
It is fair to say that containers in HPC are a big deal. Nothing more clearly shows the critical nature of any technology than watching the community reaction when a new security issue is discovered and released.
In a recent announcement from the team over at Sylabs, they stated that multiple container systems on kernels that do not support PR_SET_NO_NEW_PRIVS were now vulnerable. This was big news, and it obviously spread like a proverbial wildfire through the HPC community, with many mostly voicing their upset that the initial announcement came out at the start of a long holiday weekend in certain parts of the globe and on a Friday night at that. This is every system manager’s most irritable event (losing their weekend) and worst nightmare (a potentially big security risk) combined. A reasonable amount of concern was raised in the community, with unconfirmed rumors of shops removing container software and also a whole bunch of “they said, we said” abounding over how critical the container security issue is.
At The Next Platform, we know that containerized HPC workloads are critical to the future of complex computing, so we wanted to dig in and unpick some of the fact from the rumor.
At a high level, it turns out that PR_SET_NO_NEW_PRIVS is a work around in the Linux kernel, introduced in 3.5 releases. Specifically, the execve system call can grant a newly started program privileges that its parent did not initially have. This can potentially result in seriously bad news if not managed with care. The most obvious examples being setuid/setgid programs and underlying file access capabilities. This is important in HPC use cases, for example, to be able to share CUDA library installs by effectively binding file systems between the host and the contained environment. To prevent the parent program from gaining elevated privileges as well, the kernel and user code must be careful to prevent the parent from doing anything that could in anyway subvert the child. The PR_SET_NO_NEW_PRIVS bit is essentially a generic mechanism that was added to prctl() to make it safe for a process to modify its execution environment in a manner that persists across execve.
Sylabs is not requesting a CVE for this specific issue because it only affects old kernels and prior CVE’s associated with PR_SET_NO_NEW_PRIVS have already been issued. What is different now is that these legacy CVE’s are impacting more modern container code. Back in 2014 a flaw was found in the way seunshare, a utility for running executables under a different security context that used the capng_lock functionality of the libcap-ng library. The subsequent invocation of suid root binaries that relied on the fact that the setuid() system call, among others, also set the saved set-user-ID when dropping the binaries’ process privileges, which then could allow a local, unprivileged user to potentially escalate their privileges on the system.
That brings us to the Singularity container environment.
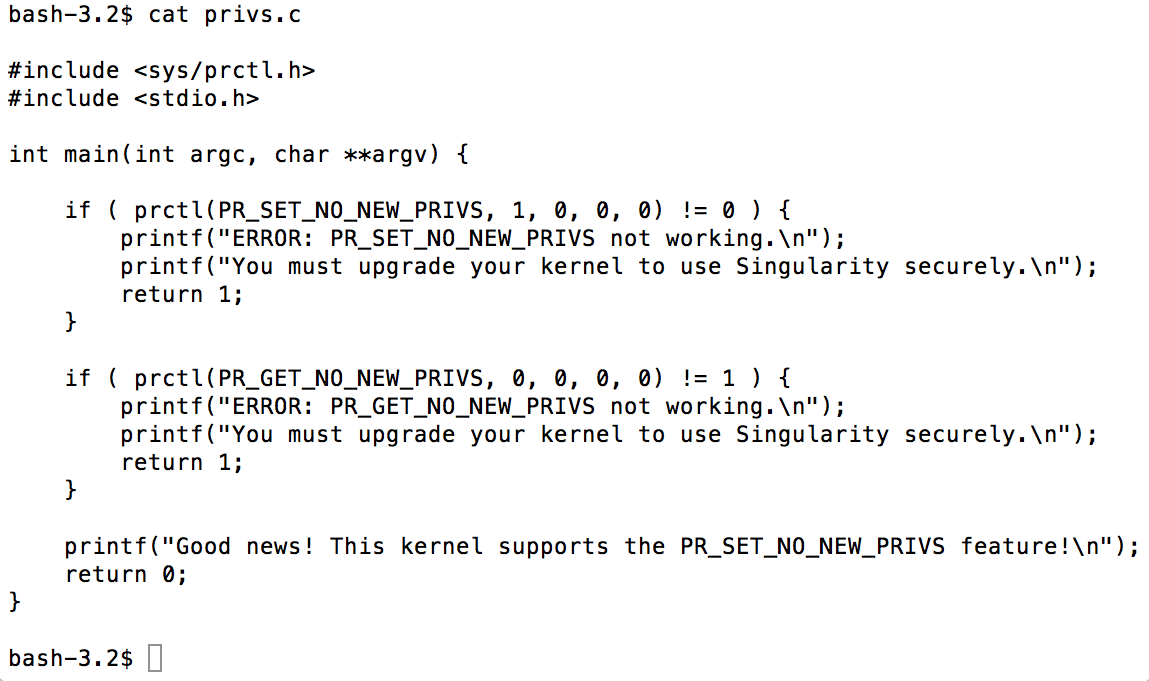
Sylabs has been very clear on this situation. If you find that your system does not support PR_SET_NO_NEW_PRIVS correctly, the only option is to upgrade your Linux kernel version or to request from upstream Linux vendors add support for PR_SET_NO_NEW_PRIVS to their maintenance kernels. What the Singularity developers have effectively done here is to force their code to now fail to execute on systems that don’t support the PR_SET_NO_NEW_PRIVS “bit”. We have reproduced the code they check for below as it is currently provided by Sylabs in a now ubiquitous, but inherently controversial, curl-pipe-bash that makes many security experts in the community wince. Piping shell commands from the Internet does allow for ease of use but is frowned upon, especially inside security contexts. A curl -s | bash was provided by Syslabs, however here is the business end of their piece of C that is built as part of the curl-pipe-bash, where you can clearly see the prctl() functionality test. This is the core heart of the issue here, if there is no PR_SET_NO_NEW_PRIVS then you can no longer run Singularity, no soup for you.
