
It is difficult not to be impatient for the technologies of the future, which is one reason that this publication is called The Next Platform. But those who are waiting for the Gen-Z consortium to deliver a memory fabric that will break the hegemony of the CPU in controlling access to memory and to deepen the memory hierarchy while at the same time flattening memory addressability are going to have to wait a little longer.
About a year longer, in fact, which is a bit further away than the founders of the Gen-Z consortium were hoping when they launched their idea for a memory fabric back in October 2016. These things take time, particularly any standard being raised by dozens of vendors with their own interests and ideas.
It has been almost a year now since Gen-Z launched, and the consortium is growing and the specifications are being cooked up by the techies. The core Gen-Z spec was published in December 2016 and updated in July to a 0.9 level; it is expected to be at the 1.0 level before the end of the year. The related The PHY spec is at about a 0.5 release level, and it should be at the 1.0 release level by the end of the year. And interestingly, the Gen-Z folks are showing off a new connector spec developed in conjunction with Tyco Electronics that uses 112 GT/sec signaling that delivers more bandwidth than PCI-Express or DDR4 slots in a much smaller form factor. (More on this in a second.)
“We are striving to have everything done by the end of the year, or maybe shortly thereafter, and then there is a 60 day review after that,” Kurtis Bowman, director of architectures and concepts team in the CTO office at Dell and president of the Gen-Z consortium, tells The Next Platform. “I think productization will happen in late 2019 and maybe early 2020. It is really about silicon development time. From the time we get the spec finalized at the end of 2017, they need roughly 18 months to get some first silicon, and then after that is interoperability testing inside Gen-Z with plugfests to make sure it really is interoperable in the way we want it to be.”
Bridging From PCI And Ethernet To The Gen-Z Future
The last time that the industry tried to get behind an I/O standard, it was a bit messy and did not pan out as intended. In fact, the effort ricocheted and culminated in 1999 with the creation of System I/O, branded as InfiniBand, which was supposed to be a universal client, server, and storage interconnect that was meant to replace both PCI and Ethernet at the same time. InfiniBand, you will recall, is the result of the merger in 1999 of the Future I/O spec promoted by Compaq (when it was the world’s largest server shipper), IBM, and Hewlett Packard (The Enterprise came much later) and the Next Generation I/O competing spec from Intel, Microsoft, and Sun Microsystems. So we have seen this Future I/O movie before. And it was Intel, oddly enough, that backed away from InfiniBand (only to buy back into it with QLogic a decade later and use that for the foundation for the Omni-Path interconnect) in favor of extending the PCI bus for peripherals and keeping Ethernet for linking clients and servers to each other.
This time around, with Gen-Z, Intel has much more sway in the datacenter and has been particularly mum about the Gen-Z fabric effort as well as other interesting developments such as the CCIX interconnect being promoted by FPGA rival Xilinx and the OpenCAPI interconnect being promoted by processor rival IBM. But we think that if any of these protocols get any traction in the market, Intel will have to play and will eagerly adopt such technologies if it helps the company maintain its relative monopoly on datacenter compute and extend its reach in non-volatile memories.
This is a pivotal time for system architecture. The fundamental structure of servers has not changed much in decades, but is undergoing a major transformation now. As we have explained before the compute and memory hierarchies within systems and across clusters are expanding beyond the three or four levels of cache right next to the processor and its one layer of main memory. This memory was essentially used as a temporary scratch pad for applications, and flash has been added in recent years to first act as an intermediary between fast main memory and slow disk and then, as prices fell thanks to volume economics and Moore’s Law capacity expansion, as primary media. Now we have storage-class memories – devices that are more capacious and less expensive per bit than DDR main memory but also slower – are being jammed into the memory hierarchy, and the important change this time is that these devices can be addressed like main memory, with its load/store operations and related push/get and atomic operations semantics instead of the very slow way that block-level devices are addressed out on the PCI-Express bus. Gen-Z is being created to be the fabric interconnect that lashes together the memories in CPUs, accelerators, and various storage devices much as InfiniBand once promised to do to link together clients, servers, and storage arrays back at the tail-end of the dot-com boom.
