
The Association for Computing Machinery has just put out the finalists for the Gordon Bell Prize award that will be given out at the SC23 supercomputing conference in Denver, and as you might expect, some of the biggest iron assembled in the world are driving the advanced applications that have their eyes on the prize.
The ACM warns that the final system sizes and final results of the simulations and models run are not yet completed, but we have a look at one of them because the researchers in China’s National Supercomputing Center in Wuxi actually published a paper they will formally released in November ahead of the SC23 conference. That paper, Towards Exascale Computation for Turbomachinery Flows, was run on the “Oceanlite” supercomputing system, which we first wrote about way back in February 2021, that won a Gorden Bell prize in November 2021 for a quantum simulation across 41.9 million cores, and that we speculated the configuration of back in March 2022 when Alibaba Group, Tsinghua University, DAMO Academy, Zhejiang Lab, and Beijing Academy of Artificial Intelligence ran a pretrained machine learning model called BaGuaLu, across more than 37 million cores and 14.5 trillion parameters in the Oceanlite machine.
NASA tossed down a grand challenge nearly a decade ago to do a time-dependent simulation of a complete jet engine, with aerodynamic and heat transfer simulated, and the Wuxi team, with the help of engineering researchers at a number of universities in China, the United States, and the United Kingdom have picked up the gauntlet. What we found interesting about the paper is that it confirmed many of our speculations about the Oceanlite machine.
The system, write the paper’s authors, had over 100,000 of the custom SW26010-Pro processors designed by China’s National Research Center of Parallel Computer Engineering and Technology (known as NRCPC) for the Oceanlite system. The SW26010-Pro processor is etched using 14 nanometer processes from China’s national foundry, Semiconductor Manufacturing International Corp (SMIC), and looks like this:
The Sunway chip family is “inspired” by the 64-bit DEC Alpha 21164 processor, which is still one of the best CPUs ever made; the 16-core SW-1 chip debuted in China way back in 2006.
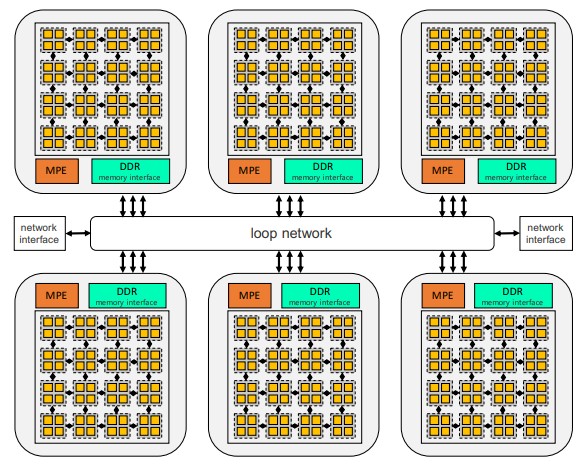
There are six blocks of core groups in the processor, with each core group having one fatter management processing element (MPE) for managing Linux threads and an eight by eight grid of cores comprising a compute processing element (CPE) with 256 KB of L2 cache. Each CPE has four logic blocks, which can support FP64 and FP32 math on one pair and FP16 and BF16 on another pair. Each of the core groups in the SW26010-Pro has a DDR4 memory controller and 16 GB of memory with 51.4 GB/sec of memory bandwidth, so the full device has 96 GB of main memory and 307.2 GB/sec of bandwidth. The six CPEs are linked by a ring interconnect and have two network interfaces that link them to the outside world using a proprietary interconnect, which we ave always thought was heavily inspired by the InfiniBand technology used in the original TaihuLight system. The SW26010-Pro chip is rated at 14.03 petaflops at either FP64 or FP32 precision and 55.3 petaflops at BF16 or FP16 precision.
The largest configuration of Oceanlite that we have heard of had 107,520 nodes (with one SW26010-Pro comprising a node) for a total of 41.93 million cores across 105 cabinets, and the paper just announced confirmed that the machine had a theoretical peak performance of 1.5 exaflops, which matches the performance we estimated (1.51 exaflops) and almost perfectly matches the clock speed (2.2 GHz) we estimated almost two years ago. As it turns out, the MPE cores run at 2.1 GHz and the CPE cores run at 2.25 GHz.
