

Similar to interior designers trying to fit the chairs, tables, and other furniture in rooms inside of a home, chip designers have to figure out where the various bits and pieces of a processor will lie on confined floor plans where latency between parts matters.
Interior designers have to consider space and ease of movement through and between rooms, their chip counterparts worry about how power, performance, and area are affected by where they place their macros – transistor blocks such as memory, analog devices like PCI-Express controllers or memory controllers, or the cores themselves – on a semiconductor device.
For a long time, this has been a highly manual two-step process – first placing the macros, then the myriad smaller standard cells. More recently, designers have adopted a more mixed approach, placing macros and standard cells simultaneously, though even that is a challenge.
“These macros are often much larger than standard cells, which are the fundamental building blocks of digital designs,” Anthony Agnesina and Mark Ren, research scientists at Nvidia, wrote in a blog post this week describing some AI-assisted macro block placement work they are doing. “Macro placement has a tremendous impact on the landscape of the chip, directly affecting many design metrics, such as area and power consumption. Thus, improving the placement of these macros is critical to optimizing each chip’s performance and efficiency. The process must be improved, given modern complex relationships between macro placement, standard cell placement, and resulting power, performance, and area (PPA).”
New methods have come on the scene in recent years, including reinforcement learning – where algorithms and neural networks learn via sampling many macro placement examples – and the aforementioned concurrent cell and macro avenue. Nvidia is proposing using DREAMPlace – a GPU-accelerated open source deep learning toolkit first unveiled by the company in 2019 – to place very large scale integrated (VLSI) circuits on chips to improve the concurrent largely manual method for placing macros and standard cells.
Nvidia’s proposal also calls for tweaking the way the current concurrent cell and macro placement method is run, including using a multiple-object optimization framework to extend the search space and to reduce the “optimality gap,” the difference between the best known solution and the lower bound, which is the value that the objective value can’t fall below.
DREAMPlace is an analytical placer created using the PyTorch deep learning framework and toolkit that uses a placement problem to train a neural network. Nvidia scientists presented the research paper for AutoDMP (Automated DREAMPlace-based Macro Placement) today at the International Symposium on Physical Design, part of a larger trend by the GPU maker and others in the industry to use AI to design more powerful and efficient chips.