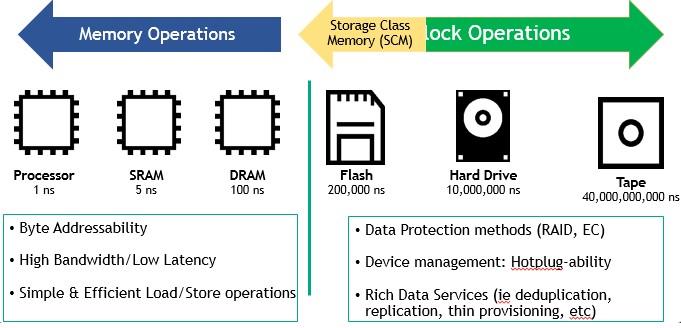
This time is different, and the issue is larger than trying to consolidate PCI and Ethernet and that is why Gen-Z is going to springboard from these foundational technologies rather than try to displace them. Gen-Z also wants to break down the wall between addressable and block storage devices and allow for the pooling of storage across compute devices when it is appropriate.
The issue is not just that memory hierarchies are embiggening, but rather that the memory bandwidth and I/O bandwidth per core is not expanding and something else needs to be done so that compute capacity is not stranded. Here is the situation with memory bandwidth:
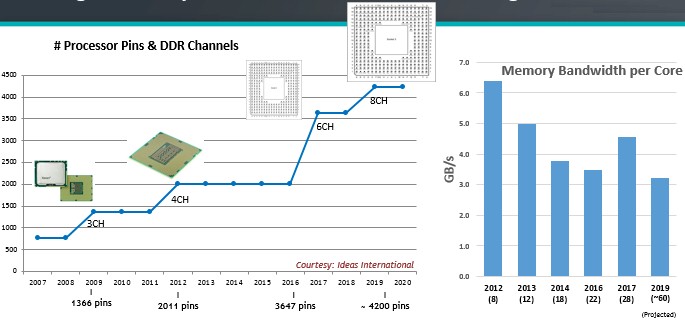
A chip cannot have an infinite number of pins because of the power it takes to drive them, and even as the pin count is going up, in part to provide more addressable DRAM, the amount of memory bandwidth per core in the CPU is going down. The processor power draw is on the rise because core counts are rising, DRAM power consumption is too as it cycles faster, and while the number of memory controllers is rising, ever so slowly, these add thermal and transistor overhead to the CPU.
I/O bandwidth on the CPU is similarly constrained, as you can see:
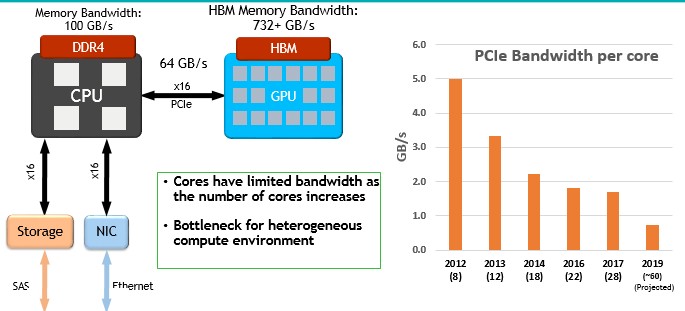
This is not a very good situation to keep cores fed with scads of storage class memories.
“We were looking for a way to extend beyond what we have today, and looking at architectures that are capable of handling the capacity of data at speed, and we figured that the only way we could do that was if we moved to a data-centric approach with a fabric architecture,” explains Ron Noblett, vice president of advanced development in the CTO office at Hewlett Packard Enterprise. “Our strategy is to natively come out as Gen-Z so we can easily consolidate our I/O and resource functions and our systems can be designed in a simple manner using a single protocol. This is something that I think we would have had years ago except that the I/O and media devices that we were interfacing with had so many deficiencies that you have to develop very long and lethargic block interfaces to get to storage, and moving data all the time into working datasets into volatile DRAM was also tough. With the future looking like we are going to have very high performance, nanosecond-speed storage devices that are going to be persistent, that gives us the opportunity to get architectures back where we should have been, which is a simpler protocol with more flat addressability. And that is where Gen-Z is headed.”
There is some radical rethinking of how main and other memory is addressed within the Gen-Z consortium. Over the long haul, main memory could be rejiggered thus:
![]()
This is the tricky bit, since it essentially involves moving the memory controller off of the CPU, where it has resided for more than a decade, and putting it on the memory device, in this case the DRAM memory that Intel does not control. This part is not going to happen overnight, obviously. If at all.