We still think that China may have built a bigger Oceanlite machine than this, or certainly could. At 120 cabinets, the machine would scale to 1.72 exaflops peak at FP64 percision, which is very slightly bigger than the 1.68 exaflops “Frontier” supercomputer at Oak Ridge National Laboratory, and at 160 cabinets, Oceanlite would have just under 2.3 exaflops peak at FP64. As noted in the comments below, the Wuxi team will be presenting the Oceanlite machine during a session at SC23 in November, and that session says the machine has 5 exaflops of mixed precision performance across 40 million cores. That implies a 2.5 exaflops peak performance at FP64 and FP32 precision and 5 exaflops at FP16 and FP8 precision. But that might now be the peak. If you assume the old rule of thumb that a machine tops out at 200 cabinets, then Oceanlite could be a machine that does a peak 3 exaflops at higher precision FP64 and FP32 and 6 exaflops peak at lower precision FP16 and FP8. That beast would weigh in at 202,933 nodes and 79.34 million cores.
Those latter numbers, if they turn out to be valid, are important if China wants to be a spoiler and try to put a machine in the field that bests the impending “El Capitan” machine at Lawrence Livermore National Laboratory, which is promised to have in excess of 2 exaflops of FP64 oomph.
For the latest Gordon Bell prize entry, the jet engine simulation was run on Oceanlite with approximately 58,333 nodes, which represents over 350,000 MPE cores and over 22.4 million CPE cores. That is a little bit more than half of the largest configuration of Oceanlite that has been reported in a paper. It is interesting that the sustained performance of the application was only 115.8 petaflops.
Another Gordon Bell finalist for 2023 is a team at the University of Michigan and the Indian Institute of Science who worked with the team at Oak Ridge on the Frontier system to use a hybrid machine learning and HPC simulation approach to combine density function theory and the quantum many body problem to do quantum particle simulations. With this work, the resulting software was able to scale across 60 percent of the Frontier system. Don’t assume that means this quantum simulation ran at a sustained 1 exaflops; it will probably be more like 650 petaflops, and perhaps a lot less depending on the computational and network efficiency of the Frontier box when it comes to this particular application.
The third finalist for the Gordon Bell prize consists of researchers at Penn State and the University of Illinois, who worked with teams at Argonne National Laboratory and Oak Ridge to simulate a nuclear reactor. (Way back in the day, we got our start in writing at the Penn State NukeE department, so kudos Lions.) This simulation, which included radiation transport with heat and fluid simulation inside of the reactor, and the ACM report says it ran on 8,192 nodes in the Frontier system, which is officially sized at 9,402 nodes and which have one “Trento” custom Epyc CPU per node and four “Aldebaran” Instinct MI250X GPU accelerators per node for a total of 37,608 GPUs.
Finalist number four for the 2023 Gordon Bell away is comprised of teams from KTH Royal Institute of Technology, Friedrich-Alexander-Universitat, Max Planck Computing and Data Facility, and Technische Universität Ilmenau who scale Neko, a high-fidelity spectral element code, across 16,384 GPUs on the “Lumi” supercomputer in Finland and the “Leonardo” supercomputer in Italy.
King Abdullah University of Science and Technology and Cerebras Systems teamed up to run seismic processing simulations for oil reservoirs on a cluster of 48 CS-2 wafer-scale systems from Cerebras that have a total of 35.8 million cores. This one is neat because it is bending an AI matrix math machine to do HPC work – something we have reported on frequently.
Number six of the 2023 finalists is a team from Harvard University, who used the “Perlmutter” hybrid CPU-GPU system at Lawerence Berkeley National Laboratory to simulate the atomic structure of an HIV virus capsid up to 44 million atoms and several nanoseconds of simulation. They were able to push strong scaling up to 100 million atoms.
This year, the ACM is also presenting its first Gordon Bell Prize for Climate modeling, and as we said we hoped would happen when in April of this year we covered the SCREAM variant of the Energy Exascale Earth System Model, also known as E3SM, developed and extended by Sandia National Laboratories, this extended resolution weather model is up for a prize. SCREAM is interesting is that is started from scratch for parts of the code, using C++ and the Kokkos library to parcel code out to CPUs and GPUs in systems, and in this case it was run on the Frontier machine at Oak Ridge, simulating 1.26 years per day for a practical cloud-resolving simulation.
The Sunway Oceanlite system is a finalist here, too, but this one simulated the effects of the underwater volcanic eruption off of Tonga in late 2021 and early 2022, including shock waves, earthquakes, tsunamis, and water and ash dispersal. The combination of simulations and models was able to simulate 400 billon particles and ran across 39 million cores in the Oceanlite system with 80 percent computational efficiency. (We want to see the paper on this one.)
