

In many ways, the “Grace” CG100 server processor created by Nvidia – its first true server CPU and a very useful adjunct for extending the memory space of its “Hopper” GH100 GPU accelerators – was designed perfectly for HPC simulation and modeling workloads. And several major supercomputing labs are putting the Grace CPU through the HPC paces and we are seeing some interesting early results.
The Grace CPU has a relatively high core count and a relatively low thermal footprint, and it has banks of low-power DDR5 (LPDDR5) memory – the kind used in laptops but gussied up with error correction to be server class – of sufficient capacity to be useful for HPC systems, which typically have 256 GB or 512 GB per node these days and sometimes less.
Put two Grace CPUs together into a Grace-Grace superchip, a tightly coupled package using NVLink chip-to-chip interconnects that provide memory coherence across the LPDDR5 memory banks and that consumes only around 500 watts, and it gets plenty interesting for the HPC crowd. That yields a total of 144 Arm Neoverse “Demeter” V2 cores with the Armv9 architecture, and 1 TB of physical memory with 1.1 TB/sec of peak theoretical bandwidth. For some reason, probably relating to yield on the LPDDR5 memory, only 960 GB of that memory capacity and only 1 TB/sec of that memory bandwidth is actually available. If Nvidia wanted to do it, it could create a four-way Grace compute module that would be coherent across 288 cores and 1.9 TB of memory with 2 TB/sec of aggregate bandwidth. Such a quad might give an N-1 or N-2 generation GPU a run for the money. . . .
For reference, we did our initial analysis on the Grace chip at launch back in March 2022, drilled down into the architecture of the Grace chip in August 2022 (when no one was sure what Arm core Nvidia was using as yet), and went deep into the Demeter V2 core in September 2023 when Arm released details on the architecture. We are not going to get into the architecture all over again but we will remind you that the Arm V2 core that Nvidia adopted for Grace (rather than design its own core) has four 128-bit SVE2 vector engines, making it comparable to the pair of AVX-512 vector engines in an Intel Xeon SP architecture and therefore able to run classic HPC workloads as well as certain AI inference workloads (those that aren’t too fat) and maybe even the retraining of modestly sized AI models.
The data recently published out of the Barcelona Supercomputing Center and the State University of New York campuses in Stony Brook and Buffalo certainly bear this out. Both groups published some benchmark results pitting Grace-Hopper and Grace-Grace superchips on a wide variety of HPC and AI benchmarks, and it shows what we already surmised: if you look at thermals and probably cost, the Grace CPU is going to be able to pull its weight in HPC.
Both organizations published papers out of the HPC Asia 2024 conference held in Nagoya, Japan last week. The one that came out of BSC is called Nvidia Grace Superchip Early Evaluation for HPC Applications, which you can read here, and the one from the Stony Brook and Buffalo researchers is called First Impressions of the Nvidia Grace CPU Superchip and Nvidia Grace Hopper Superchip for Scientific Workloads, which you can read here. Together, the papers present a realistic view of how key HPC applications perform on Grace-Grace and Grace-Hopper superchips. The paper from the SUNY researchers is more useful perhaps because it brings together performance figures from multiple HPC centers and one cloud builder. To be specific, the data from the second paper draws on performance data from Stony Brook, Buffalo, AWS, Pittsburgh Supercomputing Center, Texas Advanced Computing Center, and Purdue University.
