

UPDATED: Mea culpa. Due to an error in calculating the performance of the Graviton 4, we wrongly asserted that the price/performance of these chips was worse than, not better than, that of the Graviton 3. Below is a corrected story and set of data.
The decades of Moore’s Law improvements in server CPU performance and economics have trained us all to think that no matter what, we will always see a lower cost per unit of performance with each successive generation of processors. And this is getting harder and harder to do. But with the Graviton 4 chip Arm server chip, Amazon Web Services is still getting it done.
The Graviton 4 processors designed by AWS, for which the initial R8g instances are generally available today, continue to push the envelope on performance and price/performance. Eventually there will be more instances launched on AWS based on Graviton 4, with variations in memory, local storage, and I/O capacity, but for now the base R8g instances are only available in four regions.
The Graviton family of Arm-based CPUs, which were designed by the Annapurna Labs division of the cloud juggernaut, have been gradually embiggening and are able to take on much bigger jobs with the Graviton 4 generation. The chip has faster cores, better cores, more cores, and for the first time sports two-socket NUMA memory clustering to bring 192 cores running at 2.8 GHz and backed up by 1.5 TB of main memory. The original Graviton 1 chip from November 2018 looks like a toy compared to the Graviton 4 that is rentable today.

AWS launched the Graviton 4 back in November last year, and many of the details about the chip were not revealed. Ali Saidi, senior principle engineer at the Annapurna Labs, filled in a few of the blanks in our salient characteristics table. The Graviton 4 chip, Saidi explains, runs at 2.8 GHz, pretty close to the 2.7 GHz we were guessing. With the L2 cache per core being doubled to 2 MB, the AWS team was then able to cut back on the amount of L3 cache on the processor, which left more room for the 50 percent expansion in the number of cores to 96 per chip. In fact, the L3 cache per core has been throttled back to 384 KB, which is 2.7X smaller than the L2 cache per core. The L3 cache adds up to a shared 36 MB, however, across those 96 cores, and presents a larger shared memory space than the 2 MB per core of L2 cache.
“So every L2 got bigger, that’s two megabytes instead of one,” Saidi tells The Next Platform. “And the reasoning there is pretty simple. Getting to that L2 cache is ten cycles, and it is ten cycles at twice the capacity. It takes 80 cycles to 90 cycles to get to that last level cache. We want to put as much memory as we can as close as we can, and we put it around 8X closer.”
The Graviton 4, as we previously reported, is based on the “Demeter” V2 core from Arm Ltd, the same core that Nvidia is using in its 72-core “Grace” CPU and that a number of other chip builders have opted to use. Among many other features, the V2 core has four 128-bit SVE-2 vector engines, which are useful for many HPC and AI workloads. We still don’t know the process node that AWS chose for Graviton 4, the number of transistors on this beast, the number of PCI-Express 5.0 lanes it has, or its thermal design point.
We will learn these things eventually.
AWS has over 2 million Graviton processors deployed in 33 regions and over 100 availability zones, and it is an important differentiator for the AWS cloud and an important resource for the Amazon conglomerate – which has distinct media, entertainment, retail, electronics, and cloud operations – to make use of. In fact, assuming that the Graviton 4 instances offer somewhere around the same 30 percent to 40 percent better price/performance compared to roughly equivalent X86 processors from Intel and AMD – we think it might be 20 percent to 25 percent this time around, but need to see some cross-architectural benchmarks to make a better assessment – the pricing that we have seen for the initial memory-optimized R8g instances suggests that demand for Graviton 4 is high, and so high that customers who buy it might be helping parent company Amazon get its own Graviton 4 capacity for a whole lot less money than they might otherwise.