The third Gordon Bell climate modeling finalist is a team of researchers in Japan who got their hands on 11,580 nodes in the “Fugaku” supercomputer at RIKEN lab – about 7 percent of the total nodes in the machine – and did a 1,000 ensemble, 500-meter resolution weather model with 30 second refresh for the 2021 Tokyo Olympics. This was a real use case, and over 75,248 weather forecasts distributed over a 30 day period and each 30 minute forecast was done in under three minutes.
So, basically, for the most part, this comes down to Froniter versus Oceanlite. Quelle surprise. . . .

Why TSMC Did A $100 Billion Deal With Trump On US Chip Manufacturing
All presidents of these United States have the bully pulpit from which to lecture the American people and, for the past century, the rest of the world about how the global economy and culture should work. Donald Trump has certainly used this pulpit in his first and now second terms …
You Can Load Up On Cheap Cores With Updated Milan Epycs
There are two ways that CPU makers can deliver more bang for the buck, and those running distributed computing workloads can go either way – or somewhere in between – as they build out their server clusters. The first is to push the process technology and architecture envelope to get …

China’s Exascale Quantum Simulation Not All It Appears
And actually, one could say it is also far more than it appears. Three years ago, a team from Oak Ridge National Laboratory (ORNL), Google, and NASA Ames published a paper showing the first glimmer of quantum supremacy. For those who don’t follow quantum computing, in a nutshell this means …
I don’t know where your information on the number of nodes in Frontier is coming from. The Oak Ridge Computing Facility website (https://docs.olcf.ornl.gov/systems/frontier_user_guide.html#id2) says Frontier has 9,408 compute nodes, and I’ve personally seen simulations run on 8192 nodes.
Bad memory and bad source. 9,402 is the official number, and I stupidly divided by two because I thought it was a two socket node and I knew better.
Woowee! The SC23 Denver Exatravaganza is just 2 short months away (Nov.12-17) — I hope the TNP budgeting office will allow for full-court press live coverage of this biggest of mile-high ballroom blitzes of the Exa-generation (without Exaggeration!)!
And, thank you for this coverage of the Oceanlite which has heretofore appeared mostly as mystery HPC gastronomy.
In addition to their Gordon Bell Prize shindig, Chinese Exafloppers are scheduled to talk about: “5 ExaFlop/s HPL-MxP Benchmark with Linear Scalability on the 40-Million-Core Sunway Supercomputer” (https://sc23.supercomputing.org/presentation/?id=pap103&sess=sess160), which, along with so many other fun talks, should prove most informative on the state of the international HPC competition.
Frontier broke new efficiency barriers at 52 GF/W last year (June ’22; compared to Fugaku’s 15 GF/W), and the swashbuckling old-spice stronger swagger of El Capitan, Aurora’s sleeping beauty, and santa’s Venado rocket sleigh, should all push that figure farther. I’d love to know where OceanLite is positioned in that spectrum (hopefully not in the neighborhood of “Autumn of the patriarch” electric chairs!).
Right on! BTW, digging archeologically through the trove of computational history that is TNP, following the narrow links into dimly lit bat-infested caves, slithering snakes, venomous funnel web spiders, the skeletal remains of ghostly buccaneers, and nittany lions, does lead to treasure chests of crispy golden nuggets, and related riddles. Tracking the 2021 Oceanlite through its labyrinthine lair suggests:
For 2021: 1.05 EF/s sustained, 1.2 EF/s single-precision, 4.4 EF/s mixed-precision, 35 MW
… or 30 GF/W. The SC23 update and Q&A should be invaluable to confirm the most recent progress, most accurate figures, and to get one’s mind blown, clean-off! 8^b
It’s great to see the 200th anniversary of Claude Louis Navier’s 1822 system of nonlinear partial differential equations describing the dynamics of viscous fluids (through mass, momentum, and energy conservation) being indirectly celebrated via these prestigious Gordon Bell Prize (GBP) nominations!
George Stokes was barely 3 years old when Navier published them, but rivalry between France and Britain, due in part to Louis the XVIth’s sponsorship of the 1776 American Revolution, just 45 years prior, probably delayed their broader adoption (monarchies hold grudges for a long time — Haiti’s still reeling from its 1804 revolution against France!).
Interestingly (for TNP’s French readership), the ORNL News Desk did recently feature a partnership between GE Aerospace and the French Safran that seems quite related to the Oceanlite GBP effort, but using Frontier’s Exascale oomph, for turbofan flow optimization (https://www.ornl.gov/news/exascale-drives-industry-innovation-better-future).