BSC compared the performance of the Nvidia Grace-Grace and Grace-Hopper superchips, which are part of the experimental cluster portion of its MareNostrum 5 system, against the X86 CPU nodes of the prior MareNostrum 4 supercomputer, which was based on nodes comprised of a pair of 24-core “Skylake” Xeon SP-8160 Platinum processors running at 2.1 GHz. Here is a handy dandy block diagram of the MareNostrum 4 nodes compared to the Grace-Hopper and Grace-Grace nodes:
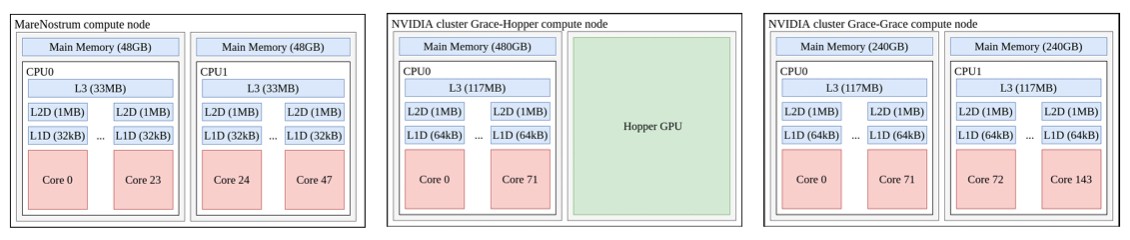
On the Grace-Hopper nodes, BSC only tested various HPC applications on the CPU portion of the superchip. (The Buffalo and Stony Brook team tested the CPU-CPU pair and the CPU-GPU pair in its evaluation of the early adopter Nvidia systems.)
Here is another handy dandy table that BSC put together comparing the architectures of the three systems tested:
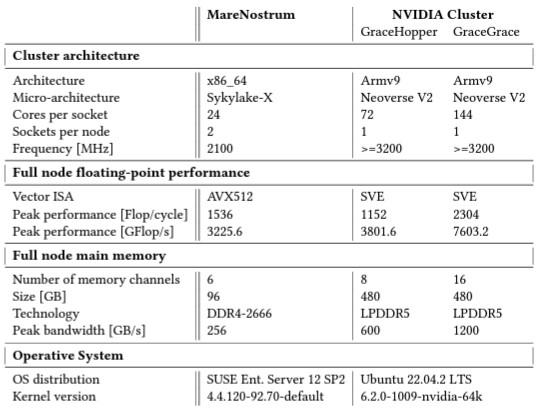
BSC says that the early access versions of the Grace processor had CPUs that were geared down to 3.2 GHz and that the memory bandwidth was also geared down from what Nvidia expected that full production units would have. The exact amount was not quantified, but the unit tested had a clock speed of around 3.2 GHz on the Grace CPU.
As for applications, BSC ran its homegrown Alya computational mechanics code as well as the OpenFOAM computational fluid dynamics, the NEMO oceanic climate model, the LAMMPS molecular dynamics model, and the PhysiCell multicellular simulation framework on the three types of nodes. Here is the rundown on how the Grace-Grace nodes compared to the MareNostrum 4 nodes. We are ignoring the Grace-Hopper nodes since the GPUs were not used and since it should be roughly half the performance of the Grace-Grace nodes. Take a look at these speedups when the same number of cores are used:
- On the Alya application, Grace-Grace was 1.67X faster to 1.81X.
- On OpenFOAM, the speedup with Grace-Grace was 4.49X.
- On NEMO, the speedup was 2.78X.
- On LAMMPS, the speedup was 2.1X to 2.9X for the same number of cores, varying from 1 to 288.
- On PhysiCell, the speedup was 3.24X for the same 48 cores on each node.
Obviously, the Grace-Grace unit has three times as many cores, so the node-to-node performance should be in proportion to this.
