
VMware is not the first company that comes to mind when you think of GPU computing, but the company has quietly been developing technologies that enables performance-minded users to get the most out of these born-again vector processors. A presentation at the 2019 Stanford HPC Conference, showed how VMware’s ESXi hypervisor is able to run machine learning workloads on virtualized GPUs, while running at speeds that approach that of bare metal.
In fact, according to VMware’s Mohan Potheri, the use of virtualization can actually make these GPUs more productive than they would otherwise be in a native environment. That’s because virtualization, the foundational technology for private and public clouds, is able to provide greater flexibility, simplicity, and security than you would encounter in a non-virtualized environment.
Those advantages are why 60 percent to 70 percent of datacenter workloads are now virtualized, a large portion of which is chopped up and consolidated using ESXi hypervisor and vSphere add-on tools, which unlock capabilities inherent in the hypervisor. The remaining percentage that is not virtualized includes the lion’s share of HPC workloads, and that’s the opportunity that VMware sees in pursuing these computationally-intense workloads. Choosing machine learning as its proof-of-concept test case for this technology more than likely reflects the interests of VMware’s enterprise-focused customer base, not to mention the fact that there already is a lot of this type of work already taking place in virtualized cloud setups today.
For customers running machine learning, or any other high performance computing workload, the main hurdle VMware has to overcome is the performance penalty associated with virtualization, since these are the kinds of users that are loathe to sacrifice computational speed. Most of penalty occurs because a hypervisor has been added to act as an intermediate layer between the virtual machine and the hardware, in this case, Nvidia GPUs. Such an intermediary typically incurs some overhead, since it has to negotiate between system requests on the application side and resource availability on the hardware side.
But overhead is not foregone conclusion for virtualization and VMware has apparently been able to eliminate its major sources in its own ESXi hypervisor. In particular, the vSphere management layer for ESXi does not act as an intermediary when accessing GPUs.
“The myth is that virtualization is a layer that is on top of the GPU and it’s going to slow you down,” says Potheri. “That’s not true.”
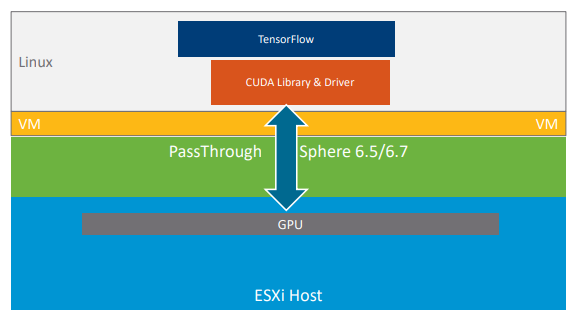
VMware has gotten around this with a few additions plus a couple of third-party technologies. One of the additions is actually a subtraction, namely turning off vMotion. Normally, this feature is used to constantly shuffle VMs around to different servers in order to do load balancing across a system. For this type of compute-intensive work though, you want to minimize overhead, so shutting off vMotion forces a virtual machine to stay on the same physical GPU for its entire lifetime.
A key piece of vSphere technology that minimizes VM-hardware interaction is something called DirectPath I/O. In general, it enables a VM to access hardware directly, creating an unobstructed path through the hypervisor between the driver and the device. In this specific case, the CUDA driver that’s been hooked into the VM is able to talk directly to the GPU.
The DirectPath I/O method by itself only works if you have a single virtual machine talking to one GPU. If the VM needs more than one GPU, VMware folds in Bitusion’s FlexDirect technology, which enables the hypervisor to attach and manage multiple GPUs.
On the other hand, if you want to share a single GPU across multiple virtual machines, the hypervisor incorporates Nvidia’s GRID virtual GPU (vGPU) technology, which provides the smarts to carve up the graphics device. Note that only the GPU’s local memory can be split up, not the computational cycles.