One can’t help but wonder what a world free of monarchies, dictatorships, and authoritarian governments could do!
I find the Fujitsu A64FX, the Sunway SW26010 and the AMD Epyc/Instinct based supercomputer architectures to be delightfully different. All the results are amazing, but I wonder how difficult optimising the software was in each case.
I can’t help to see that past 10 years Top500 lists have 5 years China at HPL #1 (Tianhe-2A,TaihuLight), 3 years USA (Summit,Frontier), 2 years Japan (Fugaku). Will EuroHPC (now #3, 4, 12, 13, 15, …) reach glamorous top spot? Australia, South Korea, Saudi Arabia, Brazil (#17,20,23,35)? Russia (#27 …)? The UK (#30 …)? Inquisition minds …
It is wonderful to see SCREAM as finalist in the inaugural ACM Gordon Bell Prize for Climate Modelling!
At (my napkin calcs) SCREAM’s 400 billion simultaneous equations over 65 billions spatial nodes, the corresponding FDM matrix is nominally a 1280 zettabyte affair (for FP64: 400e9 x 400e9 x 8 bytes), but luckily very sparse, with “just” 12.8e12 non-zero items (102 TBs of 27-point FP64 FDM weights). Frontier has 32 PB of RAM so these weights can fit nicely there, along with the 400 billion-value FP64 solution vector (3 TB) at each time-step — well, at least for some 10,000 time-steps; simulating one year of weather takes at least 100x as many (paging doctor NVMe!)!
Assuming that their solution algo (PCG?) requires 5 FLOPs per FDM weight, that their max wind speed is 300 km/h, and that nonlinearity converges in just 5 iterations, means 1.26 years of simulation is accomplished in (with the 14 PF/s perf of Frontier on HPCG):
12.8e12 x 5 x 3 x 5 x 1.26e6 / 14e15 = 86,400 seconds = 1 day
(as they report) which, for the whole earth, is truly awesome! Now, imagine if we could break the memory wall, and get the full 1.2 EF/s on such sparse problems (an 80x speedup)!
Not so fast! Wouldn’t PCG generate a lot of fill-in within the matrix’s band (during solution) which may be as large as 40,000 x 6 x 128 = 31e6 values per row (for 6 dependent vars going around earth’s circumference at 1km spacing, with 128 vertical nodes)? That would boost the weight matrix storage requirement to 400 exabytes (during solution) and make Frontier explode, I think.
It will be absolutely crucial and paramount for TNP to attend that SC23 presentation and Q&A to better ascertain the details of the specific numerical procedure employed by SCREAM (as mapped onto Frontier), and so-inform its most worldwide of high-caliber readerships! Is their preconditioner super-good? Are they using some anisotropic form of spherical ADI? Are captain Krylov kryptonite and its approximate matrix exponential sidekick involved?
I may have to double-check with former UMCP colleague Howard C. Elman (Dr. Preconditioner, not mayonnaise), but I think that well-crafted preconditioners can substantially reduce PCG fill-in (holy grail of the HPC secret sauce!) and that’s the expected advantage of iterative methods over direct solvers, to tackle the most portly of sparse matrix-vector systems, within limited RAM (when they work!).
The “SCREAM resonates” boldly on El Reg. as well (09/19, by TNP veteran expert N.H.-P.) where the article pointfully links to the LLNL’s news piece on GBP (under the “team” link, in the 4th paragraph) which has this very nice picture: https://contenthub.llnl.gov/sites/contenthub/files/styles/carousel_823x450/public/2023-09/screamv1BlueMarbleGordonBell2023.jpg?itok=PrGdaT8g
It beautifully compares SCREAM’s whole-earth output to cloud measurements by the Japanese Himawari meteorological satellite, in two quadrangles that look to me like southern Australia, and eastern China. Visually, the correlations are spectacularly good!
… and highly informative fully-captioned plots can be found at: https://e3sm.org/e3sm-is-a-finalist-for-the-gordon-bell-prize-for-climate-modeling/
They include how solution performance scales with number of Frontier nodes, with and without GPU optimization, and relative to Summit. Exciting stuff!
Nice to see your interest in our team’s work and kudos for the effort in finding articles on our website 🙂
I’m a member of the E3SM project. FYI, the finalist papers are out now.
Our paper: https://dl.acm.org/doi/10.1145/3581784.3627044
If you are attending Supercomputing Conference, join us.
Presentation (Nov 15 at 10:30AM): https://sc23.conference-program.com/presentation/?id=gbv102&sess=sess298