
While no one has yet created an exploit to take advantage of the Spectre and Meltdown speculative execution vulnerabilities that were exposed by Google six months ago and that were revealed in early January, it is only a matter of time. The patching frenzy has not settled down yet, and a big concern is not just whether these patches fill the security gaps, but at what cost they do so in terms of application performance.
To try to ascertain the performance impact of the Spectre and Meltdown patches, most people have relied on comments from Google on the negligible nature of the performance hit on its own applications and some tests done by Red Hat on a variety of workloads, which we profiled in our initial story on the vulnerabilities. This is a good starting point, but what companies really need to do is profile the performance of their applications before and after applying the patches – and in such a fine-grained way that they can use the data to debug the performance hit and see if there is any remediation they can take to alleviate the impact.
In the meantime, we are relying on researchers and vendors to figure out the performance impacts. Networking chip maker Mellanox Technologies, always eager to promote the benefits of the offload model of its switch and network interface chips, has run some tests to show the effects of the Spectre and Meltdown patches on high performance networking for various workloads and using various networking technologies, including its own Ethernet and InfiniBand devices and Intel’s OmniPath. Some HPC researchers at the University of Buffalo have also done some preliminary benchmarking of selected HPC workloads to see the effect on compute and network performance. This is a good starting point, but is far from a complete picture of the impact that might be seen on HPC workloads after organization deploy the Spectre and Meltdown patches to their systems.
To recap, here is what Red Hat found out when it tested the initial Spectre and Meltdown patches running its Enterprise Linux 7 release on servers using Intel’s “Haswell” Xeon E5 v3, “Broadwell” Xeon E5 v4, and “Skylake” Xeon SP processors:
- Measurable, 8 percent to 19 percent: Highly cached random memory, with buffered I/O, OLTP database workloads, and benchmarks with high kernel-to-user space transitions are impacted between 8 percent and 19 percent. Examples include OLTP Workloads (TPC), sysbench, pgbench, netperf (< 256 byte), and fio (random I/O to NvME).
- Modest, 3 percent to 7 percent: Database analytics, Decision Support System (DSS), and Java VMs are impacted less than the Measurable category. These applications may have significant sequential disk or network traffic, but kernel/device drivers are able to aggregate requests to moderate level of kernel-to-user transitions. Examples include SPECjbb2005, Queries/Hour and overall analytic timing (sec).
- Small, 2 percent to 5 percent: HPC CPU-intensive workloads are affected the least with only 2 percent to 5 percent performance impact because jobs run mostly in user space and are scheduled using CPU pinning or NUMA control. Examples include Linpack NxN on X86 and SPECcpu2006.
- Minimal impact: Linux accelerator technologies that generally bypass the kernel in favor of user direct access are the least affected, with less than 2% overhead measured. Examples tested include DPDK (VsPERF at 64 byte) and OpenOnload (STAC-N). Userspace accesses to VDSO like get-time-of-day are not impacted. We expect similar minimal impact for other offloads.
And just to remind you, according to Red Hat containerized applications running atop Linux do not incur an extra Spectre or Meltdown penalty compared to applications running on bare metal because they are implemented as generic Linux processes themselves. But applications running inside virtual machines running atop hypervisors, Red Hat does expect that, thanks to the increase in the frequency of user-to-kernel transitions, the performance hit will be higher. (How much has not yet been revealed.)
Gilad Shainer, vice president of marketing at Mellanox house, shared some initial performance data from the company’s labs with regard to the Spectre and Meltdown patches. (The presentation is available online here.)
In general, Shainer tells The Next Platform, the offload model that Mellanox employs in its InfiniBand switches (RDMA is a big component of this) and in its Ethernet (The RoCE clone of RDMA is used here) are a very big deal given the fact that the network drivers bypass the operating system kernels. The exploits take advantage, in one of three forms, of the porous barrier between the kernel and user spaces in the operating systems, so anything that is kernel heavy will be adversely affected. This, says Shainer, includes the TCP/IP protocol that underpins Ethernet as well as the OmniPath protocol, which by its nature tries to have the CPUs in the system do a lot of the network processing. Intel and others who have used an onload model have contended that this allows for networks to be more scalable, and clearly there are very scalable InfiniBand and OmniPath networks, with many thousands of nodes, so both approaches seem to work in production.
Here are the feeds and speeds on the systems that Mellanox tested on two sets of networking tests. For the comparison of Ethernet with RoCE added and standard TCP over Ethernet, the hardware was a two-socket server using Intel’s Xeon E5-2697A v4 running at 2.60 GHz. This machine was configured with Red Hat Enterprise Linux 7.4, with kernel versions 3.10.0-693.11.6.el7.x86_64 and 3.10.0-693.el7.x86_64. (Those numbers are different – there is an 11.6 in the middle of the second one.) The machines were equipped with ConnectX-5 server adapters with firmware 16.22.0170 and the MLNX_OFED_LINUX-4.3-0.0.5.0 driver. The workload that was tested was not a specific HPC application, but rather a very low level, homegrown interconnect benchmark that is used to stress switch chips and NICs to see their peak sustained performance, as distinct from peak theoretical performance, which is the absolute ceiling. This particular test was run on a two-node cluster, passing data from one machine to the other.
