
When we last focused on Untether AI in 2021, the AI inferencing hardware startup had just secured $125 million in funding, which came a year after the company officially launched with its first-generation runAI200 devices and its unique at-memory inferencing approach.
The fifth round of financing dwarfed the $27 million the four-year-old company had raised up to that point and brought the total amount of money Untether AI had brought in to $152 million. This week at the Hot Chips 34 virtual conference, the industry got a look at how the startup was using its new-found riches.
Untether AI introduced the second generation of its at-memory architecture for AI inferencing workloads, speedAI240 devices, which carry the internal codename of “Boqueria.” It’s designed to drive greater energy efficiency and density and comes with a spatial architecture that enables designers to scale it for smaller or larger devices and to interconnect it in a way to address the largest natural language processing models.
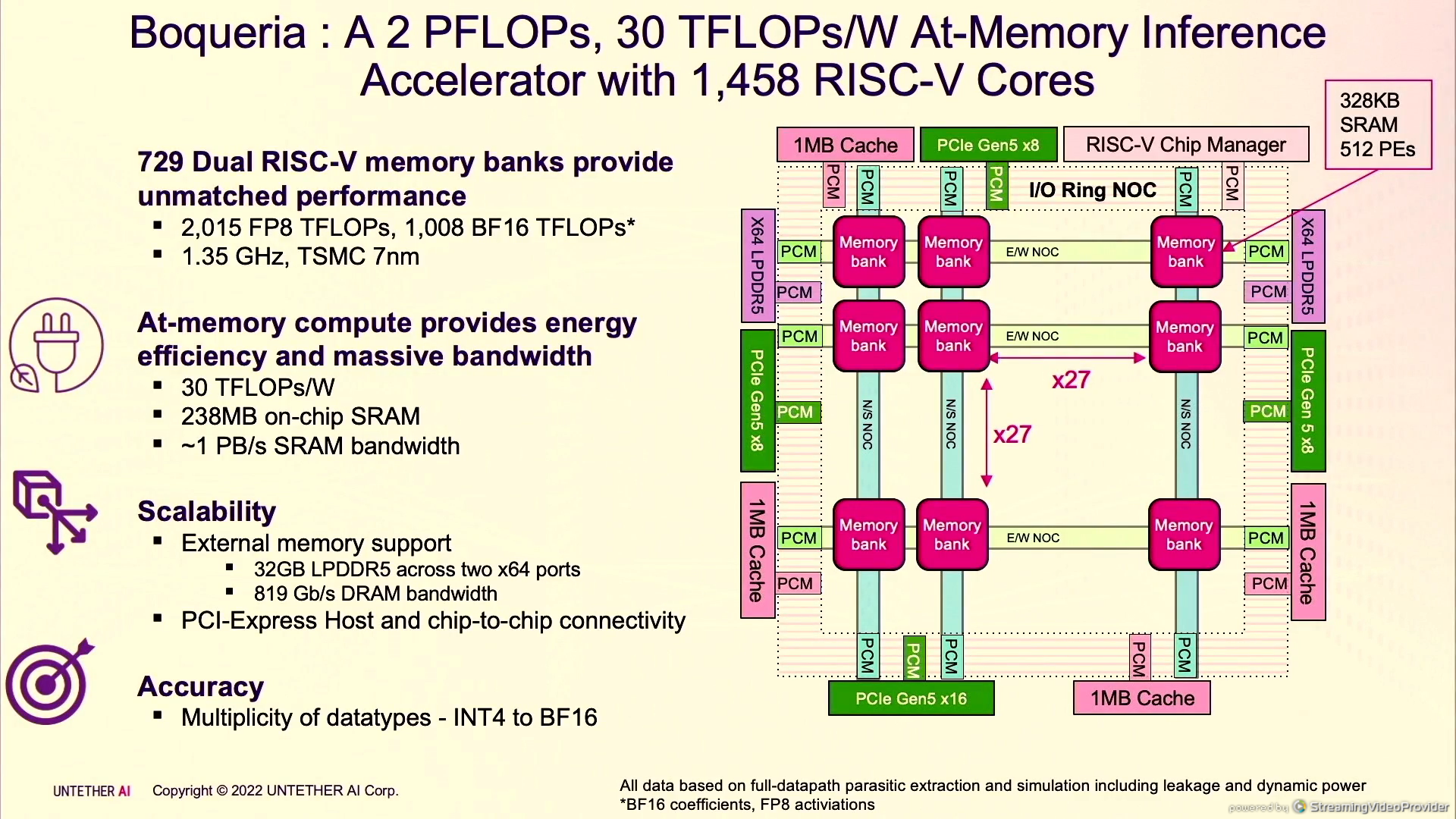
The company’s original runAI200 inference accelerators, built on Taiwan Semiconductor Manufacturing Co’s 16 nanometer process, offered 500 INT8 TOPs of performance, eight TOPs per watt of power efficiency, and 200 MB of SRAM. The new “Boqueria” chip is built on the 7 nanometer TSMC process and comes in with 2 petaflops of FP8 performance (which works out to 30 teraflops per watt) and 238 MB of SRAM memory.