But for accelerators and other storage class memories, there is certainly more hope that Gen-Z will get traction, with these possible scenarios, according to Bowman and Noblett:
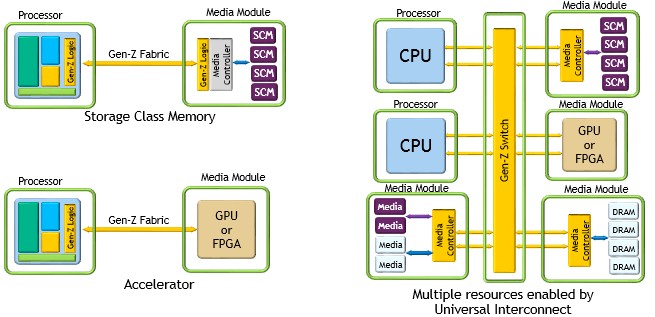
It is not clear what Intel’s plans are for Gen-Z, and that is important because Intel is the dominant supplier of processors in the datacenter and also one of the key players in persistent storage (flash and 3D XPoint) as well as in networking. It is possible to bridge from PCI-Express 4.0 to Gen-Z, but because that would mean going through the PCI-Express root port, that adds inherent latencies of getting to that port and then doing the protocol conversion back and forth. It would be better to have Gen-Z come right off of the coherent bus on the processor die. If Intel wanted to bridge directly off the UltraPath Interconnect (UPI) ports on the new “Skylake” Xeon SP processors, it would have to license Gen-Z from the consortium, which it has not done yet. (Significantly, IBM, AMD, ARM, and Cavium are all members of the consortium, and HPE and Dell, the two biggest server sellers in the world, are driving the spec.)
Those PCI-Express to Gen-Z bridges would be alright for super-fast, block storage devices, adds Bowman, but when it comes to a cacheable architecture with memory mapping, then the Gen-Z bridge really needs to be on the coherent bus.
“There are going to be tiers of memory. On a Gen-Z fabric, if you want to do composability at a rack scale, the switch is going to have a very low latency, maybe something on the order of 30 nanoseconds. It is conceivable that you would compose main memory, even as a rack resource, at that speed. However, DDR memory attached directly to the CPU is still going to live for a while, at least through DDR5, and it is likely that you may tier that as the first tier of memory and have the composable memory as a second tier. We also know that HBM or HMC is going to be right next to the processor or even integrated into the processor. So there is a little bit of a tradeoff as we move into the future and have to design around tiers of memory. Having said that, Gen-Z will with storage class memories and even main memory itself give you extremely low latency, in the tens of nanoseconds range. It really comes down to the maturity of the storage class memories, and the tradeoffs that system architects will make around bandwidth, latency, capacity, and cost.”
The adoption of Gen-Z should be as simple and transparent as the adoption of SMP and NUMA processor clustering was. Users of SMP and NUMA systems were largely insulated the wizardry that made multiple CPUs look like one; this was handled by the hardware chipset and the operating system. (That is a radical oversimplification, we realize, given how many hyperscalers, HPC centers, and sophisticated enterprises get down to the threads in a system and pin particular parts of their applications to specific cores and their local memories.)
We, of course, want to know if Gen-Z could be the foundation of a new type of coherency, one that spans multiple kinds of processors and accelerators and whatever memory devices they have hanging off them.
“It certainly can be used in that way,” says Noblett. “The industry has done a pretty good job of virtualizing almost every resource, but the interesting thing is that one of the most expensive resources – the memory – that is growing is not composable because it is trapped behind processors. A memory fabric is a way to get it out of there, and once you have a fabric and all resources are connected to it, you can compose a node architecture just like we have today through zoning or you can fully share it among all of the CPUs and accelerators in the system or the rack. Of course, the future operating system and software stack will have to be aware of this architecture. The important thing is that Gen-Z is proposing an approach that is very much compatible with architectures today but extending and not limiting architectures in the future as we get maturity across vendors in the future.”
Given the design cycles of processors, Gen-Z can’t just be dropped immediately into a chip, but there is an opportunity for a shim to be added that bridges off of a coherent bus on the chip. The real Holy Grail will be to have Gen-Z controllers native in the chips themselves, whether they are fairly monolithic designs like the Intel Xeon and Xeon Phi, AMD Epyc, or IBM Power processors, or server-class system-on-chip ARM chips like those coming out from Applied Micro, Cavium, or Qualcomm. (Using the Power9 chip as an example, if you squint a little, it is hard to tell the difference between PCI-Express 4.0, “Bluelink” OpenCAPI, or NVLink 2.0 ports, and shimming Gen-Z on top of the generic 25 Gb/sec signaling on those ports might not be too tough.) For the moment, Gen-Z will initially ride atop PCI-Express for short-haul links (within a server or within a rack) and atop Ethernet PHYs for medium and long haul links (within a rack or across racks). As for the Gen-Z targets, many peripherals are already able to support multiple modes, so shimming Gen-Z as yet another tweaked mode is not a big deal. (It will take time, of course.)
