
If money and time were no object, every workload in every datacenter of the world would have hardware co-designed to optimally run it. But that is obviously not technically or economically feasible.
Just the same, sometimes a workload is so important that it warrants a highly tailored system to run it. And that is precisely what Cadence Design Systems has done with its new M1 supercomputer, which you can either rent a slice of or buy for your own datacenter if you want to run computational fluid dynamics at large scale and high speed.
Cadence is three and a half decades old and is perhaps best known for its electronic design automation (EDA) software for designing chips. Over the decades, Cadence has done over three dozen acquisitions to build out its simulation portfolio covering myriad aspects of circuit, board, and system design and testing for both analog and digital circuits. At the same time, Cadence has been moving up the simulation stack, adding its Celsius thermal emulator, which used a mix of finite element analysis (FEA) and CFD, and has since that time built or bought other CFD solvers to take on the likes of Ansys, which is in the process of being acquired by EDA rival Synopsis for $35 billion. And importantly, simulation itself has been getting more sophisticated with the advent of multi-physics simulation, which brings together the particle physics, thermodynamics, electromagnetic, and mechanical properties of designed devices all together to create a more complete rendering of that device.
All of this takes a lot of compute, and to minimize the amount of compute as well as tune up the hardware running the software – and thereby make customers happier than they might otherwise be – Cadence is essentially entering the supercomputer business and the cloud business at the same time.
Cadence is calling the resulting stack the Millennium Enterprise Multiphysics Platform, and the its first generation of AI-assisted CFD software that runs on it is called M1, which is a GPU-resident version of the large eddy CFD simulator from its Fidelity CFD suite. And with the combination of the two, Cadence is hoping to provide two orders of magnitude improvement in the accuracy, speed, and scale of CFD simulations among the aerospace, defense, automotive, electronics, and industrial customers who rely on CFD for parts of their product, system, or facility designs. And through the use of GPU accelerators for that simulation software, Cadence says that customers will see a 20X improvement in the energy efficiency of their simulations.
It is reasonable to assume that other Cadence software will eventually be ported to the Millennium systems so that EDA, FEA, CFD, and other simulations can work in concert as part of an overall design.
No Stranger To Hardware
The Millennium platform is not the first foray into specialized hardware to run software for Cadence. In 2014, Cadence created a prototyping system that took output from its EDA tools to simulate chip designs on massive clusters of FPGAs from Xilinx, which was called Protium, and that system has been updated and expanded four times in the past decade, increasing the speed at which gates could be compiled and the scale of the designs it could emulate.
In 2015, a more generic FPGA-based hardware emulator from Cadence called Palladium was launched, and was able to absorb billion gate designs, run them at 1 MHz (which was pretty good, believe it or not), and compile the high level synthesis design of an ASIC down to the FPGA at a rate of 100 million gates per hour. The latest Palladium system, called Z2, can compile 10 billion gates in 10 hours, or do about 10X the rate of the original Palladium Z1 hardware, and can span designs with more than 18 billion gates.
The Millennium supercomputer is different in a few ways. First, it is based on CPU hosts with GPU accelerators with high speed interconnects, much as any other AI and HPC supercomputer is these days. Cadence is not pushing any particular set of compute engines or interconnects, and is not revealing its reference designs that might tell us what its choices are, because it does not want to pain itself into any particular hardware corner. Which is reasonable given the difficulty of getting GPU allocations these days.

That said, it is reasonable to assume that Cadence has chosen Intel Xeon SP and AMD Epyc server processors for hosts and Nvidia A100 and H100 and AMD Instinct MI250X and MI300X accelerators as the main compute oomph in the Millennium system. It is also reasonable to assume InfiniBand is a preferred interconnect, but Ethernet is an option for those who want to go that route.
The hardware is interesting, but what Cadence says is more important is that the solvers at the heart of the Fidelity M1 large eddy simulator – which models turbulence in combustion, atmospheric flows, acoustic vibrations, and other turbulence sources – are resident in the GPUs. That means the M1 code is running natively on the GPUs in its entirety and, unlike many other GPU-accelerated applications, is not having snippets of parallel processing offloaded from the CPU to the GPU and the results brought back into the CPU for the rest of the simulation.
