

Nearly all non-classified supercomputers are being touted as “AI supercomputers” with the favor falling to reporting FP16 performance numbers alongside traditional FP64 HPC figures. The latter have always defined the “top” supercomputer in the world, the former is being used to make big machines sound even larger.
While the world of traditional HPC is still striving to reach sustained exascale performance, the cadre of “AI supercomputers” have long since blown by the exascale designation, beginning in 2018 with the Summit system at Oak Ridge National Lab where the Gordon Bell prize went to a project that leveraged 2 exaflops of sustained FP16 performance.
Today, another system joins the ranks of both high-ranking traditional supercomputers (it will be roughly around #5 on the bi-annual Top500 systems ranking) while providing 4 exaflops of peak FP16 performance. This machine, called “Perlmutter” (after the Nobel-winning astrophysicist, Saul Perlmutter) will be based at the DoE-driven NERSC facility and will support a broad range of applications spanning analytics, simulation, and of course, AI/ML with the Nvidia A100 GPU and notable use of the TensorCore for both simulation and AI/ML work.
These peak performance projections are based off the first phase of the Perlmutter machine, which is being formally unveiled today, even though much has already been stated about the feeds and speeds. We know that the system will be based on the HPE Cray “Shasta” architecture with Slingshot interconnect with a mix of CPU/GPU and a massive 35 petabyte Lustre file system to help handle data movement. The I/O story is definitely one we are chasing since this will be a mixed workload machine if there ever was one, spanning traditional simulations with large-scale analytics and large-model AI/ML experiments, some with near real-time elements, including projects with large hadron collider/CERN.

The second phase of the machine will add far more CPUs to the mix, although it is not public what those will be. The best educated guess would be more of the AMD Epyc “Milan” CPUs. The system will launch with those as host CPU and it’s possible that NERSC could be in front of the line and get AMD “Genoa” as one of the first large-scale users but those won’t be officially launched until 2022. There’s a very outside chance it could be a custom core that the Frontier supercomputer will be getting.
Overall, the new Perlmutter machine will provide 3-4X the peak projected performance of the Cori supercomputer at NERSC. Recall that the Cray XC40 system was already poking at the possibilities of AI/ML for scientific computing in 2017-2018. We can expect many of these projects to carry forward onto the new machine, which will have big FP16/FP64 capabilities for handling mixed AI/ML/HPC—a long-held goal for NERSC and other supercomputing centers.
Dion Harris, Nvidia’s lead technical marketing manager for accelerated computing, says that NERSC has demonstrated the capabilities of mixed precision HPC/AI and now has the tools to take advantage of that peak potential. He adds that the year-over-year improvements in machines doing AI/HPC double duty doubles every year because of the intense efforts in optimization for applications and the software ecosystem.
Harris says that of the 600 applications in the mix at NERSC, around 60% have at least some form of GPU acceleration. He adds that for the long tail of those non-accelerated applications, they’ll be beefing up the HGX AI supercomputing platform with its SDK that allows developers to onboard GPUs via OpenACC, C++, and Fortran hooks.
Around 2012, Nvidia coined the phrase “accelerated supercomputing” and could make its own GPU the center of the HPC performance story, even at a time when relatively few of the largest systems had enough applications ported to justify a big GPU investment. The performance capabilities they could tout sounded (and were) big and pushed the entire HPC ecosystem, slowly but surely, in its own direction. It allowed the Linpack/HPL numbers for Top 500 to increase massively and, arguably, pushed the performance curve we’ve come to expect from HPC faster than it would have gone otherwise.
These days, Nvidia is doing the same thing. Instead of “the era of the accelerated supercomputing” it’s now the “era of AI supercomputing” and that designation belongs to Nvidia almost exclusively. They are taking a central role in the performance story of this and other large machines—and rightfully so. But make no mistake, anytime you hear “AI supercomputer” you can be certain it’s an Nvidia GPU systems story.
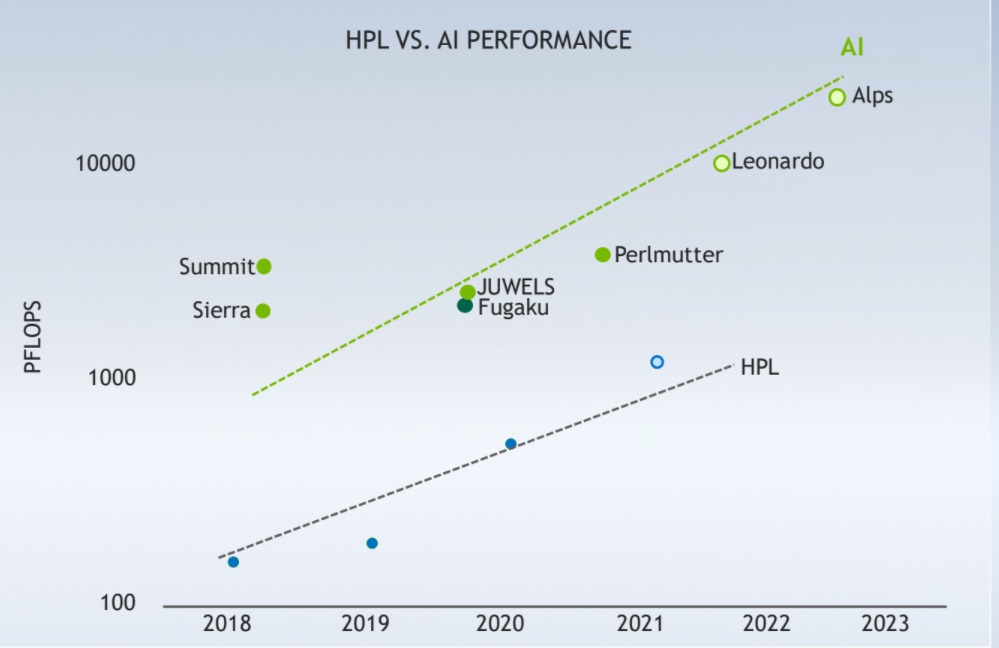
The machines above show just how much more impressive and fast-paced AI versus HPC innovation is becoming. Yes, there is progress on traditional HPL/HPC workloads but it’s nothing like the pizzaz of that sharp incline, even if it’s “just” FP16—something that most traditional supercomputing applications can’t take advantage of without a lot of work–and some centers are doing that work now.


A 35 Petabyte All-Flash Balancing Act
Last week, we introduced the Perlmutter supercomputer, the next-gen system at NERSC that will likely secure the #5 spot on the Top 500 list of the world’s most powerful machines. In that piece we kept the conversation about compute and capabilities but the real star of the show is in …
Berkeley Lab Opens Bidding For Future NERSC-10 Exascale System
The National Energy Research Scientific Computing Center at Lawrence Berkeley National Laboratory, one of the key facilities of the US Department of Energy that drives supercomputing innovation and that spends big bucks so at least a few vendors will design and build them, has opened up the bidding on its …
1. Can it find out how the various strengths of gravitational force of those heavenly bodies can maintain synchronicity, harmoniously that they don’t scatter-disarrayed WITHOUT any help of OUTSIDE UNSEEN POWER ?
2. Can it trace back in history that the universe movement once FROZE (Joshua 10:12, 13), and it even spun-back during Judah king Hezekiah ? As corroborated by sky-gazers Babylonians (2King 20:11 – 13)
During mid 1970s archeologists&historians found out that Mayan tribe of So. Amer., their calendar begun in the 500s AD.
After calculating the solar-system movement it was reported that they found out that in one season in the 500s AD all the 9 planets position was on one plane, though not in 1straight-line.
In1970s there was no ‘super-computer’