So back to the announcement, and the comment that “multiple” container systems are at risk. We wanted to understand more, especially because containers in HPC now live inside an evolving ecosystem and are becoming an ever critically important part of the computing landscape. Singularity, Shifter, and Charliecloud each make up the main three user defined software containers that are used today in HPC. They each have to balance providing high speed native access to thousands of servers with clear underlying security of the user supplied software, it is obviously non trivial and multiple techniques are used to achieve the right balance.
Charliecloud
For additional background, we spoke with Los Alamos National Laboratory scientist Reid Priedhorsky, who with Timothy Randles built Charliecloud, they state their software provides “Unprivileged containers for user-defined software stacks in HPC.” The project makes use of somewhat newer “username space” to isolate user code from the perils of assorted setuid chains to protect the runtime from the privileged areas of the underlying system kernel. Priedhorsky stated that the bottom line is that they are skeptical that their software would be vulnerable to the exact same issues as Singularity being due to their use of username space which post dates, and doesn’t touch the PR_SET_NO_NEW kernel code having a completely different approach to systems security paradigms. In looking into why Charliecloud took a different security path, we examined the LANL 2017 Charliecloud paper. In this work, LANL shows that Linux actually defines six namespaces that each isolate different classes of kernel resources. A process and any of the children see a set of these resources independently from other processes. Five of them are what they call privileged namespaces, therefore requiring root privileges to create, with the sixth, the unprivileged USER namespace being what the Charliecloud project uses.
For completeness, the five privileged namespaces they call out are:
- MOUNT: Filesystem tree and mounts.
- PID: Process IDs. A process inside a PID namespace has different PIDs depending on whether it is being viewed from inside or outside the namespace.
- UTS: Hostname and domain name, derived from “Unix Time-sharing System”
- NETWORK: All other network-related resources, including network devices, ports, routing tables, and firewall rules.
- IPC: Inter-process communication resources, both System V and POSIX.
The sixth namespace, called USER, was first added in Linux 3.8 and released on February 18, 2013. The goal of USER is to give unprivileged processes access to traditionally privileged functionality in specific contexts when doing so is safe. Charliecloud had a design goal to be unprivileged, and by use of modern (well at least 2013 vintage feature set complete) namespace semantics they appear to have pulled this particular feat off, and so far without issue. Unless it can be exploited in some other way, we could neither confirm or deny this fact, to this end, we suggest that kernel versions will continue to matter as a belt and braces approach.
Shifter
We also looked a little more closely at Shifter, which clearly states in their security documentation that they also use a similar approach as Singularity with our now good friend PR_SET_NO_NEW_PRIVS. We contacted Shane Cannon and Doug Jacobsen who develop Shifter at Lawrence Berkeley National Laboratory, but unfortunately couldn’t reach either of them for comment. However, the Shifter team does have a highly documented multi step security plan which is based more on direct avoidance of the challenges with setuid issues, specifically in their recent update to this document they call out: Avoid running privileged processes in containers. This means both explicitly chroot’ing into a container as root, or joining the namespace of an existing container, as well as preventing setuid root applications to operate at all within the container.
They continue to highlight further challenges and workarounds for security and safety, clearly taking a more advisory role in following PR_SET_NO_NEW_PRIVS than the more recent hard line developed into the Singularity codebase.
- On more recent systems, Shifter will attempt to permanently drop privileges using the “no_new_privs” process control setting, see: https://www.kernel.org/doc/Documentation/prctl/no_new_privs.txt
- See the :doc:`sshd` document for more information on the Shifter-included sshd and recommendations around running it as root (don’t unless you must).
- Related to point one, preventing setuid-root applications from operating with privilege is mostly achieved through mounting as much as possible within the Shifter environment “nosuid”, meaning the setuid bits on file permissions are ignored. In addition, processes started within shifter and their children are prevented from ever gaining additional privileges by restricting the set of capabilities they can acquire to the null set.
