much Better
Cast AI also looked at memory use, noting that on average, that came in at 20 percent. However, memory is cheaper than CPUs, so it would have been better is CPU utilization was better, Gil says. But that wasn’t the case.
“People pay more attention to memory and, essentially, as they pay more attention, they do a better job,” he says. “They pay more attention because when you run out of memory with containers, the containers stop and restart. CPUs are elastic. You can go from zero to 80 percent. There is always space for it. Memory, you can’t go above 100. It breaks if you go above 100. It’s called ‘out of memory. OOM.’ It’s the most feared issue from DevOps and Kubernetes. They pay more attention to memory and therefore it’s slightly better, but it’s still five times too much on average.”
There wasn’t much difference in the cloud platforms, with Azure, at 22 percent, with the highest memory utilization, followed by AWS at 20 percent, and Google Cloud at 18 percent.
As enterprises prepare to increase their spending on cloud services, they will need to address this utilization issue, the researchers wrote in the report. Worldwide end-user spending on public cloud services this year is expected to hit $678.8 billion this year, a 20.4 percent hike over the $563.6 billion in 2023.
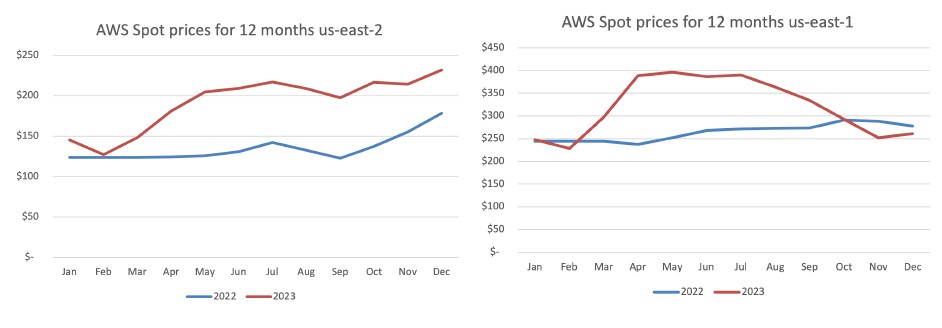
Even pricing for AWS’ Spot instances in the cloud provider’s most popular US regions increased by an average of 23 percent between August 2022 and 2023.
Many organizations who a decade ago made aggressive moves into the cloud were surprised when costs began to accumulate, with such costs joining data sovereignty and regulatory issues being key drivers behind data repatriation efforts over the past several years. Improving resource utilization would help, Gil says.
Take The Human Out Of The Equation
The problem is that determining the resources needed is still a highly manual process, he says. Developers don’t know what they’ll need for their applications or clusters because they haven’t seen it at scale. It’s difficult to guess what resources a microservice will need, Gil says, adding that it’s not getting easier at Kubernetes gets more sophisticate and complex.
“We call this a non-linear problem and you have to have a lot of small variables that you have to adjust in real time and each variable impacts the other,” he says. “It’s not just that you only use 10 percent of that, it’s that you may not be using the right one. This is why humans do this overprovisioning. They know it’s not right. But for some reason, they don’t know what to do about it.”
There are a growing number of vendors offering automated tools and platforms to improve resource optimization in the cloud. The lineup includes established players like Cisco Systems with AppDynamics, Nutanix, Apptio, VMware, and Flexera. Cast AI boasts that its platform, which uses AI techniques can cut cloud costs for organizations by 50 percent or more. In November 2023, the company got a financial boost, raising $35 million in Series B funding to bring the total amount raised to $73 million.


AWS Pushes Bang For The Buck With Graviton 4 Instances
UPDATED: Mea culpa. Due to an error in calculating the performance of the Graviton 4, we wrongly asserted that the price/performance of these chips was worse than, not better than, that of the Graviton 3. Below is a corrected story and set of data. The decades of Moore’s Law …
The Appetite For Datacenter Compute Is Ravenous
It has been an invaluable asset for AMD as it re-engaged in the datacenter in the past decade to have Forrest Norrod as the general manager of its datacenter business. Norrod ran the custom server business at Dell for many years after working on X86 processors at Cyrix and being …
Nvidia Unfolds GPU, Interconnect Roadmaps Out To 2027
There are many things that are unique about Nvidia at this point in the history of computing, networking, and graphics. But one of them is that it has so much money on hand right now, and such a lead in the generative AI market thanks to its architecture, engineering, and …
While increasing CPU use sounds good, my understanding is typical server hardware often doesn’t have enough I/O and memory bandwidth to support all CPUs running at near capacity anyway. Maybe the reason one container benefits by using more CPU is only because the other containers haven’t already chewed up all the bandwidth.
In other words, what’s important is maximizing the throughput and that may be different than increasing CPU use. Of course this only makes tuning a kubernetes cluster more complicated and important.
As Eric wrote, it could be difficult to max out all CPUs given the potential bottleneck issues. Also, though, I think the pricing model for cloud might benefit by considering the number of CPUs as one component, and the amount of energy used as another (if it doesn’t already do that). One would be paying less for X CPUs at 13% utilization, than for X CPUs at 64% utilization for example. We certainly do have this sort of overprovisioning of power in motorized vehicles, just in case (Hellcat Demon SRT for the occasional quick getaway), with running costs based mostly on energy consumed.
Average doesn’t mean much. Is the peak use near 100%? I don’t care much about average use, I’m more concerned about sudden volume change. A lot of things happen at some peak hours or some time of month. Very few workloads will be near constant. Even Netflix, I’m sure more people use it at 7 p.m. than at 4 a.m.
IBM’s Turbonomic has been doing this for 5 years on k8s, and longer on x86.
Sounds like a management problem and human issue.
And don’t build your architecture on inefficient and wasteful languages. Examples of inefficient languages are Java, C#, NodeJS, anything that run on top of a runtime environment.
Languages that compiles into machine code and run directly on the iron is where you find efficiency and maximum resource utilization.