“With Boqueria, we’re solving the three key challenges” that AI inference presents, Robert Beachler, vice president of product and hardware architecture at Untether AI and a veteran of such companies as Xilinx and Altera, said during a presentation at Hot Chips. “First of all, it’s at-memory compute structure provides unrivaled energy efficiency, which drives the ability to increase the throughput and acceleration of neural networks. It’s a scalable spatial architecture so that we can make smaller devices and larger devices and we can interconnect them together in order to scale to the largest natural language processing models. And because we’ve selected the right level of compute granularity, we can support today’s neural network architectures and be future proofed for future neural networks.”
It also supports multiple data types, enabling organizations to trade off between accuracy and throughput to meet the specific demands of their applications, Beachler said.
Untether AI, with a team deep in accelerator experience, was founded in 2018 and jumped into an AI inferencing space crowded with not only established companies like Google, Nvidia, and Microsoft but also a slew of startups like Cerebras, SambaNova, Graphcore, and Celestial AI, all looking to gain traction in the AI and machine learning market.
As we discussed in this deep dive of the company when it came out of stealth in 2020, a key differentiator for the company is its at-memory compute architecture. As Beachler explained at Hot Chips, 90 percent of the energy spent in neural network computing comes from moving the data from external memory or internal caches. Traditional von Neumann near-memory architectures are inefficient, with long and narrow busses and large caches. On the other end, in-memory architectures are low energy, but the design also slows the performance.
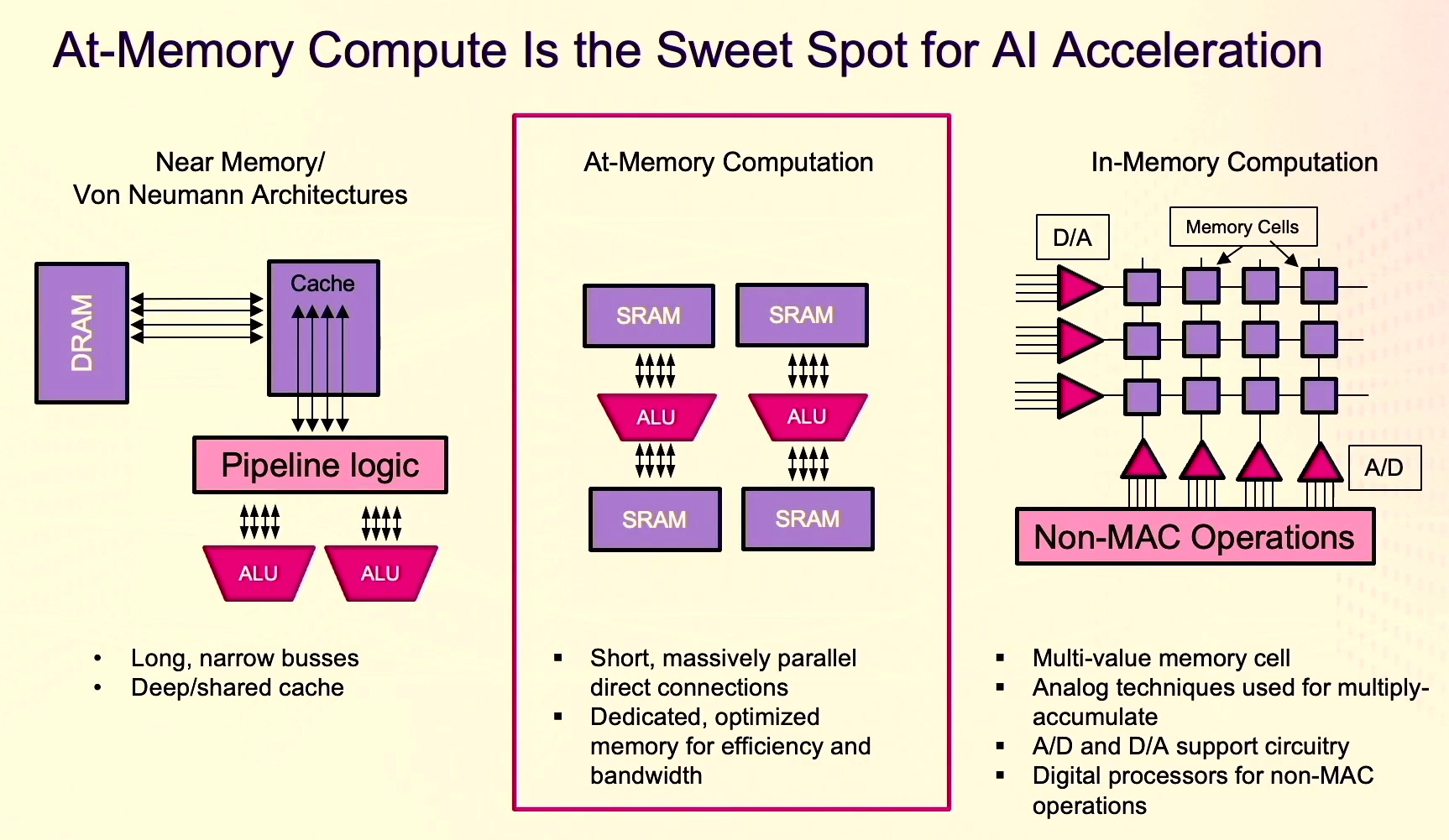
“We’re pioneering at-memory compute, where we place the compute element directly attached to memory cells. This is the sweet spot for AI acceleration,” he said, adding that with “at-memory compute we use a standard digital logic process, we use standard SRAM cells, but we provide tremendous energy efficiency because we have a very short distance for the data to travel from the storage cell to the actual compute element. … What we’ve done at Untether is really to [be] as efficient as possible in our data movement and put the compute where the data exists. We also architected our architecture to have the right amount of compute at the granularity level necessary and specifically tailored for acceleration of neural networks.”