- One exception to the nosuid ban is if the “:rec” or “:shared” siteFs mount flags are used. The recursive bind mount operation will copy the mount flags from the base system, and will not follow Shifter standards. Similarly, the “shared” mount propagation strategy will remove the mounts from Shifter’s strict control. The privilege capability restrictions should prevent processes from escalating privilege even without the nosuid restriction.
- Use the most recent version of Shifter.
The most compelling point was their recommendation to use the most recently available version. They also explain their current lack of the use of user namespaces as we described how Charliecloud implements: “We have considered the use of user namespaces, and may make more use of them in the future. At the present, however, too few of the target Linux distributions support them or support them well to make the investment worthwhile.”
Images
The other critical challenge is around container image support. All image based container systems are inherently risky, and importantly the Shifter project also nicely states, “It is recommended that sites build images using a unprivileged account and pass the -no-xattrs flag to mksquashfs to mitigate risk. The runtime should still prevent these images from conferring any additional privileges to the user process, but dropping the attributes during preparation is a good precaution. In addition, sites should limit the users allowed to perform imports.” Also because of their reliance on loop devices, this also means that filesystems are being managed and accessed directly by the kernel, with privileged access. The team points out that this means that the filesystem files must never be writable by users directly, and should be produced by toolsets trusted by the site operating Shifter. It is good advice for whatever runtime you use, if you can control the environment better outcomes are more likely.
The Takeaway
So here is the main takeaway. Containers and container runtime systems inherit the exact same security and software issues that can be found on their hosts. This isn’t rocket science, and while it appears to be stating the obvious, the dream of having to no longer worry about the bare metal kernel version is no longer really true – if it ever really was.
Every container system now has some level of prerequisites for specific kernels and kernel features to be able to provide secure extensions to their user space code. It doesn’t matter if you are at a major hyperscaler with millions of servers or a researcher running a few servers under a desk, core host metal kernel code is the core of the system. Get it wrong and you will fail, even if you think you are safely contained.
Today, each container system achieves security via subtle and different approaches to contain the chaos of setuid exec. The bottom line is that the kernel on the host really does matter, and it can’t be simply ignored. Singularity for example, will now no longer run atop kernels lower than version 3.5 and 3.8 is needed for Charliecloud due to its use of user namespaces. This does have significant knock on effects to the system managers as they still have to keep their bare metal kernel installations up to date. With system sizes frequently in excess of a thousand to ten thousand hosts, this isn’t at all trivial. There are no magic bullets here folks, systems still need to be patched, and they need to be patched right down to the level of the kernel. The advisory approach by the Shifter team is to be applauded, being open and transparent about the potential issues with software allows for informed decisions by operators and users of shared systems. This openness is how we as a community will manage the growth of complex software.
So, the warnings here are clear – you are as secure as your weakest link, and old kernels are weak for all the great number of reasons we don’t need to go into at length here – there are many CVEs that each make for lovely bedtime reading.
We also heard some unconfirmed reports of some large centers being down from the perspective of their container workloads and currently unable to run these contained workloads due to container software environments being removed. We tried to contact a handful of center directors at some of the bigger shops, but no one wanted to reply or comment. First rule of security club? No one talks about security club, which is a shame, because we need to understand in detail any and all challenges to the integrity of our systems and learn from each other, but we do obviously understand the reason for the cone of silence.
The obvious need now for many to have to reimage their systems with newer kernel operating code to support any contained workloads that many in our community that thought we would be somewhat isolated from by actually containing our workloads has clearly caught a few out. It has essentially very much become the computational equivalent of a “Catch 22” that new software that promised to liberate us has now incarcerated us.
While it is certainly not quite at the same level as the recent Spectre/Meltdown issues, security challenges and version issues inside and outside of containers can now potentially paralyze activities in HPC centers while all the various threads and concerns are unwound, demystified and then all the appropriate patches are applied, and often reapplied. Kernel patches and updated software versions still, as they have always done, really matter. We urge that we must also stick the course with all our work on containers. It’s not the fault of the containers, they are young, innocent, growing up in a complex and terrifying world, and they really are our future.

Red Hat Stacks Up Software To Contain AI On Nvidia Platforms
Nvidia and VMware have forged a tight partnership when it comes to bringing AI to the enterprise, which stands to reason given the prevalence of VMware’s ESXi hypervisor and vSphere management tools across more than 300,000 companies worldwide. But there is another important server virtualization and container platform provider: Red …
Looking For A Singularity Event For Scientific Computing
There are people who build big machines and then there are people who create the algorithms, libraries, and applications that harness them. At oil giant BP, for many years it was Keith Gray who created its monstrous machines, but it was John Etgen who put those machines through the paces …

The Ever-Reddening Revenue Streams Of Big Blue
Speaking in generalities across any aspect of history is always risky, but that is what the job of history is. The first wave of open source software in the enterprise in the 1960s through the 1980s was largely academic, and it wasn’t until the second wave of open source hit …
Be the first to comment