The Buffalo and Stony Brook paper also did a bunch of benchmarks and collected results from other machines, as we pointed out above. Here is the table showing the relative performance of the various nodes running the HPC Challenge (HPCC) benchmark, with the Matrix, LINPACK and FFT elements pulled out separately:
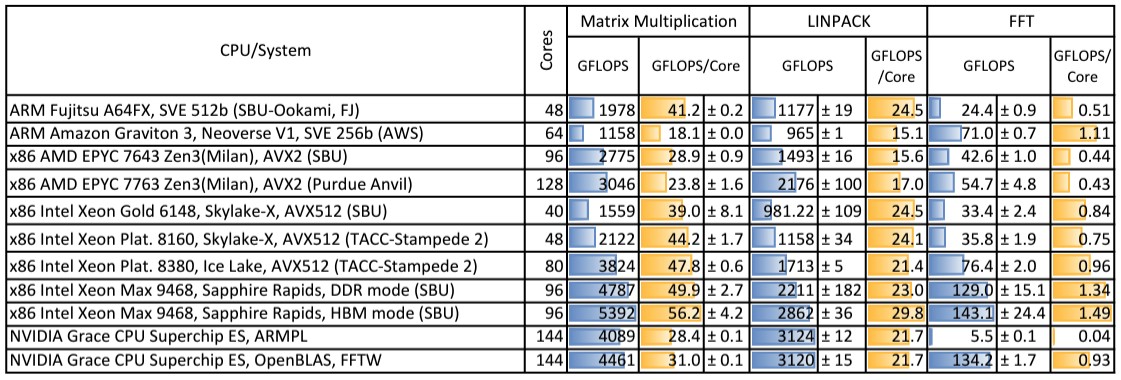
It has been a long time since we have seen benchmark data with error bars, which are obviously always present because of the difficulty of making readings and which most tests do not include. Anyway, at the socket level, the Grace-Grace superchip performance somewhere between an Intel “Ice Lake” and “Skylake” Xeon SP and somewhere higher than a “Milan” and “Rome” AMD Epyc. (Beautiful tables, but the way. Thank you.)
On the much tougher High Performance Conjugate Gradients (HPCG) test, which stresses the balance between compute and memory bandwidth and which often makes supercomputers look pathetic, here is how the Grace-Grace superchip stacked up:
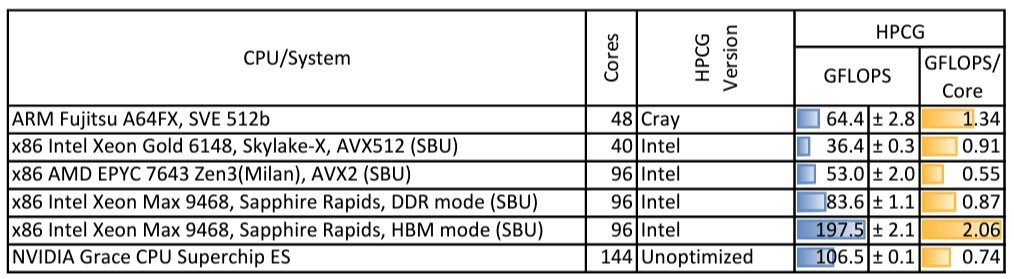
Here is how Grace-Grace stacked up on OpenFOAM, using the MotoBikeQ simulation with 11 million cells across all machines:
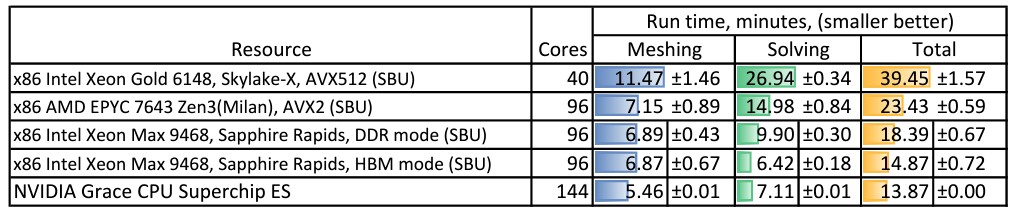
We would have expected for the Grace-Grace unit to do better here in the Solving part. Hmmm.