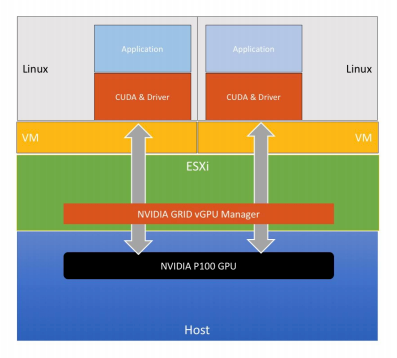
Training a language model using TensorFlow across the different use cases describe above, resulted in performance hit of only three or four percent compared to a bare metal implementation, according to Potheri. In fact, the same performance penalty held for both the DirectPath I/O and vCPU technology. For that slightly reduced throughput, you get the flexibility of using a shared resource and the security inherent in virtual machines.
VMware also did a test project where they married their hypervisor with Singularity, a container technology specifically designed for HPC workloads that has proven popular within the community. But sharing hardware in a container is not so simple, which means much of resource can be wasted. So VMware set out figure out how that the container could be virtualized. As much as that sounds like an oxymoron, the container’s ability to make applications more portable, along with the VM’s ability to operate seamlessly in a shared environment, sounds like an attractive package.
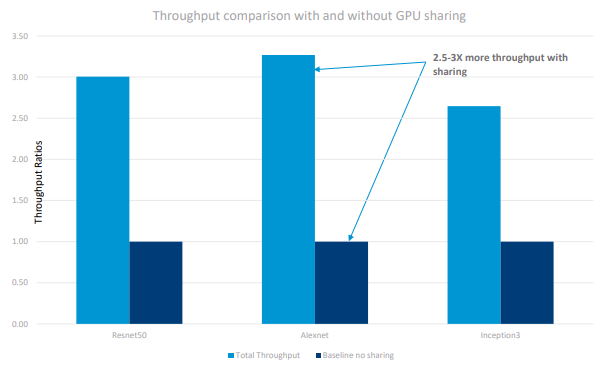
To accomplish this, VMware leaned on the BitFusion technology plus the DirectPath I/O passthrough facility. Embedding a single Singularity container per VM, they proved a GPU could be shared in such an environment. The test case used a TensorFlow-based image processing application that required only a portion of a GPU to executed. The GPU was divvied up into four pieces, running a vSphere-Singularity VM on each piece. Even though each job ran 17 percent slower than one using the entire GPU, throughput increased up to three times thanks to better resource utilization.
In another test case, they used the vGPU technology to harvest unused compute cycles at night for machine learning workloads. During the day, the GPU servers were used for graphics work by design engineers and data scientist in a virtual desktop infrastructure (VDI). At night, after the staff went home, the servers switched over to machine learning batch jobs, using the suspend/resume facility of the virtual machine.
Even though VMware used machine learning as basis for this work, the component GPU technologies do not appear to be dependent on any particular application category. That would imply that these same vSphere elements and its companion products could be applied to more traditional HPC science and engineering workloads that can take advantage of GPU acceleration. Whether VMware is interested in going after such customers remains to be seen.

Dell Sets Up For A Killer Spike In AI Server Sales
Back in February, Dell, the world’s largest server maker, told Wall Street that it was planning on selling and delivering $15 billion in AI servers in its fiscal 2026, when will end in early November. Sales were a little more tepid than we and many on Wall Street had expected …

The Tidal Wave Of Rising GPU TAM Raises All Boats
The world has gone nuts for generative AI, and it is going to get a whole lot crazier. Like $400 billion a year in GPU hardware spending by 2027 crazier. If you don’t think this is an enormous amount of spending, consider that the US Department of Defense, which is …

Oak Ridge Trials Arm-GPU Combo On HPC Testbed
The GPU has become a standard platform for accelerating high performance computing workloads, at least for those that have had their code tweaked to support acceleration at all. Up until recently though, the majority of that acceleration has taken place on host systems using Intel Xeon or IBM Power processors. …
Thanks for the great article. Appreciate you highlighting some of the work we have done in VMware. I just have a small correction. “The DirectPath I/O method by itself only works if you have a single virtual machine talking to one GPU.” is not totally accurate. Direct Path I/O method works for a single virtual machine only, but it can attach to one or more GPUs. You mention one GPU that needs to be changed to one or more GPUs. Thank you again for your excellent article