

While securing the high-end particle physics market segment is not likely to push any of the AI/ML ASICS into competition with GPUs anytime soon, the chipmakers that can prove their value on some of the most demanding, real-time AI workloads can capture some serious mindshare.
All of the leading AI chip vendors have recognized the benefits of pushing to get early systems into national labs, from SambaNova to Cerebras, to Graphcore. Having accelerators in these environments serves several purposes, including academic assistance with maturing software stacks and of course, the bragging rights of running alongside some of the largest supercomputers.
We talked earlier in January about Graphcore systems at the University of Bristol and the reasons why the university selected their architecture here and now have more details on the collaboration with CERN that is showcasing what Graphcore’s MIMD-based IPU accelerators can do at scale in one of the most intense real-time HPC environments. Based on work with the Bristol research team, for particle physics work at CERN, their own tests indicate that “the IPUs hold considerable promise in addressing the rapidly increasing compute needs in particle physics.”
With that said, CERN has already invested heavily in Nvidia GPUs in a recent upgrade for its GPU-based High Level Trigger facility. The Allen machine will support the computation for the upgrade of the LHCb deterctor across 500 Nvidia A100 (we are assuming this generation based on the requirements and performance projections here) GPUs. CERN has also been out front with its use of FPGAs, both in the network and for compute, although these projects have not yielded the kind of investment we’re seeing with the LHCb project. The fact is, the facility has always been open to investigating emerging and novel hardware to fit its unique workload requirements, and that CERN is taking a gander at Graphcore compared to GPUs is not surprising.
Part of what is interesting about the Graphcore, CERN work is that new workloads are being explored, including the use of generative adversarial networks (GANs) to essentially fill in pieces of missing information and use data from simulation to aid in the synthesis of ongoing workloads. Much of the CERN/Graphcore/Bristol evaluation is focused on GANs given its growing role at the particle physics facility.
Newly proposed experiments will continue to demand a rapid increase in the number simulated events. The ongoing optimization and parallelization of traditional event generation software will at best result in an order of magnitude reduction of resources. This reduction is not sufficient to meet ever increasing simulation demand. Estimates forecast a fourfold shortfall of computing power within the next 10 years without significant new investment. This has catalyzed efforts to develop faster simulation and event generation technologies of which GANs are currently a front runner. GANs or other generative network architectures are likely to become an integral part of a future fast simulation tool kit.
In addition to GANs, the team’s tests are based on several workflows important for the Large Hadron Collider with codes implemented in both PyTorch and TensorFlow. The architecture of Graphcore’s first-generation Colossus MK1 IPU used for this work is shown below. Unfortunately, the work was being prepared when Graphcore released the MK2, so the results are a bit out of date but do show what’s important here—the architecture itself is a fit for real time processing that blends traditional HPC simulation and machine learning approaches.
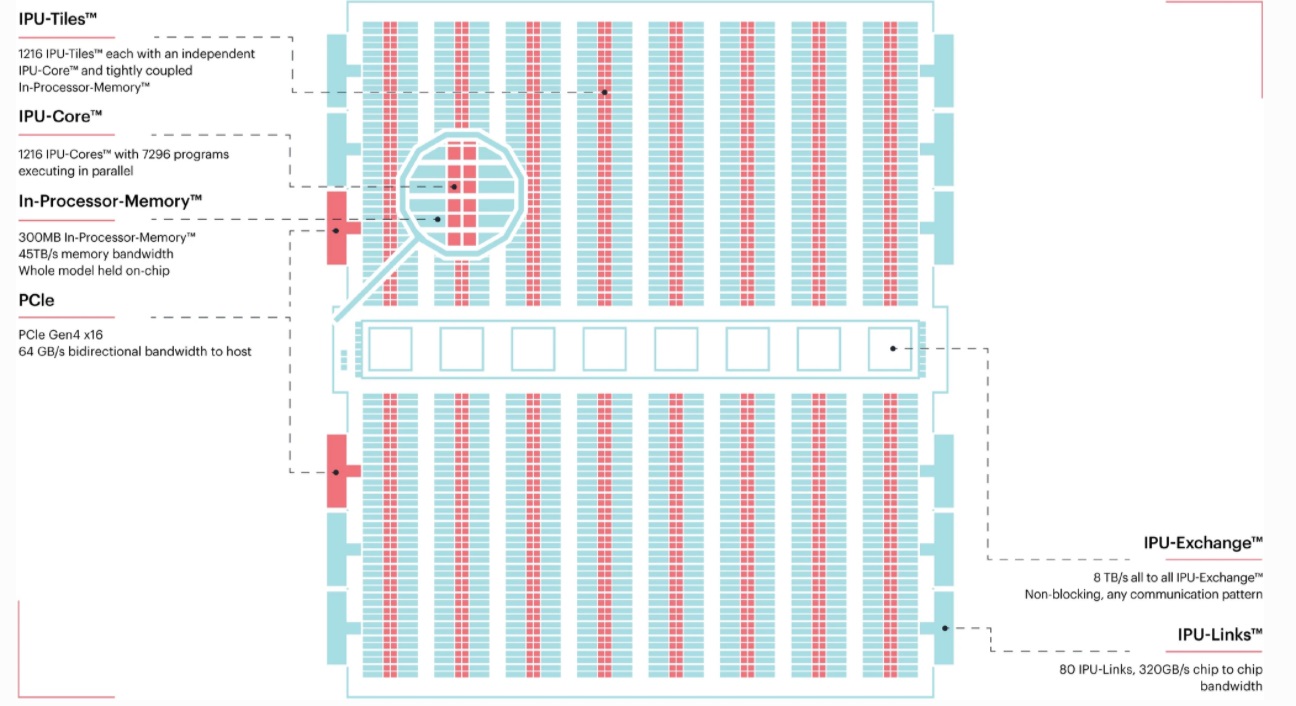