For speedAI240 devices, Untether AI also is implementing two different AP formats – a 4-mantissa version called FP8p for precision and FP8r for range – the company says provides the best accuracy and throughput for inference across different networks, such as convolutional networks like ResNet-50 and transformer networks like BERT-Base. With these FP8 implementations, the company is seeing less than a 10th of 1 percent of accuracy loss when compared with BF16 data types and a four-times improvement in throughput and energy efficiency.
Foundational to the at-memory architecture are the memory banks. With Boqueria, the second-generation memory banks hold two 1.35 GHz 7 nanometer RISC-V processors, giving speedAI240 devices 1,435 cores. Each RISC-V manages four row controllers and each controller operates independently. Boqueria also includes external memory support with 32 GB LPDDR5 memory across two x64 ports and PCI-Express Gen5 interfaces for host and chip-to-chip connectivity.

Untether AI adapted the RISC-V chips by adding a variety of instructions to adapt them to the needs of AI inferencing, Bleacher said.

Martin Snelgrove, Untether AI’s co-founder and CTO, outlined the hierarchy of the speedAI architecture, from the low-power SRAM array and the processing element to the efficient data transfer design, which includes what it calls a communication design called a “rotator cuff” design to direct traffic within and between banks. There is a high-bandwidth network-on-chip (NOC) that runs around the periphery of the chip.
“That is not an off-the-shelf NOC,” Snelgrove said. “It’s designed for energy efficiency. Data gets sent the minimum possible distance, meaning at the minimum possible energy and any exploit manner that the manager chooses to set up.”
Beachler said that the spatial architecture for speedAI, which drives the ability for it to scale.
“We can reduce the number of memory banks that we have on given a chip to fit different form factors and power energy envelopes,” he said. “Within our whole Boqueria family, we’ll be scaling from some 1-watt devices all the way up to the B4 for infrastructure-class device. This allows us to address multiple different price performance points and form factors. We’ll be having a series of cards scaling from single-watt .m2 all the way up to PCI-Express. We have a very flexible I/O ring and that makes it chiplet-ready so that for those that want to integrate directly die-to-die with SoCs, we have that capability as well.”
