
As we are fond of pointing out, when it comes to high performance, low latency InfiniBand-style networks, Nvidia is not the only choice in town and has not been since the advent of InfiniBand interconnects back in the late 1990s. The folks at Cornelis Networks, which acquired the Omni-Path interconnect business from Intel three years ago, are that other alternative. And while it has skipped the 200 Gb/sec generation, it is still selling an improved 100 Gb/sec Omni-Path Express variant and setting the stage for its future 400 Gb/sec generation.
We went into the long history of the companies behind Cornelis Networks back in September 2020 and went into detail on the architectural repositioning of Omni-Path that the company divulged back in July 2021. That history bears repeating in brief. The executives at Cornelis Networks were there from the InfiniBand beginning at SilverStorm and PathScale, which eventually became the foundation of the TruScale InfiniBand at QLogic, which became the alternative supplier of InfiniBand that came from Mellanox Technologies. Intel bought the TruScale InfiniBand business from QLogic for $125 million back in January 2012 – doesn’t that seem like ages ago? – and three months later bought the “Gemini” XT and “Aries” XC interconnect businesses from Cray for $140 million to mash them up to create the Omni-Path interconnect. Technically, that were three different variations on the InfiniBand theme, and what Cornelis Networks is doing represents a fourth flavor in many respects.
The original goal of InfiniBand was to replace PCI-Express, Fibre Channel, and maybe Ethernet and create a converged fabric. The TruScale variant employed a technique called Performance Scale Messaging, or PSM, that QLogic certainly believed was better than the InfiniBand verbs approach and that its creators contended delivered better scale. But PSM is now more than two decades old, and Cornelis Networks is putting a new software stack together based on the libfabric driver that is part of the Linux operating system and replaces the PSM provider that was part of the QLogic TruScale and Intel Omni-Path stack with the OPX provider from the Open Fabrics Interfaces working group.
This new stack has been developed to run on the 100 Gb/sec Omni-Path hardware that Cornelis Networks bought from Intel – what the company calls Omni-Path Express, shortened to OPX – and will be the only stack available on the future 400 Gb/sec Omni-Path Express CN5000 family that is under development right now.

The libfabric library is the first implementation of the OFI standard, and it is a layer that rides above the network interface card and the OFI provider driver and between MPI, SHMEM, PGAS, and other memory sharing protocols commonly run on distributed computing systems for HPC and AI. It looks like this:
Here is what the Omni-Path Express host software stack looks like now, with the second generation PSM2 provider and the native OFI provider running side by side:
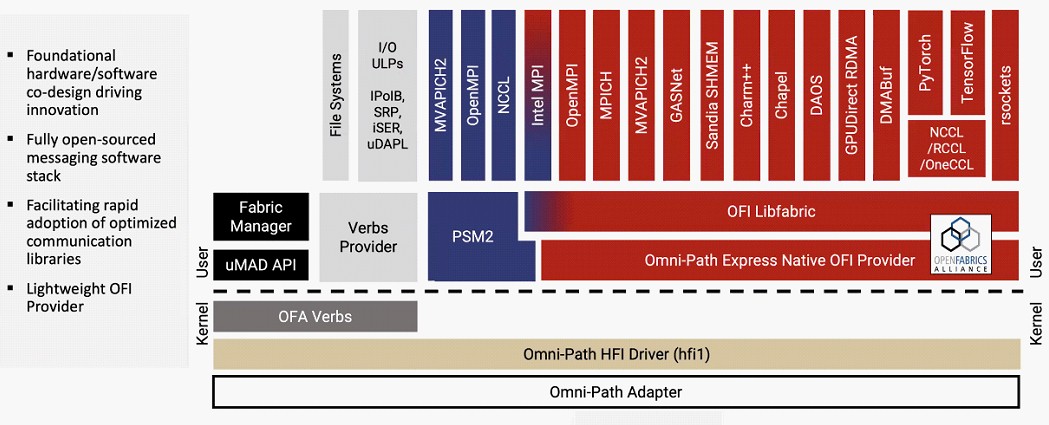
You will note that the original OpenFabrics Alliance Verbs are still available in Linux kernel mode for legacy support of the InfiniBand verbs provider for legacy protocols and frameworks, but that PSM2 and the OFI provider are both running in Linux user space as are the various implementations of MPI – and there are a lot of them.
With the next generation CN5000 platforms, the PSM2 stuff in purple goes away, and we presume so does the Verbs provider and the stuff riding on top of the OFA Verbs code running in the Linux kernel. According to Doug Fuller, vice president of software engineering at Cornelis Networks, who gave a presentation this week at the Hot Interconnects 30 conference, one of the key differentiators between OPX and Nvidia InfiniBand is that all of the stack used by Cornelis Networks will be open source and added upstream in the kernel.
“Our Omni-Path OFI driver is part of the Linux kernel,” explained Fuller in his presentation. “And by part of, I mean we are upstream first with our kernel development as well. So all of our patches are merged upstream, and we have the flames from Linus to show for it. And then we merge. And we encourage it to be merged downstream and integrated into the various Linux distributions. So in most cases, if you bring up a modern Linux distribution, your drivers already present no additional software installation is required. We are committed to our upstream first development, and we want to make sure that we give back to the communities that we use, and we provide a good user experience for our users.”
What we have been wanting to see for three years, and what Fuller delivered to the Hot Interconnects audience, was a much-anticipated roadmap for the Cornelis Network hardware. And without further ado, here it is:

