

Like its U.S. counterpart, Google, Baidu has made significant investments to build robust, large-scale systems to support global advertising programs. As one might imagine, AL/ML has been playing a central role in how these systems are built. Massive GPU-accelerated clusters on par with the world’s most powerful supercomputers are the norm and advances in AI efficiency and performance are paramount.
Baidu’s history with supercomputer-like systems for advertising stretches back to over a decade ago, when the company used a novel distributed regression model to determine the click-through rate (CTR) of advertising campaigns. These MPI-based algorithms gave way to nearest neighbor and maximum inner product searches just before AI/ML hit and has now evolved to include ultra-compressed CTR models running on large pools of GPU resources.
Weijie Zhao at the Cognitive Computing Lab at Baidu Research emphasizes the phrase “industrial scale” when talking about Baidu’s infrastructure to support advertising, noting that training datasets are at petabyte scale with hundreds of billions of training instances. Model sizes can reach over ten terabytes. Compute and network efficiency, but with these models storage definitely becomes a bottleneck, pushing the need for novel, serious compression/quantization.
“It’s non-trivial to deploy these models at an industrial scale with hundreds to thousands of billion of input features, which under budget constraints, can cause fundamental issues for storage, communication, and training speed.” He says that their training systems, which are now GPU-laden, used to be all-CPU but with the massive-scale MPI “they consume a large amount of communication and computation to remain fault tolerant and synchronous, which in turn means substantial costs for cluster maintenance and energy consumption.”
What’s interesting about Baidu’s CTR segment of advertising is that it’s not possible to trade accuracy for performance/efficiency. That limits options for building robust training systems that aren’t insanely expensive to run and that don’t trip over themselves in terms of data movement, etc.
What is also interesting is the node architecture Baidu selected for its ultrascale training runs and the clear tradeoffs they are making in terms of performance of the network, storage, and compute.
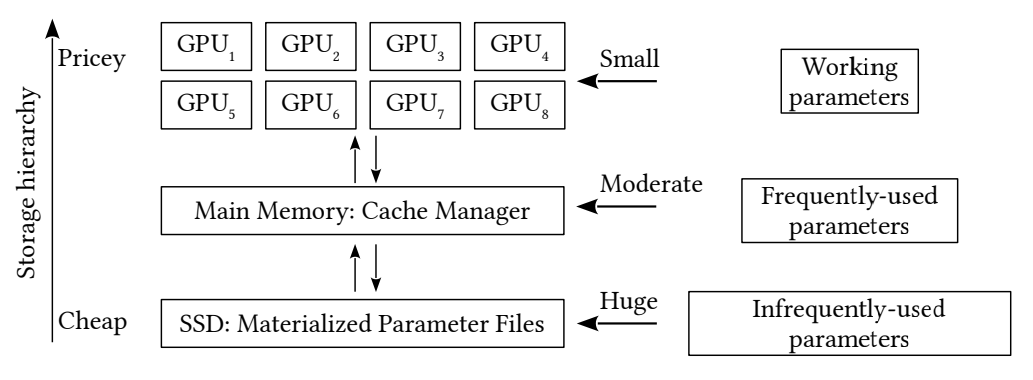
HBM plays an active role in the training process with all parameters stored there. Using an all-reduce-type GPU communication, updates are synchronized across the entire supercomputer. General main memory is used to handle cache and any parameters that sit out of memory. “Compared to a multi-node system, the advantages of the single-node system with multi-GPU include a cheap price, low communication cost, much less synchronization, and a low failure rate,” Weijie Zhao says.
“This design simply erases our concerns on communication and synchronization costs by MPI clusters and greatly cut the expenses of the computer cluster maintenance and energy consumption. The storage pressure from the embedding table of size exceeding 10TB are addressed by three levels of hardware structure, i.e., SSDs (solid state drives), main memory, and GPU memories. Different from the existing system which distributes the training jobs to both CPUs and GPUs, all the training jobs are distributed only over multiple GPUs, which further reduces the system complexity.”
“Our legacy CPU-only training system was doing distributed training and then has been upgraded to the current one node GPU training. The distributed training system consisted of 150 CPUonly computing nodes with each having 16-core CPU and 180 GB memory, while the GPU computing node in the current training system employs more pricey hardware: larger memory (1 TB), SSDs and GPUs: the cost of one GPU computing node is around 15 times of the CPU-only node. However, we only need a single one-node GPU computing node to complete the job on the 150 CPU-only nodes cluster: the current one-node system utilizes a much lower expense (one-tenth) comparing with the 150 CPU-only cluster.”
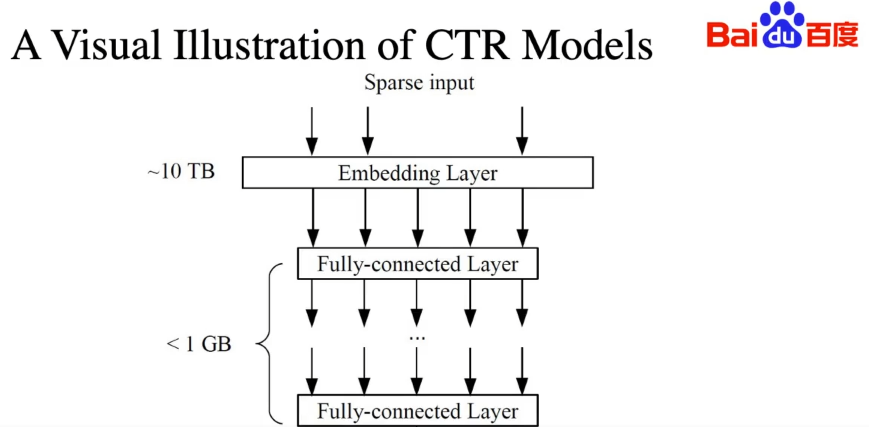
A sense of scale for each layer in the CTR models.
Weijie Zhao says that within the CTR group, just over half a billion training instances are generated daily. He says with the current GPU approach with strict quantization, training takes only 2.5 hours for this sample size with delay, caused by page view, online update of input features, and online update of the model, not exceeding 3 hours, while the CPU-only multi-node one took 10 hours.
This node architecture is noteworthy but it doesn’t fully address the demands on storage. It took Baidu Research some serious quantization legwork, which you can read about here, their approach cut their storage usage in half from where it was before the effort and 75% more than using standard 32-bit precision.
“Our work also reveals that, in contrast to many academic studies on 1-bit or 2-bit quantization-based learning systems, industrial-scale production systems may need substantially more bits, for example, 16 bits in our system. This quantization step enables us to double the dimensionality of the embedding layer without increasing the storage. We have deployed this system in production and observed a substantial increase in the prediction accuracy and the revenue.”


China’s Hyperscalers Strive to Keep Pace in Open Source
We have a good sense of what projects U.S. companies open source but when it comes to Chinese webscale companies, most notably the big three—Baidu, Alibaba, and Tencent—that ecosystem is less public and not often discussed. For instance, even if you work in open source at a large company, it …

Vertically Unchallenged
Components make compute and storage servers, and servers with application plane, control plane, and data plane software running atop them or alongside them make systems, and workflows across systems make platforms. The end state goal of any system architect is really creating a platform. If you don’t have an integrated …

One Deep Learning Benchmark to Rule Them All
Over the last few years we have detailed the explosion in new machine learning systems with the influx of novel architectures from deep learning chip startups to efforts from vendors and hyperscalers alike. With such processor diversity, standardizing performance metrics when there are so many variables is tricky, but it …
Be the first to comment