And finally, here is how the Gromacs molecular dynamics benchmark lined up on the various nodes, with both CPU-GPU and CPU-only variations:
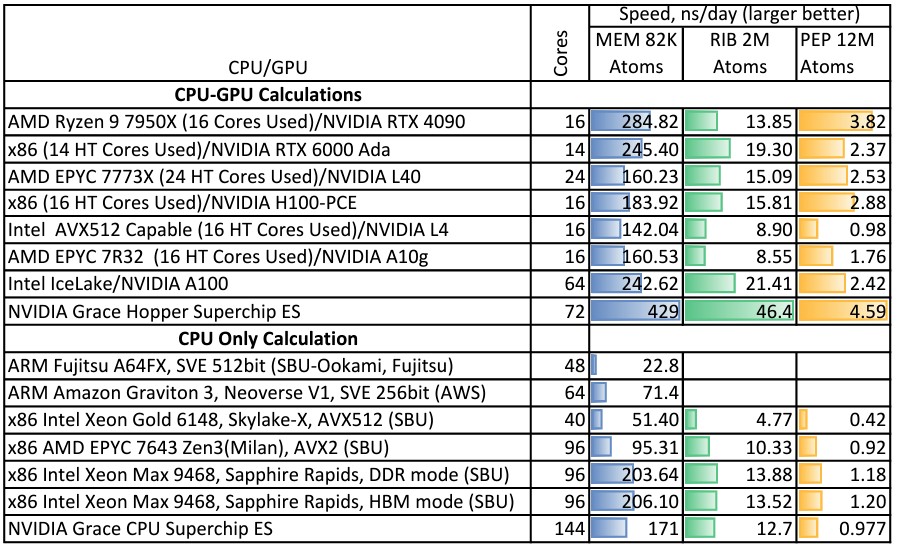
We have a winner! Look at how well that Grace-Hopper combination does. But any CPU paired with the same Hopper GPU would probably do as well. On the CPU-only Grace-Grace unit, the Gromacs performance is almost as potent as a pair of “Sapphire Rapids” Xeon Max Series CPUs. It is noteworthy that the HBM memory on this chip doesn’t help that much for Gromacs. Hmmmm.
Anyway, that is some food for thought about the Grace CPU and HPC workloads. There are other benchmarks in the Buffalo and Stony Brook paper, so be sure to check them out.


Vertical Integration Is Eating The Datacenter, Part One
Best of breed and vertical integration are two opposing forces that have been part of the datacenter since mainframes first fired up six decades ago in rooms with glass windows in them so companies could show off their technical prowess and financial might. Sometimes, vertical integration is almost inevitable, and …
Strong-Armed Into HPC, Like It Or Not
If you are an HPC center in Europe, and particularly one that is funded by public funds, you are thinking about Arm-based CPUs in your supercomputers. And that is despite Arm Holdings being a British company and all of the issues with the United Kingdom and its Brexit separation from …
Nvidia Proves The Enormous Potential For Generative AI
The exorbitant cost of GPU-accelerated systems for training and inference and latest to rush to find gold in mountains of corporate data are combining to exert tectonic forces on the datacenter landscape and push up a new Himalaya range – with Nvidia as its steepest and highest peak. It is …
Why don’t they compare againt Zen 4 server class?
They used the machinery they had at the HPC centers listed. They were comparing for their own benefit, not necessarily for all the new iron.
The information rich missing “benchmark” metric you need to know; for HPC wise choice roadmap. If you don’t know this your choice will be poor, your quality factor = 1, and your “performance” and chip will go up in flames in a pico second. Run Tufts U “HotGuage” see your chips performance, and your prestige, destroyed by advanced HotSpots. Now you know. What are you going to do? Read on. https://sites.tufts.edu/tcal/files/2022/06/ISCA22_HSSB_paper_4.pdf
“…the distribution of the amount by which per-pixel die temperature changes over 200 μs intervals for 14nm compared to 7nm [1]. The 7nm die is worse in two ways. First, the peak change in temperature is greater, resulting in faster temperature spikes. Second, the variance in temperature deltas is wider, indicating the potential for large temperature deltas. All of these changes take place over only 200 μs, indicating that techniques to mitigate hotspots will need to be even more aggressive than they
previously were, resulting in the need for increased guard-bands at the cost of dramatically decreased performance. …”
What to do? The knowledge you need for wise choice “post-exascale” HPC; June 6th 2023 Sandia granted patent “Oscillator for Adiabatic Computational Circuitry”, quality factor = 3000, NO HotSpots. “… adiabatic resonator, which includes a plurality of tank circuits, acts as an energy reservoir, the missing aspect of previously attempted adiabatic computational systems….” https://labpartnering.org/patents/US11671054 Clue: Get a license. Get wise. Now.
