

Although much of the attention around deep learning for voice has focused on speech recognition, developments in artificial speech synthesis (text to speech) based on neural network approaches have been just as swift.
The goal with text-to-speech (TTS), as in other voice-related deep learning areas, is to get the training and inference times way down to allow for fast delivery of services and low power consumption and utilization of hardware resources. A recent effort at Chinese search giant, Baidu, which is at often at the forefront of deep learning for voice recognition and TTS, has shown remarkable progress on both the algorithmic and hardware efficiency fronts with the release of the Deep Voice 3 framework.
Deep Voice 3 goes far beyond its predecessors in its ability to imitate speech that sounds like an actual person at larger scale and with faster inference times. For users, it can now sound like a specific person with trimmed down training using audio samples. The last iteration of the software that emerged this summer was able to imitate a speaker accurately based on a 30 minute sample and this newest (and last) version can synthesize speech from over 2400 voices, Baidu says, more than other model, driven largely by adding the complexity of WaveNet models into the mix.
By implementing GPU kernels for the Deep Voice 3 architecture and parallelizing another section of workload on CPUs, Baidu is able to address ten million queries per day (116 queries per second) on a single GPU server with a 20-core CPU. In other words, this is not only interesting from an application perspective, but also highlights major progress in making both training and inference highly efficient. Baidu says that this architecture trains an order of magnitude faster, allowing the team to scale over 800 hours of training data and synthesize speech from the massive number of voices—all with their own distinct inflections and accents.
The Deep Voice 3 architecture is a fully-convolutional sequence-to-sequence model which converts text to spectrograms or other acoustic parameters to be used with an audio waveform synthesis method. Baidu uses low-dimensional speaker embeddings to model the variability among the thousands of different speakers in the dataset.
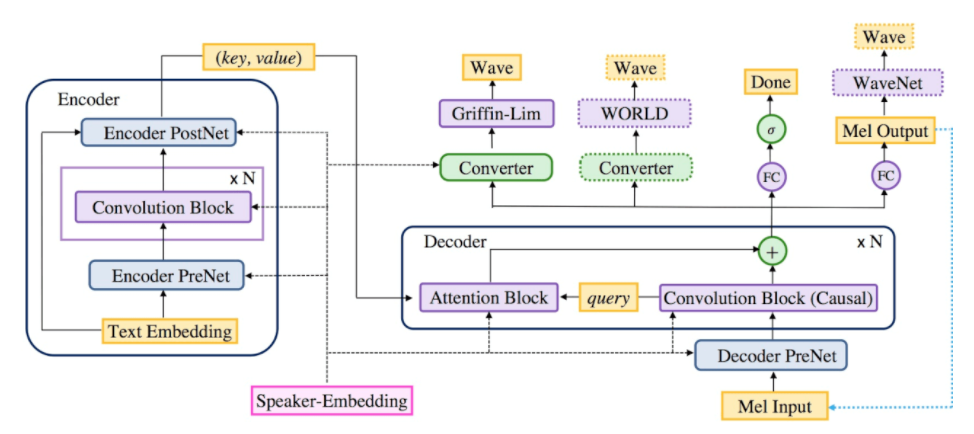
A sequence-to-sequence model like Deep Voice 3 consists of an encoder, which maps input to embeddings containing relevant information to the output, and a decoder which generates output from these embeddings. Unlike most sequence-to-sequence architectures that process data sequentially using recurrent cells, Deep Voice 3 is entirely convolutional, which allows parallelization of the computation, and results in very fast training.
Baidu compared Deep Voice 3 to Tacotron, a recently published attention-based TTS system. For Baidu’s system on single-speaker data, the average training iteration time (for batch size 4) is 0.06 seconds using one GPU as opposed to 0.59 seconds for Tacotron, indicating a ten-fold increase in training speed. In addition, Deep Voice 3 converges after ∼ 500K iterations for all three datasets in our experiment, while Tacotron requires ∼ 2M iterations as detailed here. This significant speedup is due to the fully-convolutional architecture of Deep Voice 3, which Baidu says highly exploits the parallelism of a GPU during training.
The detailed paper that was just released on Deep Voice 3 highlights how the architecture is capable of multispeaker speech synthesis by augmenting it with trainable speaker embeddings, a technique described in the Deep Voice 2 paper. It also details the production-ready Deep Voice 3 system in full including text normalization and performance characteristics, and demonstrate state-of-the-art quality through extensive MOS evaluations.
Baidu says that future work will involve “improving the implicitly learned grapheme-tophoneme model, jointly training with a neural vocoder, and training on cleaner and larger datasets to scale to model the full variability of human voices and accents from hundreds of thousands of speakers.”


China’s Hyperscalers Strive to Keep Pace in Open Source
We have a good sense of what projects U.S. companies open source but when it comes to Chinese webscale companies, most notably the big three—Baidu, Alibaba, and Tencent—that ecosystem is less public and not often discussed. For instance, even if you work in open source at a large company, it …

Vertically Unchallenged
Components make compute and storage servers, and servers with application plane, control plane, and data plane software running atop them or alongside them make systems, and workflows across systems make platforms. The end state goal of any system architect is really creating a platform. If you don’t have an integrated …

A Look at Baidu’s Industrial-Scale GPU Training Architecture
Like its U.S. counterpart, Google, Baidu has made significant investments to build robust, large-scale systems to support global advertising programs. As one might imagine, AL/ML has been playing a central role in how these systems are built. Massive GPU-accelerated clusters on par with the world’s most powerful supercomputers are the …
Be the first to comment