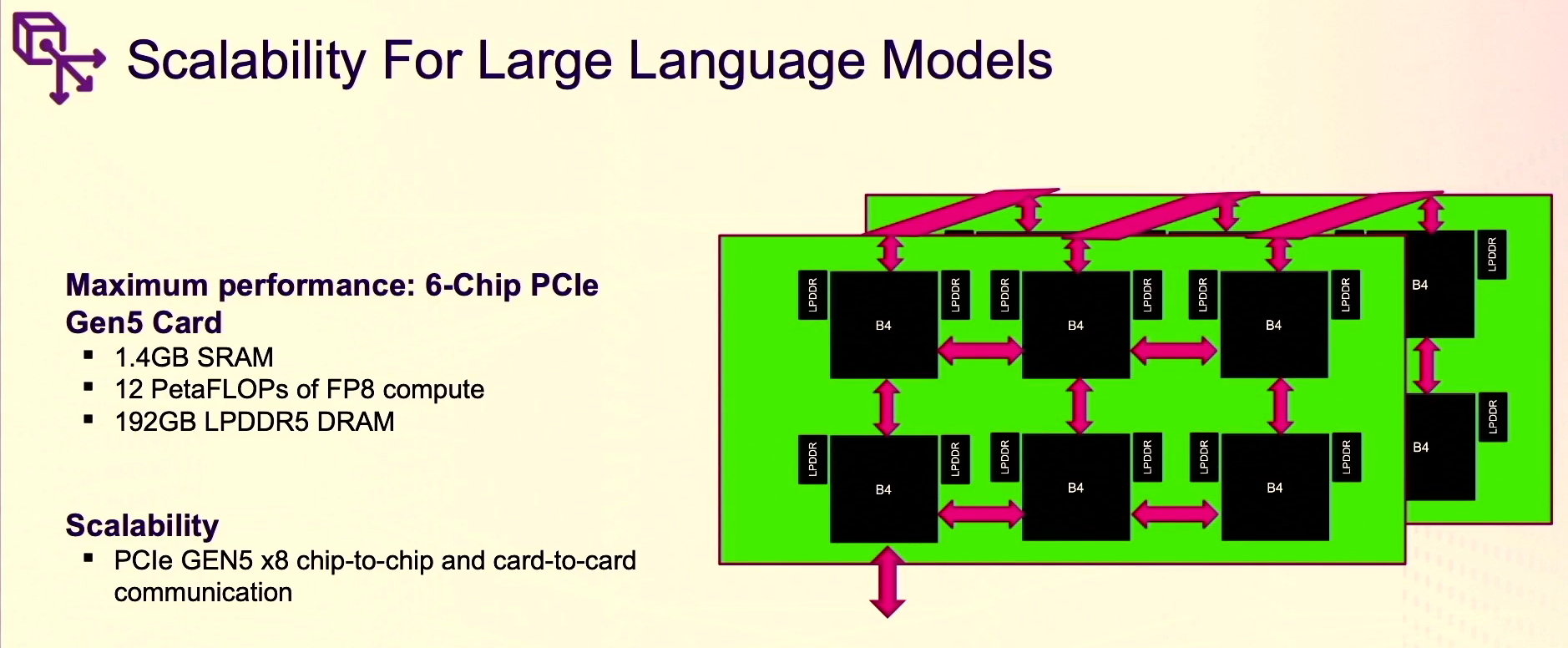
Untether AI will be able to fit six of Boqueria devices onto a single PCI-Express card, driving a large amount of SRAM capabilities to scale to the largest language models, he said, adding that “with our chip-to-chip and card-to-card interconnect, we can now make very powerful server implementations. We also have the external LPDDR 5 giving us a tremendous amount of storage on the chip. Overall, we have this scalability feature to allow us to provide the utmost performance as well as energy efficiency in the standard PCI-Express form factor.”
Also in the mix for Untether AI is its ImAIgine SDK that includes the capability to take neural networks from common machine learning frameworks like TensorFlow and PyTorch and “reduce it into the kernel code that runs on these RISC-V processors,” Beachler said. “We provide a model garden of pre-created neural networks, but the majority of our customers have their own neural networks that they’ve already trained. We provide automated quantization capability to reduce it into the data types required.’
The vendor also does the compilation and mapping to the kernel code, the physical allocation for placing kernels onto the silicon, and automatically interconnecting them. There also is a suite of analysis tools and, once the vendor has the programming files, it can put those into its chips and control it through a runtime that has a C- or Python-based API for integration into the enterprise’s larger machine learning frameworks.
It will be a while before most organizations will be able to get their hands on the speedAI offerings and before the company will see whether they will give it some separation in the AI inferencing space. Untether AI will begin sampling the speedAI240 devices and cards to early-access customers in the first half of 2023.


Further Funding Flows to Canadian AI Inference Hardware
AI inference hardware startup, Untether AI, has secured a fresh $125 million in funding to push its novel architecture into its first commercial customers in edge and datacenter environments. Intel Capital was a primary investor in Untether AI since its founding in 2018. When we did a deep dive on …

Server Inference Chip Startup Untethered from AI Data Movement
Standing out in the crowded server inference space is getting more difficult, especially at this late stage of the startup game. Not that this is anything new overall, but it takes many orders of magnitude to find a spot in the datacenter, especially with a new software stack. Untether AI, …
Samsung Shows Off CXL Server Memory Expander
People have been talking about CXL memory expansion for so long that it seems that it should be here already, but with the dearth of CPUs that can support PCI-Express 5.0 peripherals we have to be patient a little bit longer. To whet the appetite of system architects who will …
Be the first to comment