

The idea of a “private” file system—one that runs within a user’s specific job and is tailored to the I/O requirements of a particular workload—is not necessarily new, but it is gaining steam given changing hardware capabilities and workload demands in large HPC environments.
This concept of the ephemeral or ad hoc file system might have been around for a while (and has even been included as part of some file systems, including BeeGFS with its BeeOND functionality, for instance) but it will become an increasingly important part of the storage stack, serving a supplementary role to Lustre and GPFS, which will excel at general purpose functions.
Whether it is called a private file system or some other variant, work on large supercomputers like Sierra at Lawrence Livermore National Lab where the demands of new workloads and the ability to tap into more storage media is yielding new insight about the power of a job-focused supplementary, or private, file system.
 This work, which is captured in the Unify file system, is being led by Kathryn Mohror who head’s the lab’s data analysis group.
This work, which is captured in the Unify file system, is being led by Kathryn Mohror who head’s the lab’s data analysis group.
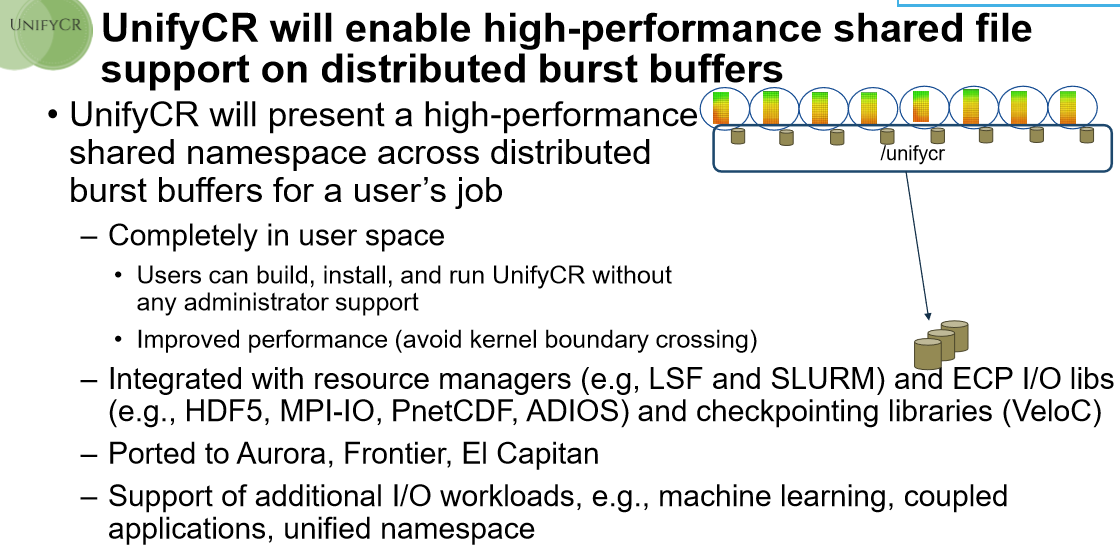
“What we want to do are these very lightweight file systems that are intended to be run only within a user’s job. These private file systems can capitalize on storage that’s available on compute nodes, including memory or burst buffers, and they’re private to the user’s job and tailored specifically to the I/O workload of that job. This way we don’t have to support the entire compute center, only that user’s job, which means we can relax the requirements that the general purpose implementations have to adhere to.”
“I’m always impressed by Lustre and GPFS but their general purpose capabilities get in the way of performance,” Mohror adds.
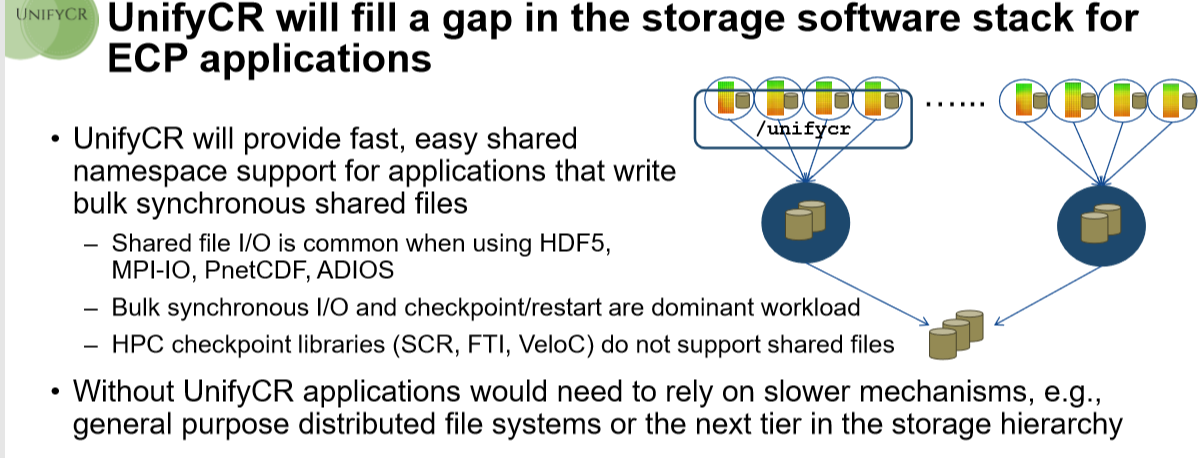
“Hierarchical storage systems are the wave of the future for high performance computing (HPC) centers like LLNL’s Livermore Computing Complex. The Unify project aims to improve I/O performance by utilizing distributed, node-local storage systems. This design scales bandwidth and capacity according to the computer resources used by a given job. Furthermore, Unify avoids inter-job interference from parallel file systems or shared burst buffers.”
