
Ever since the “Aurora” vector processor designed by NEC was launched last year, we have been wondering if it might be used as a tool to accelerate workloads other than the traditional HPC simulation and modeling jobs that are based on crunching numbers in single and double precision floating point. As it turns out, the answer is yes.
NEC has teamed up with Hortonworks, the spinoff of Yahoo, where the Hadoop data analytics platform was created based on inspiration from Google’s MapReduce and Google File System, to help accelerate both traditional YARN batch jobs and Spark in-memory processing jobs running atop Hadoop. The partnership between the two, which will presumably carry over once Cloudera, the biggest Hadoop distributor, finishes its merger with Hortonworks, and it builds on prior work that NEC has done with the Spark community to accelerate machine learning algorithms with its vector engines.
Back in July 2017, even before the Aurora Vector Engine accelerator was publicly announced, NEC’s System Platform Research Laboratories had gotten its hands on the device and was bragging at the International Symposium on Parallel and Distributed Computing that it had figured out a way to accelerate sparse matrix math – the kind commonly used in some machine learning and HPC workloads – on the Aurora chips, which are implemented on a PCI-Express 3.0 card and which bring considerably floating point math and memory bandwidth to bear. We caught wind about the Aurora vector engines and the “Tsubasa” (Japanese for wings) hybrid system that makes use of them ahead of SC17 last year, and did a deep dive on the architecture here.
To recap, the Aurora chip has eight vector cores connected across a 2D mesh running at 1.6 GHz; the chip is made using 16 nanometer processes from Taiwan Semiconductor Manufacturing Corp, like so many other chips these days. The processor complex has eight banks of L3 cache (weighing in at 2 MB each) that sit between the vector cores and the six HBM interfaces that in turn reach out into six HBM2 memory stacks, which come with a total of 24 GB (stacked four chips high) or 48 GB (stacked the maximum of eight chips high) of capacity. The design provides 409.6 GB/sec of bandwidth into the L2 cache and buffers from the L3 cache, and the L3 cache itself has an aggregate of over 3 TB/sec of bandwidth across its segments. The HBM2 memory has 1.2 TB/sec of bandwidth into and out of the interfaces that feed into the on-chip L3 cache banks. Link Nvidia and AMD graphics cards, which also employ HBM2 memory, the Aurora card makes use of silicon interposer technology to connect the processor-HBM complex to the rest of the card, which has the circuits to connect it to the outside world and feed it power. Each card consumes under 300 watts of power, and delivers 2.45 teraflops of aggregate double precision floating point oomph.
What we did not realize last fall was that the Aurora vector units could be double pumped with 32-but data and also then deliver 4.91 teraflops of single precision performance. This is important because many machine learning algorithms can work fine with 32-bit floating point data, and the shift to the smaller bit size is akin to doubling the memory bandwidth and memory capacity of the device (in terms of dataset size and manipulation) as well as the amount of computation done on that data. Machine learning training and inference got their start on 32-bit and 64-bit floating point, and there are plenty of algorithms that still work on this type of data and this type of vector engine.
It may not be ideal, theoretically, but keeping the bits means there is less quantization that needs to be done, so there is that. And if your data is already in 64-bit or 32-bit floating point format, there is not conversion or loss of data fidelity to deal with.
Knowing all of this, NEC came up with its own way of dicing and slicing sparse matrix data to compress it and pushing it through the Aurora engine with a homegrown statistical machine learning framework called Frovedis, which is short for framework of vectorized and distributed data analytics. (Well, sort of.) The Frovedis framework is a set of C++ programs consist of a math matrix library that adheres to the Apache Spark MLlib machine learning library and a companion machine learning algorithm library plus preprocessing for the DataFrame format commonly used for Python, R, Java, and Scala in data science work. Frovedis also employed the Message Passing Interface (MPI) protocol to scale work across multiple nodes to boost the performance of machine learning for such tabular data. In early tests on a 64-core NEC SX-ACE predecessor to the Aurora/Tsubasa architecture and an X86 server cluster with 64 cores, the NEC vector machine was able to do processing related to logistic regression (commonly used for web advertising optimization), singular value decomposition (used for recommendation engines), and K-means (used for document categorization and clustering) ridiculously faster. Like this:
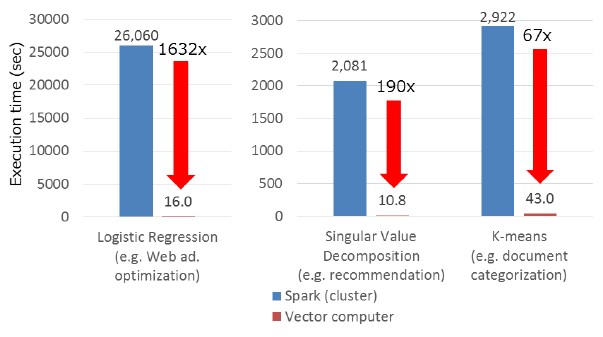
This comparison does not take into account the relative cost of an SX-ACE vector supercomputer compared to a commodity X86 cluster, but the price difference won’t be anywhere near as large as the performance difference in a lot of cases.