The IPUs used here are integrated into a Dell DSS8440 IPU server containing eight dual IPU cards. This server includes two Xeon Platinum 8168 CPUs with 24×32 GB 2.4 GHz DDR4 DIMM Modules. Graphcore also provides drivers along with its Poplar Software Development Kit (SDK). Updates to both the drivers and SDK can result in improvements to the IPU performance. This work relies on SDK version v1.2.0.
The full paper that describes the work and benchmarking between GPU and CPU can be found here. We are not republishing the images because in our mind, they do not reflect the best of breed hardware for any vendors. For instance, the GPU results are benchmarked on the P100 and the Graphcore hardware is not the latest either. The benchmarks are not necessarily what’s important here. What matters most is seeing where the opportunities are for CERN and other physics and HPC workloads over GPUs more generally—in ways that are not dramatically changed with addition of incremental bandwidth or compute for GANs. It all comes down to batch size handling.
For batch sizes accessible to both processors, the IPU out-performs the GPU, in some cases by orders of magnitude. For GAN event generation, large batch sizes are usually optimal. Here, the “larger memory capacity of the GPU, allowing larger batch sizes, can be a decisive advantage. This is the case for the fully connected GAN architectures studied; for the convolutional- and locally connected GANs, the IPU generates events faster than the GPU despite using a smaller batch size.” Remember too that the MK2 from Graphcore has 3X the memory allocated for each tile compared to the MK1 used in this work.
Despite some of the programming hiccups the Bristol hardware/software evaluation team described here, those who focused on the GAN work for CERN add that programmability is just as important as performance. They say that everything in the full CERN workload paper was written within less than 6 months of the group’s first access to Graphcore’s IPUs, by a small team of particle physics postdocs and Ph.D. students with no prior experience of IPU programming.
“This first investigation of IPUs in a particle physics context suggests that IPUs, due to a combination of performance, flexibility and ease of programming, have the potential to play a central role in meeting the fast-increasing compute needs of particle physics. As promising as these results are, they can only be a starting point that motivates further, detailed study using realistic particle physics workflows,” the team concludes.

Chip Makers Press For Standardized FP8 Format For AI
In March, Nvidia introduced its GH100, the first GPU based on the new “Hopper” architecture, which is aimed at both HPC and AI workloads, and importantly for the latter, supports an eight-bit FP8 floating point processing format. Two months later, rival Intel popped out Gaudi2, the second generation of its …

Graphcore Right on the Money in First MLPerf Appearance
When it comes to a silicon startup bringing a product to market in a tough competitive landscape, nothing is easy. The list of challenges is long but to be taken seriously against the incumbents, a strong MLperf showing is now paramount. As usual, Nvidia and Google swept the MLPerf results …

Next-Gen Insurers Are Going to Need (Way) More AI Horsepower
While involving AI/ML in the complex process of insurance claims now might be piecemeal, the future is bright for insurers to speed time to claim resolution by using image-based data and machine learning models to understand the scope of damage to vehicles or eventually, entire geographic regions. Tractable, a UK-based …
Be the first to comment