OK. Thanks.
Hi Tim! Heads up, the bandwidth and capacity numbers here are incorrect: “””…1 TB of physical memory with 546 GB/sec of peak theoretical bandwidth…. only 480 GB of that memory capacity and only 512 GB/sec of that memory bandwidth is actually available…”””
In fact the NVIDA Grace CPU Superchip has 960GB of memory capacity with up to 1TB/s of memory bandwidth. Each Grace CPU provides up to 480GB of LPDDR5x memory and 512GB/s of memory bandwidth. Please see Page 5 of the Grace CPU Superchip white paper: https://resources.nvidia.com/en-us-grace-cpu/nvidia-grace-cpu-superchip.
For more documentation of NVIDIA Grace CPU Superchip, see https://docs.nvidia.com/grace/ and https://developer.nvidia.com/grace.
Cheers!
Yeah, I was doing single Grace and then decided to double and then didn’t see that I didn’t double. You can always tell where the phone rings and makes me lose a train of thought….
All fixed now.
Looking at those Linpack numbers something seems way off, they have a Epyc 7763, supposedly dual socket system as it is listed as 128 cores, running at 2.1 Tflops. However looking at the top500 results for dual socket nodes with those CPUs they seems to run at about 4.1 Tflops. Dell has it at ~4 Tflops (https://infohub.delltechnologies.com/p/amd-milan-bios-characterization-for-hpc/). So were they really run correctly, or is that a single socket being compared against a whole grace+grace board? And how many other errors like that is there ?
I am actually not sure. Precise node configurations were not shown, but there are core counts. It looks like a two-socket AMD versus a Grace-Grace to me.
Hello, HPL was run within the HPCC benchmark, and the same matrix size was used across all test systems. So, some would say it is not the correct way to run Linpack. On the other hand, utilizing the same matrix size can provide more apple-per-apple comparison. Certainly, checking the range of the matrix’s sizes will be the best, but at this point, we only do one size.
You write “Here is how Grace-Grace stacked up on OpenFOAM, using the MotoBikeQ simulation with 11 million cells across all machines: We would have expected for the Grace-Grace unit to do better here. Hmmm.” What were you expecting? It already got the best results in 2 cases, and for Solving just barely lost to the Xeon with HBM.
Well, I guess I expected a sweep!
Outstanding information! It really brings nicely together a lot of the news and analyses of HPC systems covered by TNP over the past months. The comparison of A64FX and Graviton 3 shows the impact of vector units in matrix multiplication and LINPACK (A64FX has 1.5x more than Graviton 3) and suggests that Graviton 4 (same total vector capacity as A64FX) will do better there.
Elsewhere, Grace-Grace is giving SR Max (Aurora CPUs) a run for its money all around, except at HPCG where HBM is key (to bringing memory-access efficiency up from, say, 3% to 6% — the challenge is still there, not really solved, but less worse). And since SR Max is not really power-sipping … there could be hope for “Fugaku-Next”-type machines that are Grace-Grace based IMHO (to be compared also to Rhea1 and Monaka, but the first has too few vector units, and the latter is too N2, IMHO).
Granite Rapids remains a wild card (hopefully the good one that we all hope for, to keep competition going!).
On the CPU-GPU side of things, because AMD’s FP64 performance has commonly trounced NVIDIA’s, I still fully expect MI300A machines (El Capitan) to just plain crush anything else out there (including GH100 motors, like Venado). I have the hardest time waiting for these machines to turn up (along with Aurora’s full config)!
I was beginning to think you took sabbatical…
Interesting. At this point I have collected some data on the scaling of multithreaded computations on the Graces. In brief, no scaling beyond ~36 threads. Same code scales well on the A64FX up to 48 cores. So, I might be leaving some performance on the table, but the tuning guide is not much help.