Here are the feeds and speeds of the Graviton 4 instances, with their on demand and reserved instance pricing:
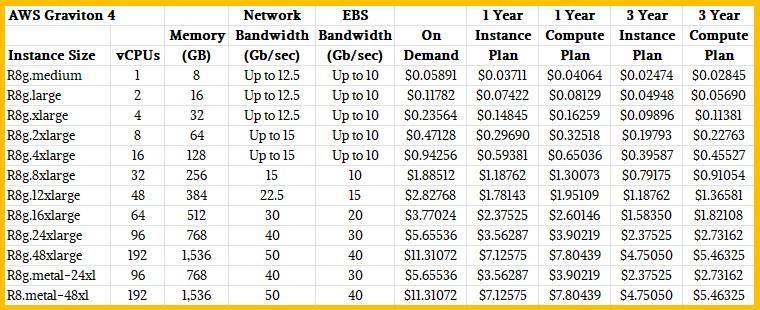
The R8g instances span from 1 to 96 cores and from 8 GB to 768 GB of memory for a single socket. There is a sliding scale of network bandwidth up to 40 Gb/sec per instance and Elastic Block Storage (EBS) also scales up to 30 Gb/sec per socket. We think that the two-socket Graviton 4 instance is a special case given that there is only 50 Gb/sec of networking bandwidth and 40 Gb/sec of EBS bandwidth for the two socket machine. Moreover, there is no instance size that has between 96 and 192 cores, which you would expect there to be if all of the physical machines that Amazon was building were based on two-socket boxes.
Then again, this could just be the way that AWS is allocating the machines. All of the Graviton 4 machines could be two-socket systems for all we know. What is clear is that AWS – and therefore its customers – are valuing NUMA memory sharing across processors, and that is because at 192 cores and 1.5 TB of memory, this can be a node that can run fairly large workloads, like SAP HANA in-memory databases, which will be certified on the R8g instances.
In general, says Rahul Kulkarni, director of product management for the compute and AI/ML portfolio at AWS, customers should expect at least a 30 percent bump in performance moving from Graviton 3 to Graviton 4 on a core-to-core comparison, but in many cases the performance is 40 percent or even higher. It depends on the nature of the workload and which integer or vector features that software makes use of. (This is the same data that AWS showed last fall when the Graviton 4 was previewed.)
Let’s compare Graviton 4 R8g instances to prior flavors of Graviton 2 and Graviton 3 instances and see how it lines up:
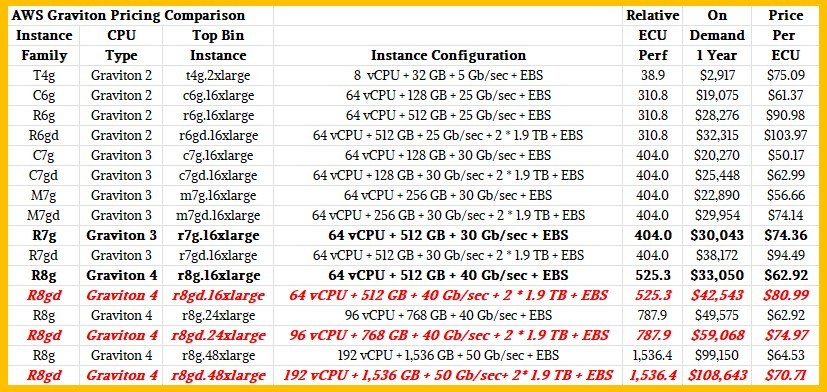
Our estimated ECU – short for EC2 Compute Unit, which is a very old relative performance metric used by AWS back in the early days – performance for the Graviton 4 lines up to the minimum 30 percent performance increase that Saidi and Kulkarni say that you should expect. In our original story back in November, we did not realize (and we suspect many others did not either) that AWS was talking about a 30 percent boost in core performance, not a 30 percent boost in socket performance as its language implied. And we carried that error forward in the original version of this story because we thought it was right. In any event, we have updated our ECU estimates in the new table above for the new top-bin Graviton 4 instances, which obviously now show an improvement in price/performance rather than worse bang for the buck. We also added a direct 64-core comparison with the R8g.