“GPU computing in CFD is still quite new,” Alex Gatzemeier, product management director for CFD at Cadence, tells The Next Platform. “Most of our customers, and basically most of the industry, is still relying heavily on CPU-based HPC systems. CFD is not the same size and scale as AI is on GPUs today, but it is still difficult to get GPUs, it’s difficult to tune them to scale across say ten or twenty nodes in the cloud. That’s still a challenge. Millennium provides a turnkey solution. So there’s no it overhead, you can basically go to the cloud and start in minutes. Or you get Millennium shipped to your own datacenter, you connect as many nodes as you need.”
You might be thinking that among the big aerospace companies, the big defense contractors, and the big auto makers that they would have hundreds of thousands or even millions of cores running their CFD simulations. But Gatzemeier says that at a large automaker, for instance, a typical customers has tens of thousands of cores in an all-CPU cluster running CFD, and that the typical job runs on a few thousand cores over a few days to maybe a week.
With the Millennium system, a single rack of machinery with 32 GPUs will deliver around 150 million core-hours per year, which is roughly equivalent to the typical CPU-based CFD cluster out there. And because the Millennium system can scale across many racks – and even rows if you want to really do a lot more CFD work a lot faster – it can scale even further. Out to 5,000 GPUs and beyond, in fact.
Here is some scaling data that Cadence is showing off on an early edition of the LES solver running on the “Summit” supercomputer at Oak Ridge National Laboratory:
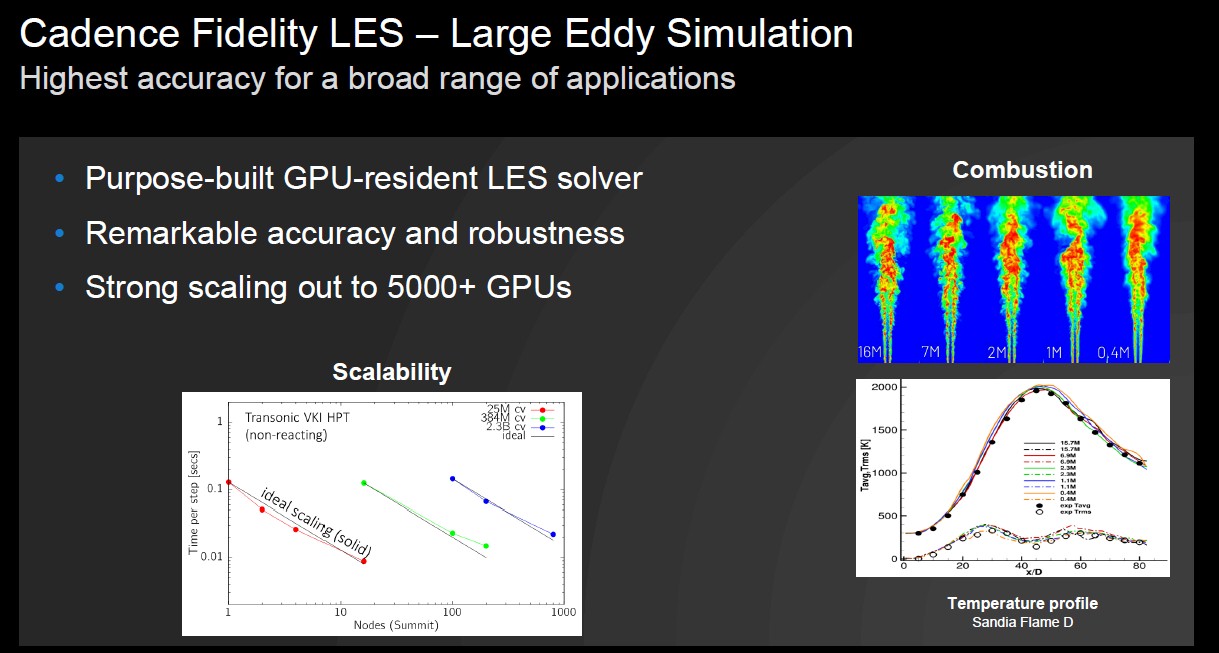
The curve on the right, if you zoom in on it, shows how well the LES solver predicts temperature over different grid scales.