HPC centers, cloud builders, and hyperscalers all like predictable roadmaps that bring the cost of shifting bits around down lower and lower with each generation and that also increase the scale of the network in terms of how many endpoints can be attached to them with reasonable response time. These are the stakes that Cornelis Networks has finally and publicly put in the ground, and as you well know, companies don’t buy point products they buy roadmaps because we all live in the future.
With the Omni-Path 100 line, Cornelis Networks is reselling the hardware that was created by Intel and that started rolling out back in late 2015 in early adopter HPC systems based on its “Knights” family of many core processors. (We think Cornelis forgot to put the “Express” part of the brand in the roadmap. We throw no stones about typos. . . .) The lineup includes a 100 Gb/sec adapter, a 48-port edge switch, a 288-port director switch, and a 1,152-port director switch. The Omni-Path 100 interconnect supports 3 meter and shorter direct attach cables (DACs) and active optical cables (AOCs) that are 100 meters or less. The radix of the switches supported up to 13,800 nodes at full bisection bandwidth across a fat tree or 27,600 nodes at half bisection bandwidth, with 36,800 nodes maximum with some tapering of the network.
With the Omni-Path CN5000 CN5000 series – what Cornelis Networks is calling its fifth generation of high performance interconnects considering the long history of the products that were introduced over the years by its co-founders – the ASICs in the switches and the adapters are moving up to 400 Gb/sec, which will be a huge jump in performance. There will be a 48-port edge switch (which looks like a normal pizza box machine instead of that funky shape Intel did with Omni-Path 100) and is splitting the difference on the director switch and going with a single 576-port machine. As for cables, the DACs and AOCs will be supported, as will active copper cables (ACCs) that stretch the copper cables to a 5 meter or shorter length, which is 2 meters more than the DACs and thus providing a little more creative wiring configurations.
The CN5000 series will support full and partial bisection bandwidth trees like Omni-Path 100 and will also support dragonfly and Megafly (sometimes called Dragonfly+) topologies and will scale up to 330,000 nodes in a single cluster. (We don’t know how many tiers and hops there will be in such networks, but we aim to find out.) Cornelius Networks is adding telemetry-based dynamic adaptive routing and congestion control, which sounds like it might be based on some ideas culled from the Cray “Aries” technology that Cornelis Networks has access to via Intel. (Again, we will find out.) Latencies (which we presume are from node to node) are promised to be as low as under 1 microsecond and message rates are expected to be 1.2 billion per second. The CN5000 director switch will be offered with air-cooled and liquid-cooled options.
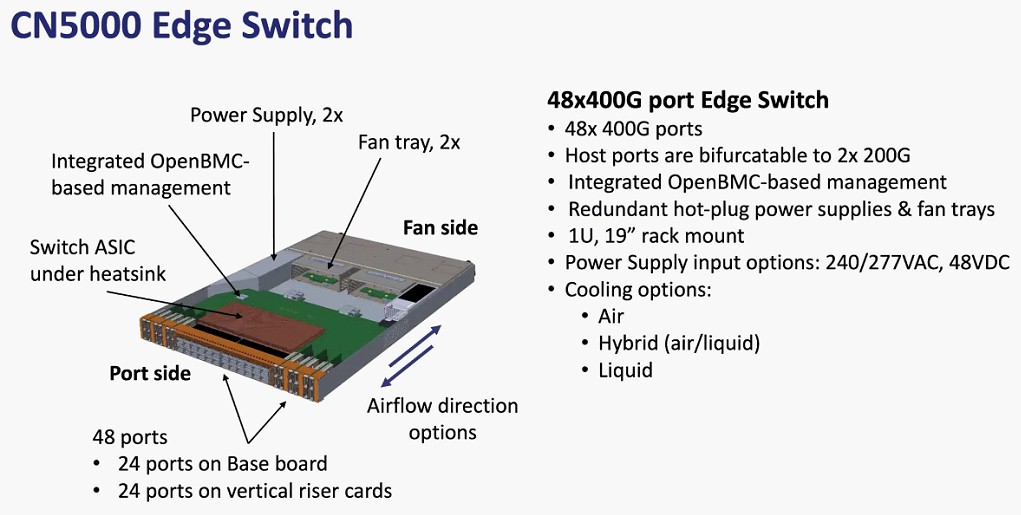
Here are some specs and mechanicals on the CN5000 edge switch:
These are the specs for the CN5000 director switch:

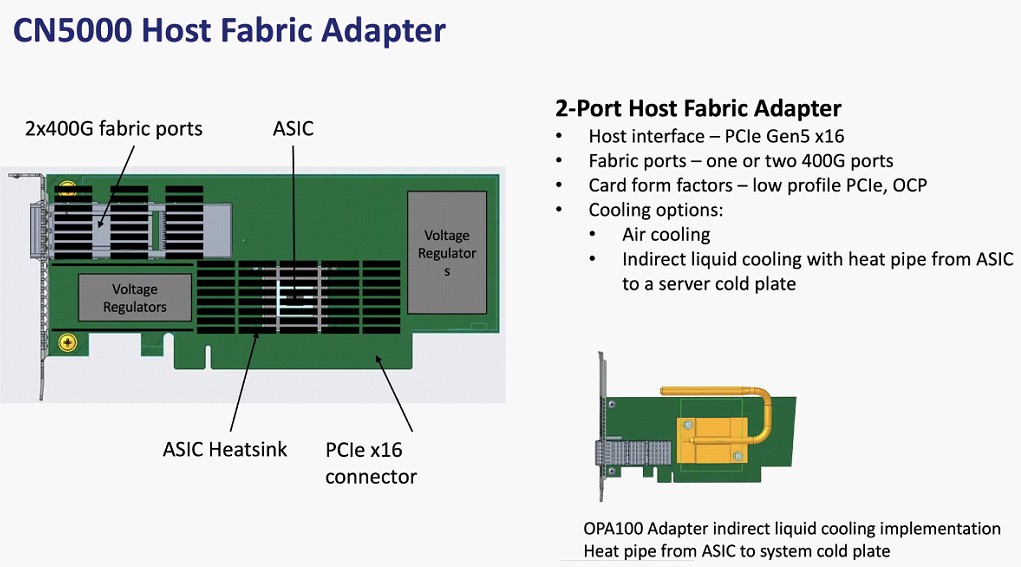
And finally, this is what the host fabric adapter looks like:
In 2026, the Cornelis roadmap jumps the Omni-Path CN6000, which has switch and adapter ASICs that support 800 Gb/sec. The adapter to switch cable options remain the same, as to the bisection bandwidth, the topology options, and the scale to 330,000 nodes. The interesting twist here is a DPU using RISC-V cores that plugs into a CXL port and that presumably will do some collective operation offload and security and storage acceleration functions. Certain fabric functions will be offloaded and there will be fabric-specific accelerators, possibly in both the switch and the adapter.
With the seventh generation coming in 2028, Cornelis Networks will boost port speeds to 1.6 Tb/sec and add the HyperX topology to the list of network geometries as well as make enhancements to the DPU cores and fabric and application offload.
It has been a while since we have seen an InfiniBand roadmap from Nvidia or Mellanox – and certainly not one that goes out that far. But the cadence and the speed bumps will probably be more or less in synch at some point.

Hell Freezes Over: Cisco And Nvidia Cross-Pollenate AI Networking
UPDATED Networking giant Cisco Systems and AI platform provider Nvidia have hammered out a deal to mix and match each other’s technologies to create a broader set of AI networking options for their respective and – importantly, prospective – customers. Nvidia has been a competitor of Cisco’s in the datacenter …

Lawrence Livermore Kicks In Funds to Foster Omni-Path Networking
Decades before there were hyperscalers and cloud builders started creating their own variants of compute, storage, and networking for their massive distributed systems, the major HPC centers of the world fostered innovative technologies that may have otherwise died on the vine and never been propagated in the market at large. …
Attacking The Novel Coronavirus With Supercomputing Cycles
Dan Stanzione has a lot of compute power at his fingertips. As executive director of the Texas Advanced Computing Center (TACC) in Austin, Stanzione is in charge of a number of supercomputer, including “Frontera,” a Dell EMC machine powered by Xeon SP Platinum processors from Intel that was deployed last …
There’s a typo in the article, the company name was SilverStorm not SilverStream. and for bonus points, before it was SilverStorm it was Infinicon Systems
I’d love it if they could bring Co-Packaged Optics (CPO) into their 6th gen., where CXL enters the roadmap (AOCs are great, but CPOs are like that next step of wow/awesome! that gets buyers excited imho …).