Here is how the performance stacked up before and after the Spectre and Meltdown patches were added to the systems:
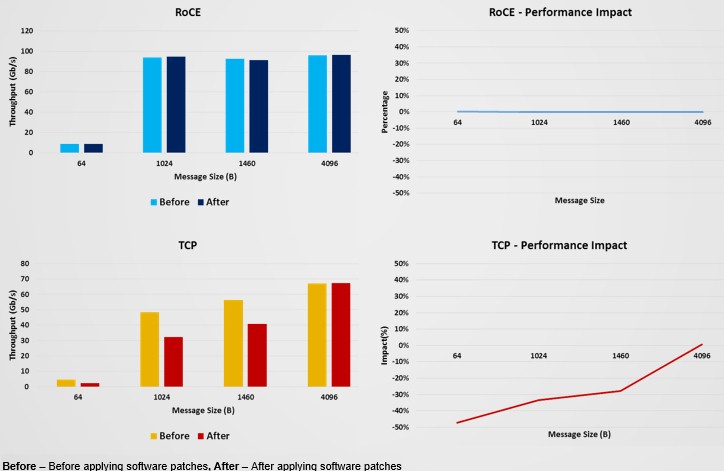
As you can see, at this very low level, there is no impact on network performance between two machines supporting RoCE on Ethernet, but running plain vanilla TCP without an offload on top of Ethernet, there are some big performance hits. Interestingly, on this low-level test, the impact was greatest on small message sizes in the TCP stack and then disappeared as the message sizes got larger.
On a separate round of tests pitting InfiniBand from Mellanox against OmniPath from Intel, the server nodes were configured with a pair of Intel Xeon SP Gold 6138 processors running at 2 GHz, also with Red Hat Enterprise Linux 7.4 with the 3.10.0-693.el7.x86_64 and 3.10.0-693.11.6.el7.x86_64 kernel versions. The OmniPath adapter uses the IntelOPA-IFS.RHEL74-x86_64.10.6.1.0.2 driver and the Mellanox ConnectX-5 adapter uses the MLNX_OFED 4.2 driver.
Here is how the InfiniBand and OmniPath protocols did on the tests before and after the patches:
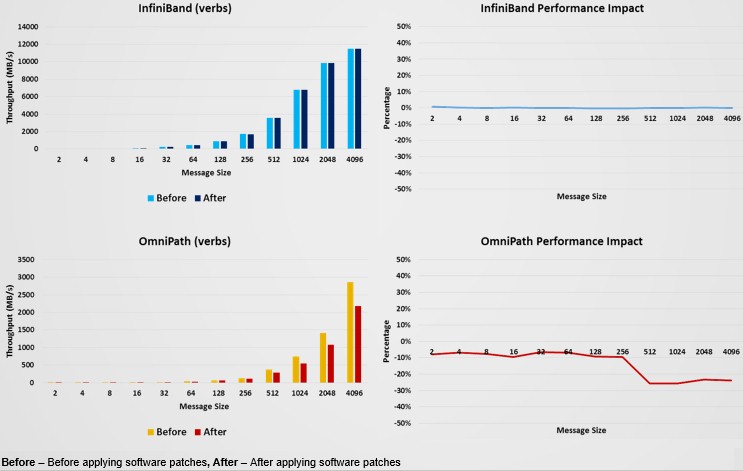
Again, thanks to the offload model and the fact that this was a low level benchmark that did not hit the kernel very much (and some HPC applications might cross that boundary and therefore invoke the Spectre and Meltdown performance penalties), there was no real effect on the two-node cluster running InfiniBand. With the OmniPath system, the impact was around 10 percent for small message sizes, and then grew to 25 percent or so once the message sizes transmitted reached 512 bytes.
We have no idea what the performance implications are for clusters of more than two machines using the Mellanox approach. It would be interesting to see if the degradation compounds or doesn’t.
Early HPC Performance Tests
While such low level benchmarks provide some initial guidance on what the effect might be of the Spectre and Meltdown patches on HPC performance, what you really need is a benchmark run of real HPC applications running on clusters of various sizes, both before and after the Spectre and Meltdown patches are applied to the Linux nodes. A team of researchers led by Nikolay Simakov at the Center For Computational Research at SUNY Buffalo fired up some HPC benchmarks and a performance monitoring tool derived from the National Science Foundation’s Extreme Digital (XSEDE) program to see the effect of the Spectre and Meltdown patches on how much work they could get done as gauged by wall clock time to get that work done.