For these instances shown above, we assumed the workloads were not memory bound and applied the same relative performance to each CPU type regardless of memory. In the real world, we realize, more memory sometimes means you more closely approach the theoretical performance of a compute engine. If we had more data we would estimate the performance impact of less memory on some of the smaller instance types. But we don’t have more data.
To get a relative price/performance, we reckoned the cost of running each instance for a year at the list price currently on AWS. Just for fun, we also estimated what the cost would be for the R8gd instances, which will have dedicated local flash storage like the other “gd” instances do. This is shown in bold red italics, as usual.
Here is the upshot: If you compare the top bin 64-core R7g to the top-bin 64-core R8g instance, the R8g instance provides 30 percent more performance, it costs 10 percent more, and has a price/performance that is 15.4 percent better. As you can see, as you move to the 96-core R8g instance, the same bang for the buck holds, and when you move to the two-socket Graviton 4 instance with 192 cores, it has 3.8X the ECU oomph of the R7g instance, it costs 3.3X more, and it delivers 13.2 percent better bang for the buck.
And so, our original admonition that the Graviton 4 reminded us of IBM’s ES/9000 mainframes in 1990, Sun Microsystems’ UltraSparc-III systems in 2001, and the Intel “Skylake” Xeon SP v1 processors from 2017 was unfair and inaccurate. All of those systems and CPUs cost more per unit of performance than their predecessors. There may come a day when AWS has to charge more for Graviton performance, and not less, but that day is not today. Thankfully.
Our apologies for the errors, which we should have caught.


Details Emerge On Nvidia’s “Grace” Arm CPU
Imagine, if you will, that Nvidia had launched its forthcoming “Grace” Arm server CPU three years ago instead of early next year. How much better would Nvidia be fairing in the gaming and cryptocurrency downdraft that is impacting its sales today? Sometimes, little changes make a big difference in the …

Arm Aligns Its Server Ambitions To Those Of Its Partners
There are just two Arm-powered supercomputers on the latest TOP500 rankings: the “Astra” system at Sandia National Laboratories and Fujitsu’s new A64FX prototype. The latter captured the number one spot on the Green500 list, becoming the first non-accelerated system to do so since 2012. There are also a handful of …
Arm Is The New RISC/Unix, RISC-V Is The New Arm
When computer architectures change in the datacenter, the attack always comes from the bottom. And after more than a decade of sustained struggle, Arm Ltd and its platoons of licensees have finally stormed the glass house – well, more of a data warehouse (literally) than a cathedral with windows to …
I calculated price per ECU differently.
The r7.16xl has 64 vCPU. the r8.16xl has 64 vCPU. The cost of the r8.16xl is ~10% more than the r7.16xl. Performance is 30% better. price/performance of r8 is better than r7.
If you compare biggest instance to biggest instance, you have to take into account the 50% core count increase, which seems to then make the r8 instance better price/performance than r7.
AWS doesn’t seem to be milking its position like IBM/Sun did.
Thank you for updating the article in such an honest way. The tone of the article has changed and that’s for the better. The world needs as much good news as possible!
Looks like your story URL still carries an older headline – although you have changed the headline and content of the story.
https://www.nextplatform.com/2024/07/09/aws-charges-a-hefty-premium-for-graviton-4-instances/
It looks like there is an error in the table that compare Graviton 4 R8g instances to prior flavors of Graviton 2 and Graviton 3. It is suggested that the best price/performance instance types are the T4g and C6g. The calculation of T4g.2xlarge is taking the 64 vCPU ECU estimate( not the 1/8 portion) and price per year is a mystery as well. And the C6g.16xlarge takes the pricing calculate of T4g.2xlarge and gives the same price per ECU.
Thanks for that. This is what happens when your wife, your mom, and your best friend’s mom are all ill, with various levels of criticality, at the same time. Every interrupt stops an error correction and detection mechanism. . . .
Hopefully, like this article, they will only get better!
All the best, Timothy. We appreciate your contributions and TheNextPlatform as a whole!