But at some point, native Gen-Z ports will be put onto server processors, accelerators, and storage and memory and native Gen-Z switches will be used, when necessary, to pool this. We think there is a very good chance that InfiniBand and Ethernet switches will have circuits added to carry the Gen-Z protocol. The important thing to remember is that the PCI-Express and Ethernet physical layers have been honed over time, and will continue to evolve, and Gen-Z will ride on top of this as well as very likely get its own native hardware with its own specific benefits, such as super-low latency. The best 100 Gb/sec InfiniBand switches (including Intel’s Omni-Path as well as Mellanox Technologies’ Switch-IB) have around 100 nanoseconds of port-to-port latency, and the average 100 Gb/sec Ethernet switch is in the range of 300 nanoseconds to 400 nanoseconds. A native Gen-Z switch would be on the order of 3X to 13X faster, and with maybe 2.5X to 8X the bandwidth.
This new Gen-Z connector is also an important innovation.

The Gen-Z connector spec was unveiled at the Flash Memory Summit a few weeks ago, and the consortium is donating it to the SNIA/SFF storage standards body to promote wide adoption. The connector makes use of Gen-Z chicklets, aggregations of bandwidth that have eight lanes of traffic each, and you can gang up one, two, or four chicklets (which is roughly analogous to the way the lanes of traffic on the PCI-Express bus are aggregated) to offer anywhere from 112 GB/sec to 448 GB/sec of bandwidth across copper wires. By comparison, a DDR4 memory slot might get you 25 GB/sec to 50 GB/sec of bandwidth, and a fat x16 slot of PCI-Express 4.0 will get you 64 GB/sec. It is not clear what the latency is on this Gen-Z slot, but it is a fair guess that it is somewhere between on-board main memory and NVM-Express flash hanging off the PCI-Express bus.
The question now is where will Gen-Z be woven into future systems? All kinds of places, it looks like.
“The initiator is going to be a CPU, and the vision there is that the PCI lanes would either be capable of PCI-Express or Gen-Z,” says Bowman. “That would go inside of a server, and you could connect to Gen-Z components inside the box either as a point-to-point connection so you get maximum bandwidth and minimal latency, or you could take it outside of the box and into a composable architecture where what you are doing is linking out to a Gen-Z switch and then out to pools of resources such as memory, GPUs and FPGAs, for instance. And longer term, this may provide some I/O functions there, too. But our initial focus is around memory expansion and composability and accelerators.”
The memory that Bowman refers to can be DRAM, flash, 3D XPoint, ReRAM, PCM, or any number of persistent memories as they come to market.

The “Hopper” GPU Compute Ramp Finally Starts
You can’t be certain about a lot of things in the world these days, but one thing you can count on is the voracious appetite for parallel compute, high bandwidth memory, and high bandwidth networking for AI training workloads. And that is why Nvidia can afford to milk its prior …

Key Hyperscalers And Chip Makers Gang Up On Nvidia’s NVSwitch Interconnect
The generative AI revolution is making strange bedfellows, as revolutions and emerging monopolies that capitalize on them often do. The Ultra Ethernet Consortium was formed in July 2023 to take on Nvidia’s InfiniBand high performance interconnect, which has quickly and quite profitably become the de facto standard for linking GPU …
Copper Wires Have Already Failed Clustered AI Systems
It has become a well known fact these days that the switches that are used to interconnect distributed systems are not the most expensive part of that network, but rather it is the optical transceivers and fiber optic cables that comprise the bulk of the cost. Because of this, and …
Intel isn’t the only x86 vendor, AMD is a member of Gen-Z and they might be able to undermine Intel and launch a CPU with a Gen-Z interface thereby pressuring Intel to get on board. I’m aware that AMD hardly has a presence in the datacenter but that could change.
“Don’t hide latency, eliminate it!” (attributed to Seymour Cray, late 1970s).
From a technology strategy point of view, the application benefits of a native Gen-Z implementation are around eliminating the latency and most of the CPU cycles in the path between the application and shared storage, or between pieces of the application running on different processors.
(Disclosure: I spent much of 2015 and 2016 working on an application of Gen-Z before “retiring” from HPE.)