

A group of researchers at Sandia National Laboratories have developed a tool that can cross-train standard convolutional neural networks (CNN) to a spiking neural model that can be used on neuromorphic processors. The researchers claim that the conversion will enable deep learning applications to take advantage of the much better energy efficiency of neuromorphic hardware, which are designed to mimic the way the biological neurons work.
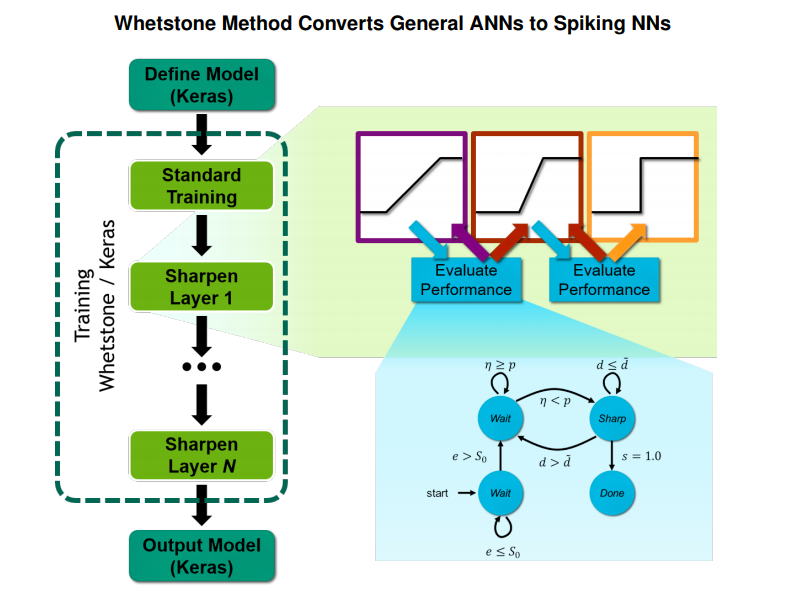
The tool, known as Whetstone, works by adjusting artificial neuron behavior during the training phase to only activate when it reaches an appropriate threshold. As a result, neuron activation become a binary choice – either it spikes or it doesn’t. By doing so, Whetstone converts an artificial neural network into a spiking neural network. The tool does this by using an incremental “sharpening process” (hence Whetstone) through each network layer until the activation becomes discrete.
According to Whetstone researcher Brad Aimone, this discrete activation greatly minimizes communication costs between the layers, and thus energy consumption, but with only minimal loss of accuracy. “We continue to be impressed that without dramatically changing what the networks look like, we can get very close to a standard neural net [in accuracy],” he says. “We’re usually within a percent or so on performance.”
In a paper to be presented later this month at the annual Neuro-Inspired Computing Elements (NICE) Workshop, they documented a test case in which they achieved 98.1 percent accuracy for a 47,640-neuron CNN using the MINST dataset containing images of handwritten digits.
In most cases, the final trained network is portable across different neuromorphic platforms, which is one of its primary advantages. All the current work in this area – the University of Manchester’s SpiNNaker project, IBM Research’s TrueNorth processor, Brainchip’s Akida Neuromorphic System-on-Chip, and Intel’s Loihi – are, for the most part, using proprietary software technologies for application development.
As Aimone says, the neuromorphic computing field is like GPUs before CUDA came along, says – pretty much the Wild West. By offering a standard hardware-agnostic cross-trainer, the hope is that the community will be able to share development efforts more widely and create the beginnings of a neuromorphic software ecosystem.
The initial Whetstone work relied on SpiNNaker hardware (a 48-node, 864-core board), but the Sandia researchers hope to get access to the Loihi platform in the near future. TrueNorth is another option, although the architecture has a more unconventional design that would make porting more complex.
Since all training is performed in a conventional deep learning environment, the researchers have access to a rich ecosystem of tools and frameworks to work with. In the initial work, they used TensorFlow and CUDA on Nvidia GPU-accelerated hardware. The researchers also used Keras, a high-level neural network library, as a wrapper around the lower-level training software.
As a result of the additional processing, training times are longer, however. According to the researchers, they used “about twice as many training epochs as one normally would,” although this depends on a number of different factors. In the future, they hope to optimize the workflow to reduce the time penalty.
Training times aside, the primary goal of this work to be able to leverage standard deep learning technologies to produce inferencing software capable of running in a much lower power envelope when deployed. Not only would this allow these types of applications to be suitable for low-power edge or consumer devices, but could also enable web giants like Google, Facebook, and Baidu to curb their datacenter energy needs when serving up their own deep learning applications. Likewise, power-hungry supercomputers employing machine learning in their workflows could also benefit.
“I think it’s not too long before it’s feasible to have neuromorphic hardware embedded on traditional HPC or datacenter racks,” suggests William Severa, the lead mathematician on the project. That said, he notes that you actually don’t need neuromorphic hardware, per se, to take advantage of Whetstone’s spiking model. “We’re really just pushing around 1s and 0s to activate it,” he explains. So conventional, non-neuromorphic hardware, like GPUs or CPUs would work as well and it would be more energy efficient than relying on the vector-based network communication that’s at the heart of traditional deep learning.
At this point, the principle limiting factor is the lack of commercial neuromorphic hardware or, as just suggested, the lack of conventional hardware optimized for light-weight communication with low precision vectors. If the Whetstone technology proves to be feasible and more broadly applicable, it’s conceivable that chipmakers will incorporate such designs into their own processors.
In the future, the researchers plan to refine the Whetstone technology. Besides developing a port to the Loihi platform, they also would like to extend the tool to work with recurrent neural networks (RNNs), speed up the training runs, and work on integrating the software into a training workflow in a plug-and-play fashion, such that retargeting to different platforms would become transparent.
The researchers are also thinking about how to mimic the brain’s use of spiking as a temporal process to increase the tool’s capability. “If we could figure out how to make Whetstone capture the brain’s use of time as a kind of a computational device, we could probably make it even more efficient,” Aimone explains. “But that’s a fairly big research challenge.”


Sandia Deploys SpiNNaker2 Neuromorphic System
Some heavy hitters like Intel, IBM, and Google along with a growing number of smaller startups for the past couple of decades have been pushing the development of neuromorphic computing, hardware that looks to mimic the structure and function of the human brain. It’s a subject that The Next Platform …

A First Look at Intel’s Next-Level Neuromorphic Engine
Intel is still placing bets on neuromorphic computing with its Loihi devices. While the datacenter hook for the architecture might take a second seat to embedded and edge use cases, at least for now, its second generation device shows commitment to the concept — as does the new open-source software …

On the Fringes of Useful Neuromorphic Scalability
When it comes to novel computing architectures, whether in quantum, deep learning, or neuromorphic, it can be tricky to get a handle on how incremental improvements in processor counts translate to real world improvements since these bumps in element counts often don’t have perfect parallels to CPUs or even GPUs. …
It is a very interesting article. Today is my first day when I heard the term neuromorphic and still, I was able to read and understand it. At least that is what I think.
Does it mean that I could use Keras and run CNN or RNN model on the GPU and use discrete activation function as mentioned? Is there any tutorial about it.