
NVM-Express isn’t new. Development on the interface, which provides lean and mean access to non-volatile memory, first came to light a decade ago, with technical work starting two years later through a work group that comprised more than 90 tech vendors. The first NVM-Express specification came out in 2011, and now the technology is going mainstream.
How quickly and pervasively remains to be seen. NVM-Express promises significant boosts in performance to SSDs while driving down the latency, which would be a boon to HPC organizations and the wider world of enterprises as prices for SSDs continue to fall and adoption grows. A broad range of vendors, including Intel, Dell EMC, IBM, Pure Storage, and others, are growing their NVM-Express product portfolios to meet a growing demand for the technology.
Newisys, which used to make server chipsets and which for years has been a part of contract manufacturer Sanmina-SCI, is among those vendors expecting a surge in demand for NVM-Express. Speaking at SC17 earlier this month, Rick Kumar, vice president of product development at Newisys, noted numbers from G2M Research predicting that by 2020, more than half of all servers will ship with NVM-Express drives – an average of 5.5 drives per system –more than 60 percent of storage server drives will be NVM-Express, and innovation by Intel and others will drive down costs associated with the interface. Given what NVM-Express promises, the upward trends are no surprise, Kumar said.
“NVM-Express is undergoing a massive change in the market,” he said, noting that adoption in the HPC market is expected to grow quickly. “NVM-Express ultimately eliminates the unnecessary overhead of the SCSI stack and supporting a lot more queues at a higher bandwidth with significantly lower latency. That’s the main driver.”
Another driver is the work by vendors like Intel that are “dramatically widening the performance gap” between SAS and NVM-Express. Newisys for more than a year has been implementing NVM-Express in its platforms. It currently offers four NVM-Express-based platforms that include running NVM-Express over Fabrics, directly attached to the CPU and as a storage expansion flash array (JBOF, short for Just a Bunch of Flash). In his talk at the conference, Kumar noted that there are different ways to connect NVM-Express depending on the requirements around scale and flexibility, with each carrying trade-offs in performance, latency, and cost.
He used a scenario of the NVM-Express drive being directly attached to the CPU, using it as a baseline for latency and cost efficiency, but noted that with this implementation, there are is no flexibility in allocating drives to different CPUs, capacity is fixed to what the drive is connected to and high availability must be managed by the host system. A JBOF environment where NVM-Express drives are connected over PCI-Express or copper in a rack adds hundreds of nanoseconds of latency, but offers greater flexibility in allocating drives, with an addition cost per SSD of $250. The host still does all of the high availability support.
NVM-Express over Ethernet with a hardware implementation adds 70 microseconds in latency, but offers more flexibility, capacity is essentially unlimited – “you can continue to add more and more NVM-Express or fabric hardware” – with an additional $500 per SSD added to the cost. On X86 server platforms with NVM-Express with Linux applications, there is a latency increase of about 20 microseconds, but the drives can be virtualized and exported. The added cost is about $600 per SSD.
“So you can create multiple drives out of single drives or combine multiple drives into single drives to be exported into different arrays,” Kumar said. “Again, unlimited capacity in the sense that you can continue to add these systems in your network and high availability can now be shifted over to the array itself where the drives are located.”
Organizations will want to weigh the tradeoffs as they explore their NVM-Express options, but during his talk, Kumar focused on NVM-Express over Ethernet as an option for HPC users. There are two ways to implement NVM-Express over fabric, with the first being simply to export raw name spaces of the drives themselves. The other is more complex – ramping up the number of SSDs, which also provides enterprise scalability and production capabilities.
“In addition, disaggregation also provides significant efficiencies in the datacenter itself and you can use your resources as you need and change the allocation of the NVM-Express to your host depending on your workload on a day-to-day basis,” he said.
One of two examples of NVM-Express over fabric implementations that could be adopted in HPC was a proof-of-concept of 2U 24-drive hardware implementation that exports six 100 Gb/sec connections to a switch, which is then connected to a number of hosts. The performance his 15 million IOPS at 60 GB/sec, with only an addition of 7 microseconds in latency. The system was based on standard x86 servers and included Intel’s Optane NVM-Express SSDs, Newisys’ NVM-Express Fabric Storage Systems and Magma NVM-Express over Fabrics bridge adaptors from Kazan Networks. The system also used IBM’s Spectrum Scale software and Mellanox Technologies’ switches and host bus adapters.