This one shows the scalability within a single rack as GPUs are added to the M1 software:
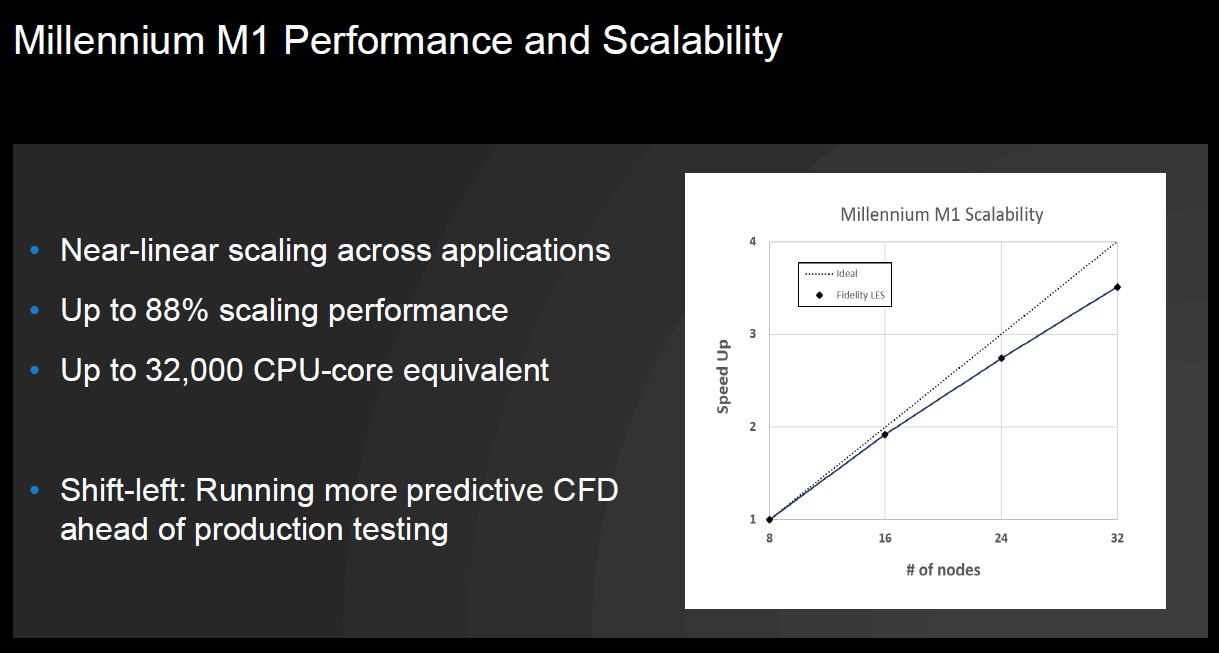
This 32 GPU cluster has the equivalent performance on the CFD code as about 32,000 X86 cores, says Cadence. What this means is that customers can now do more CFD, or start doing predictive CFD as part of the design process and make changes to designs that will benefit that design before a mockup goes in for wind tunnel testing. This is what the “shift left” in the chart means, and it is akin to DevOps shifting left the testing of code long before it is put into qualification and production.
By the way, the Millennium machine is running bare metal Linux and the software is not containerized at all. It runs like any other parallel HPC application does without all of that jazz. But if you want to throw Kubernetes on top of it and pod up different kinds of work on the supercomputer, you can do that.
The Millennium supercomputer is available for order now, as are slices of it on the cloud that Cadence is hosting in its own datacenter in San Jose. Pricing was not divulged, but we sure are curious. . . .


TACC Fires Up “Vista” Bridge To Future “Horizon” Supercomputer
The Texas Advanced Computing Center at the University of Austin is the flagship datacenter for supercomputing for the US National Science Foundation, and so what TACC does – and doesn’t do – is a kind of bellwether for academic supercomputing. So it is noteworthy that TACC is installing its first …

AMD Previews “Turin” Epyc CPUs, Expands Instinct GPU Roadmap
Computex, the annual conference in Taiwan to showcase the island nation’s vast technology business, has been transformed into what amounts to a half-time show for the datacenter IT year. And it is perhaps no accident that the CEOs of both Nvidia and AMD are of Taiwanese descent and in recent …
AMD Moves Up Instinct MI355X Launch As Datacenter Biz Hits Records
When we first started The Next Platform a decade ago, there was not really much of a reason to cover the company’s datacenter efforts. But, we are a hopeful people here at what was originally called The Platform, and from the get-go we knew that the market needed competition for …
Be the first to comment