With the addition of more burst buffers into large supercomputers comes the ability to have more storage devices to extract capacity from. Further, that change in workloads from predictable to more mixed is also pushing the limits of traditional HPC file systems like Lustre and GPFS. “It is no longer just about write-heavy output I/O for things like checkpoint/restart or generating visualizations, for example. Now we have these machine learning analysis workloads coming into play that are very read-heavy and have different needs for in situ analysis. So where a traditional HPC simulation sends output files to other compute nodes in the same allocation off to the side, we’ll read that data and then do some analysis inside the job,” Mohror explains.
“These file systems will always be critical to HPC infrastructure. We are going to need to store data long-term but we find there is a lot of output being generated by HPC workloads that is temporary in nature and does not need to go all the way out to the parallel file system. That’s where something like Unify sits—it is inside the user’s job on the compute nodes, managing the temporary data with high performance only for when it’s needed during the job. Then whatever is not needed is sorted out to the parallel file system or even an object store at the end of the job, or even periodically during.”
At the moment, Unify is mostly a research prototype that users of the burst buffer bearing Sierra supercomputer can experiment with. The work is being done in conjunction with the Exascale Computing Project (ECP) and in its second year is recruiting users to test their workloads. Mohror expects that over the next year they will have a solid user base to experiment and build it out further.
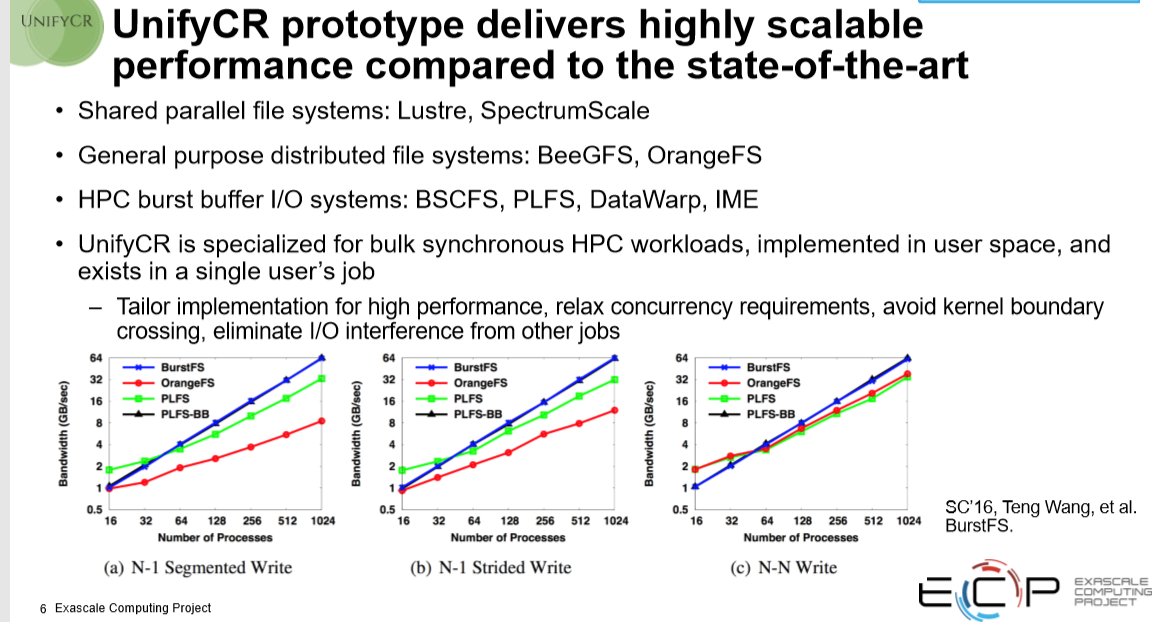
While this might just be research for now, it is important work because there are mounting limitations with the current general purpose file systems as workload demands evolve. We have already talked to a number of companies and researchers recently about how and where some HPC file systems are failing for workloads like integrated AI, for instance, and some of the hardware and software workarounds from vendors and users alike.
More can be found at GitHub here.

Be the first to comment