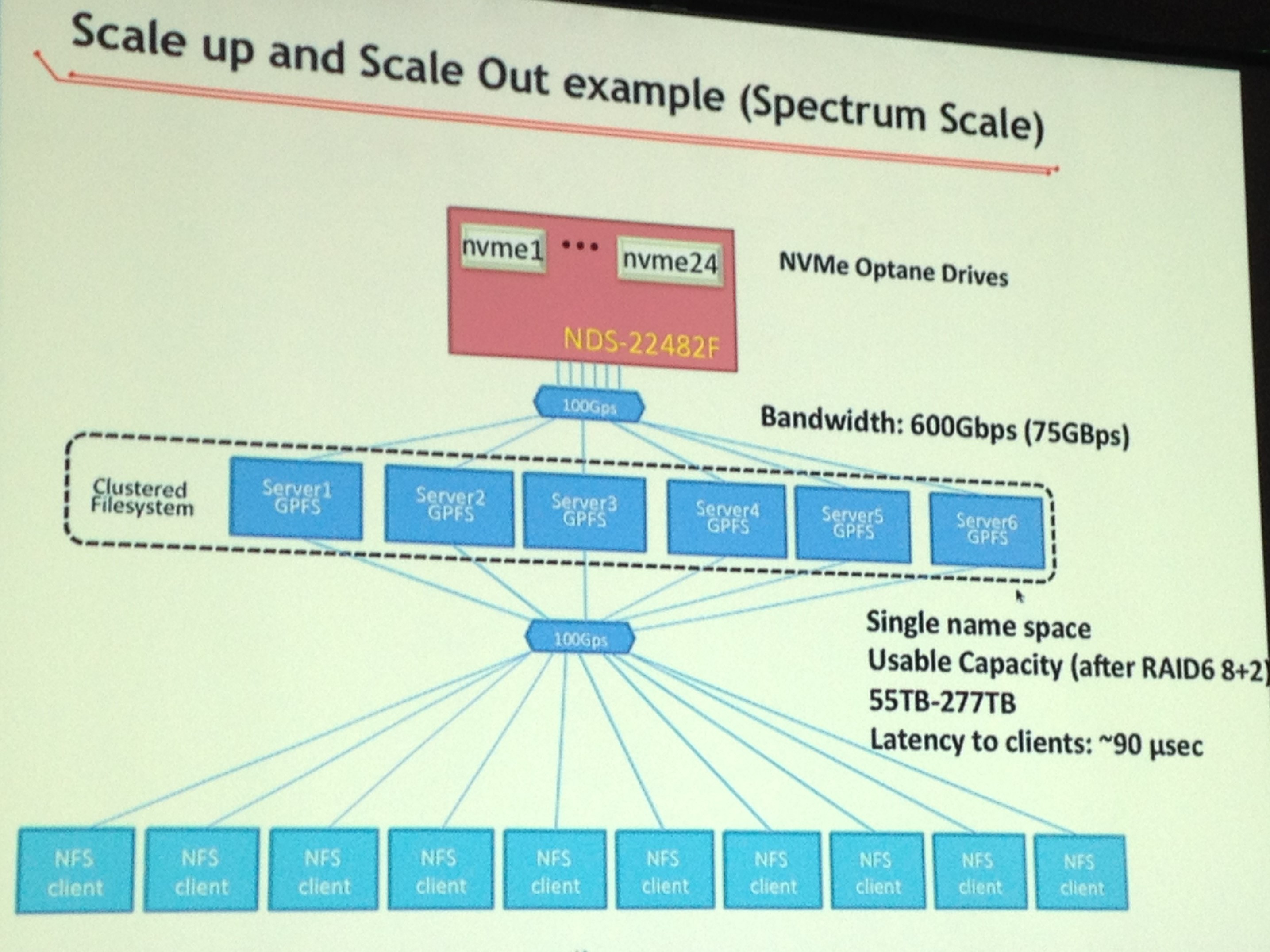
Another reference implementation focused on both scale up and scale out using the same platform, with Intel 3D XPoint Optane drives and the Spectrum Scale software with multiple GPFS servers and clients that were exported to a number of hosts, which Kumar said it sees as a single name space. The added latency adds up to 90 microseconds, but offers high flexibility.
“As you need capacity, you simply add more of these systems across the top,” he said. “As you need more bandwidth, you’re adding more NFS servers across the bottom.”
There are a number of considerations that need to be taken into account when looking at NVM-Express over fabrics, Kumar said.
“You want to exploit a system that maximizes the performance of the drives themselves – lowest latency so that the system itself is not adding more latency than necessary to the drives, you’re maximizing the bandwidth so you’re not bottlenecking any of the throughput of the drives, redundancy, if that is something that is important to you, you can implement in multiple different ways – at the chassis level or at the client level or host level,” he said. “You’re suddenly exporting your data over Ethernet, so security and access to control is very, very important and that’s an area we’re going to be looking at to create an out-of-band management tool that would simplify deploying this at very large-scale. Virtualization of the SSD depends on the requirements, whether you need a lot of hosts, lots of clients connecting to the storage pool.”
As the systems scale, users also will want to ensure they have health and performance monitoring capabilities in place, Kumar said.


Mainstreaming Fast Flash Clusters For Fun And Profit
One of the common themes – and one could say even the main theme – of The Next Platform is that some of technologies developed by the high performance supercomputing centers (usually in conjunction with governments and academia), the hyperscalers, the big cloud builders, and a handful of big and …
Excelero Storage Deal Gives Nvidia A Nearly Complete HPC/AI Stack
In case it is not immediately obvious, over the past decade Nvidia has been transforming itself from a component supplier into a complete platform provider. Such a move was not necessary – you can expect for AMD to be pretty gun shy about such a move after is acquisition of …
Storage Is Going Have To Deal With Clouds And Edges
While on-premises datacenters are strategic to large enterprises, and will be for the foreseeable future, hybrid clouds and the edge are also an increasingly important part of the IT platform portfolio. But the road out of the datacenter and into the future with clouds and edges is not always an …
Be the first to comment