AutoDMP incorporates all the components that were front and center at Nvidia’s GTC 2023 show last week, from the GPU acceleration and machine learning techniques to the need to increase efficiency and reduce power.
“This work demonstrates that a vast design space can be efficiently searched to find better macro placement solutions using ML-based multi-objective optimization and GPU-accelerated numerical placement tools,” wrote Agnesina and Ren, who were among the eight Nvidia researchers who wrote the paper. “DREAMPlace formulates the placement problem as a wire length optimization problem under a placement density constraint and solves it numerically.”
According to the researchers, the proposed method calls for using the Multi-Objective Tree-Structured Parzen Estimator (MOTPE) Bayesian optimization algorithm to explore the design space by tuning the parameters of the placer to target three objectives, focusing on wirelength, cell density, and congestion. It includes a two-tier power, performance, and area (PPA) evaluation scheme to manage the complexity of the search space. Nvidia also is advocating for changes in the DREAMPlace placement engine “to reduce legalization issues and significantly expand its design space, thereby increasing the potential achievable PPA,” according to the paper.
“We propose to use multi-objective optimization rather than single-objective optimization in the parameter space,” Agnesina and Ren wrote. “The objectives are wire length, density, and congestion. All three objectives are evaluated from the DREAMPlace detailed placement. The wire length is approximated with the rectilinear Steiner minimum tree (RSMT) length. The density is the target cell density used in DREAMPlace. Finally, the congestion is estimated with the RUDY algorithm.”
The researchers chose 16 parameters in DREAMPlace to define the design space, with the parameters “determined based on the observation that they significantly impact the placement quality,” Agnesina and Ren wrote. “We included optimization-related parameters (such as the gradient-based numerical optimizer and its learning rate) and physical parameters (such as the number of bins for the density evaluation and the density target). Multi-objective optimization seeks to find the Pareto front. This is the set of nondominated objective-space points, where no objective can be improved without degrading at least one other objective.”
They also added parameters beyond those in DREAMPlace, including initially setting the positions of cells and macros at the center of the floor plan, which influences the quality of the final placement. Also, to ease macro legalization – a legal macro placement is one where the macros don’t overlap and fall in line with various design constraints – two parameters were added to ensure minimum vertical and horizontal spacing between macros.
AutoDMP was evaluated using a macro placement benchmark from the TILOS AI-Institute, which includes CPU and AI accelerator designs that come with a large number of macros. In the evaluation, researchers integrated AutoDMP with a commercial EDA tool and ran the multi-objective optimization on an Nvidia DGX AI system that included four “Ampere” A100 GPU accelerators, each with 80 GB of high bandwidth memory. Sixteen parallel processes were spun up to sample parameters and run DREAMPlace, with the selected placements run through the EDA flow from TILOS that ran on a CPU-powered server.
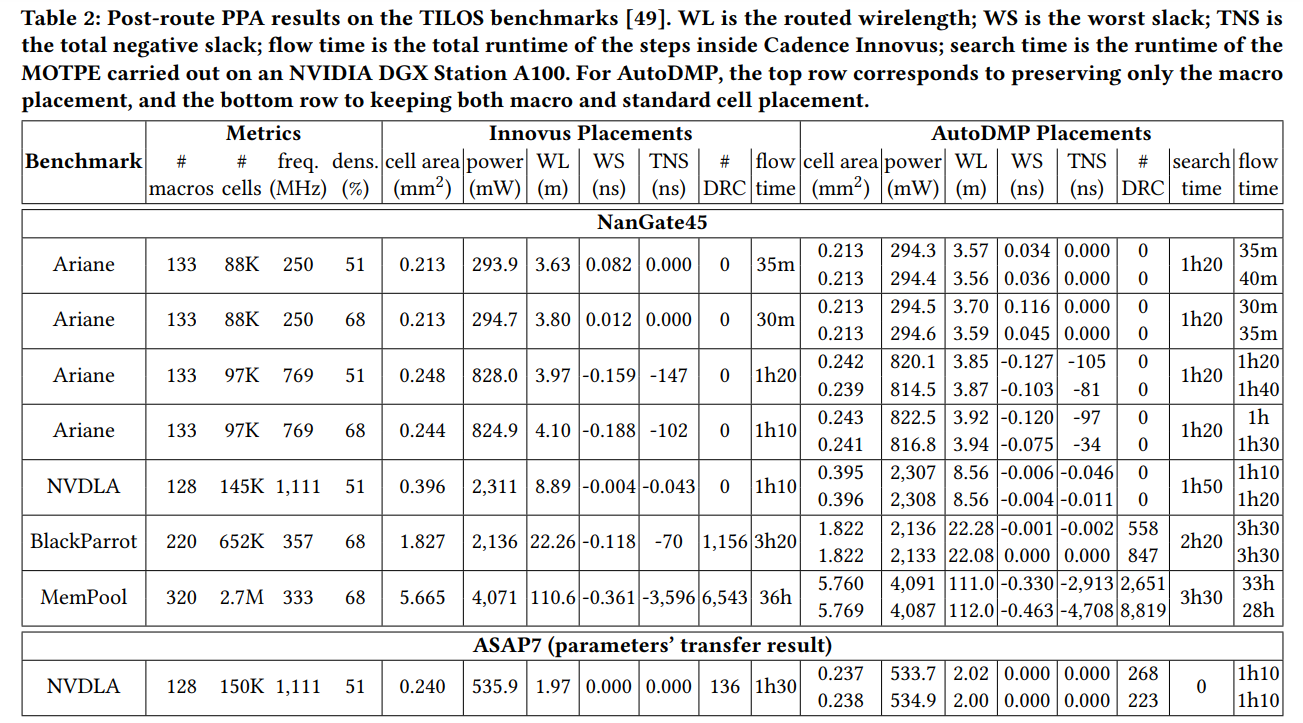
By tuning the augmented parameters in DREAMPlace and including multi-objective optimization, the researchers wrote that they were able to generate macro placement options in a few hours on the DGX system – which included sampling 1,000 design points for each design – that were comparable to what commercial products can turn out and better than open-source academic tools. They added that the “advances can help the turnaround time of early-stage architectural exploration and assess more accurately and efficiently floorplan modification decisions.”
“This work demonstrates the effectiveness of combining GPU-accelerated placers with AI/ML multi-objective parameter optimization,” Agnesina and Ren wrote. “Furthermore, given the importance of scalability in modern chip design flows, we hope this methodology can unlock new prospective design space exploration techniques.”

Be the first to comment