NEC never expected customers to buy an SX-ACE parallel vector supercomputer to run statistical machine learning, but with the Aurora vector engine, which was put onto a PCI-Express card, it most certainly does expect for small systems to be sold to accelerate HPC and machine learning workloads. The architecture allows for up to eight Aurora cards to be cross-connected through a PCI-Express fabric to each other and then for multiple nodes to be linked to each other over InfiniBand switches to present a compute substrate that has Xeon processors for certain single-threaded scalar work and for data management and a fabric of interconnected Aurora coprocessors that are linked to each other using very traditional OpenMP parallelization on each Aurora chip and MPI to link them all together within a node and across a cluster.
Last September, again before Aurora was launched but was definitely in the works, NEC teamed up with Hortonworks to certify its Data Platform for Hadoop, which included this Frovedis framework as well as other functions, atop the Hortonworks Data Platform distribution of Apache Hadoop and Spark. This set the stage for tighter coupling of the two companies’ analytics. This week, Hortonworks and NEC are agreeing to integrate Frovedis with Hadoop’s YARN job scheduler and the Spark in-memory analytics and machine learning stack when running atop the Tsubasa systems, and they are touting the fact that Frovedis running atop an X86 cluster reaching into the AVX vector units in the system did 10X better on machine learning training than just plain Spark with the Spark MLlib and that when you slid a Tsubasa server into the mix, performance was 100X better. Take a gander:
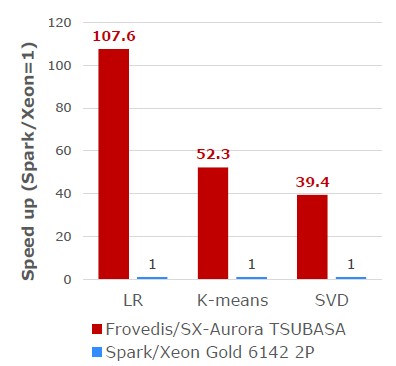
This is performance relative to a server tricked out with a pair of “Skylake” Xeon SP-6142 Gold processors. This Xeon has 16-cores running at 2.6 GHz and is rated at 150 watts, so the Aurora card has about the same wattage as the pair of Xeons; the pair of Xeons has a list price of just under $6,000. NCE has not provided list pricing for the Aurora Vector Engine card, but says that it is “much cheaper” than an Nvidia “Volta” Tesla V100. Our best guess, based on the price/performance figures that NEC made available last November, is that a single Aurora card costs on the order of $3,000. This seems impossibly small, considering that a Tesla V100 in a PCI-Express form factor with 32 GB probably costs around $8,500 these days, maybe as much as $10,000 because demand for GPUs is crazy. But that Volta GPU accelerator delivers 7 teraflops at double precision, so the price delta is justified considering that the performance of the Aurora Vector Engine card peaks at 2.45 teraflops double precision. The Aurora vector card has a 25 percent advantage on HBM2 memory capacity (48 GB versus 32 GB) and a 33 percent advantage on memory bandwidth (1.2 TB/sec versus 900 GB/sec).
The question we have is why Nvidia isn’t making more of a fuss about how Spark in-memory processing and the Spark MLlib machine learning library can be accelerated by GPUs. It looks like the new Rapids machine learning acceleration for GPUs, announced by Nvidia last week, is a step in that direction.


Intel Let The Chips Fall Where They Might
This day always comes. It is the nature of monopoly and hubris. It came for IBM. It came for Microsoft, and it is coming for Facebook. It will come for Google and, even though it is hard to believe, it will come for Amazon. And it is most assuredly coming …
Everybody Has Big Data – How To Cope With It
Enterprises are awash in data, and though many are tempted to save it all for later analysis – after all it worked for Google for many years – the store then analyze approach is poorly suited to environments with data sources that never stop. Storing all data is costly if …

Top500 Supercomputers: Who Gets The Most Out Of Peak Performance?
The most exciting thing about the Top500 rankings of supercomputers that come out each June and November is not who is on the top of the list. That’s fun and interesting, of course, but the real thing about the Top500 is the architectural lessons it gives us when we see …
There is a reason why NVidia does not talk about Spark or Hadoop much: people don’t use those systems for machine learning much. They use tensorflow/keras or xgboost for the heavy lifting.
That’s where the value is, not in k-means or linear regression.