The paper that Simakov and his team put together on the initial results is found here. The tool that was used to monitor the performance of the systems was called XD Metrics on Demand, or XDMoD, and it was open sourced and is available for anyone to use. (You might consider Open XDMoD for your own metrics to determine the performance implications of the Spectre and Meltdown patches.) The benchmarks tested by the SUNY Buffalo researchers included the NAMD molecular dynamics and NWChem computational chemistry applications, as well as the HPC Challenge suite, which itself includes the STREAM memory bandwidth test and the NASA Parallel Benchmarks (NPB), the Interconnect MPI Benchmarks (IMB). The researchers also tested the IOR file reading and the MDTest metadata benchmark tests from Lawrence Livermore National Laboratory. The IOR and MDTest benchmarks were run in local mode and in conjunction with a GPFS parallel file system running on an external 3 PB storage cluster. (The tests with a “.local” suffix in the table are run on storage in the server nodes themselves.)
SUNY Buffalo has an experimental cluster with two-socket machines based on Intel “Nehalem” Xeon L5520 processors, which have eight cores and which are, by our reckoning, very long in the tooth indeed in that they are nearly nine years old. Each node has 24 GB of main memory and has 40 Gb/sec QDR InfiniBand links cross connecting them together. The systems are running the latest CentOS 7.4.1708 release, without and then with the patches applied. (The same kernel patches outlined above in the Mellanox test.) Simakov and his team ran each benchmark on a single node configuration and then ran the benchmark on a two node configuration, and it shows the difference between running a low-level benchmark and actual applications when doing tests. Take a look at the table of results:
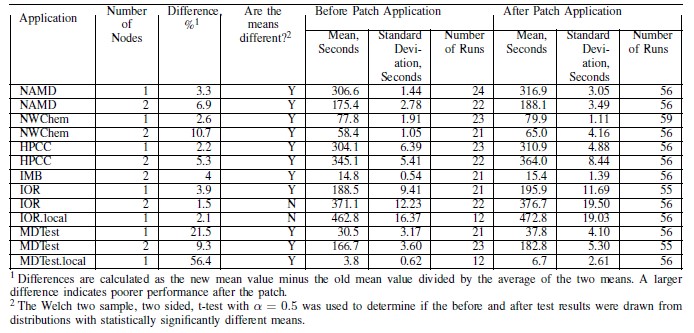
The before runs of each application tested were done on around 20 runs, and the after was done on around 50 runs. For the core HPC applications – NAMD, NWChem, and the elements of HPCC – the performance degradation was between 2 percent and 3 percent, consistent with what Red Hat told people to expect back in the first week that the Spectre and Meltdown vulnerabilities were revealed and the initial patches were available. However, moving on to two-node configurations, where network overhead was taken into account, the performance impact ranged from 5 percent to 11 percent. This is more than you would expect based on the low level benchmarks that Mellanox has done. Just to make things interesting, on the IOR and MDTest benchmarks, moving from one to two nodes actually lessened the performance impact; running the IOR test on the local disks resulted in a smaller performance hit than over the network for a single node, but was not as low as for a two-node cluster running out to the GPFS file system.
There is a lot of food for thought in this data, to say the least.
What we want to know – and what the SUNY Buffalo researchers are working on – is what happens to performance on these HPC applications when the cluster is scaled out.
“We will know that answer soon,” Simakov tells The Next Platform. “But there are only two scenarios that are possible. Either it is going to get worse or it is going to stay about the same as a two-node cluster. We think that it will most likely stay the same, because all of the MPI communication happens through the shared memory on a single node, and when you get to two nodes, you get it into the network fabric and at that point, you are probably paying all of the extra performance penalties.”
We will update this story with data on larger scale clusters as soon as Simakov and his team provide the data.


Trading Off Security And Performance Thanks To Spectre And Meltdown
The revelations by Google’s Project Zero team earlier this year of the Spectre and Meltdown speculative execution vulnerabilities in most of processors that have powered servers and PCs for the past couple of decades shook the industry as Intel and other chip makers scrambled to mitigate the risk of the …
How Spectre And Meltdown Mitigation Hits Xeon Performance
It has been more than two months since Google revealed its research on the Spectre and Meltdown speculative execution security vulnerabilities in modern processors, and caused the whole IT industry to slam on the brakes and brace for the impact. The initial microbenchmark results on the mitigations for these security …
Datacenters Brace For Spectre And Meltdown Impact
The Spectre and Meltdown speculative execution security vulnerabilities fall into the category of “low probability, but very high impact” potential exploits. The holes that Spectre and Meltdown open up into systems might enable any application to read the data of any other app, when running on the same server in …
Be the first to comment