
People tend to obsess about processing when it comes to system design, but ultimately an application and its data lives in memory and anything that can improve the capacity, throughput, and latency of memory will make all the processing you throw at it result in useful work rather than wasted clock cycles.
This is why flash has been such a boon for systems. But we can do better, and the Gen-Z consortium announced this week is going to create a new memory fabric standard that it hopes will break down the barriers between main memory and other storage-class memories on the horizon, giving applications a lot more bits to stretch across as they run.
As we have written about many different ways here at The Next Platform, the compute and memory hierarchies within systems and across them are expanding as new technologies come to market to augment the performance and capacity of systems. The memory hierarchy in a system has been complex for many years now, with three or four levels of cache right next to compute, one layer of main memory very close to compute, and flash and disk drives hanging off the peripheral bus or over the network. Data of record resided out on arrays hanging off the peripheral bus on non-volatile media and all of the other memory was essentially used as a temporary scratch pad for applications.
But the entry of so-called storage-class memories – those devices that are more capacious and less expensive per bit than DDR main memory but also slower – has really upset the memory hierarchy. And in a good way. These devices can be and should be addressed like main memory, with its load/store operations and related push/get and atomic operations semantics instead of the very slow way that block-level devices are addressed out on the PCI-Express bus of the system. Creating the fabric and protocol that allows these different kinds of memory devices to be addressed like main memory is what, in essence, the Gen-Z effort is all about.
“Higher performing persistent memory is starting to show up, such as 3D XPoint, PCM, ReRAM, MRAM, and there are even other technologies coming forward such as Managed DRAM and Low Latency NAND flash,” Ron Noblett, vice president of advanced development in the CTO office at Hewlett Packard Enterprise, tells The Next Platform. “You have this category of memories that no longer have the latencies that NAND flash has today, which is on the order of 50 microseconds. While flash is a lot faster than disk drives, and we have taken advantage of that like gangbusters, it is still largely in the block environment. And the reason for that is that as the percentage of software access time, when you are still in the tens of microseconds, is still a small portion of the latency. The difference with these storage class memories is that they are in the hundreds of nanoseconds of latency, and while that is not as fast as DRAM with tens of nanoseconds, it is getting close. And now the latency of the software stack going through block devices and file systems is a significant portion of the overall latency.”
Hence, something has to change. And adding the load/store semantics of main memory to these storage class memories is what the Gen-Z Consortium is trying to do.
What is clear is that each device cannot have its own proprietary interface into the system, and that the manufacturers of processors, memory, non-volatile storage, and whole systems have to work together to create a common standard that everyone can adhere to. To that end, twenty companies from around the IT industry have come together to create that standard. For processors, the Gen-Z partners include AMD, ARM Holdings, Broadcom, Cavium, and IBM. Memory and storage makers Samsung, SK Hynix, Micron Technology, Seagate Technologies, and Western Digital have also joined, as have FPGA maker Xilinx, networking vendor Mellanox Technologies, communications chip makers Microsemi and IDT, operating system maker Red Hat, and system makers Cray, Dell Technologies, Hewlett Packard Enterprise, Huawei Technologies, and Lenovo. (Some of these IT suppliers cover more than one category, obviously.)
“We think it takes a big cross section of industry participants to bring a spec like this forward,” says Kurtis Bowman director of architectures and concepts team in the CTO office at Dell Technologies and president of the Gen-Z consortium. “This is not a new concept, but we do want to do a few things. First, over the long term, we would like to see Gen-Z actually make it into the processor interface, but in the short term, it bridges off of CPUs using FPGAs or other silicon to get there.”
The one thing that is not going to change is that processors will still have directly attached DRAM memory, and until the Hybrid Memory Cube (HMC) designed by Intel and Micron or High Bandwidth Memory (HBM) designed by Samsung, AMD, and Nvidia becomes more commonplace, it will be DDR4 and DDR5 memory hanging off on-chip controllers as is done today for processors.
“The most efficient way for delivering the data that the processor needs is to have right near it,” explains Bowman. “With pooled memory, there is a new set of memory that is more democratized and so you don’t have to wait on a memory controller inside of a CPU to wait for access to it and deal with that contention; an accelerator has the same access to this memory at the same level as the CPU. This pooled memory allows you to have more memory for whatever devices you have, share the memory between the devices, and quite easily allocate that memory to new devices as they are added to the system. This pooled memory could sit inside the box if you wanted it all inside of a server.”
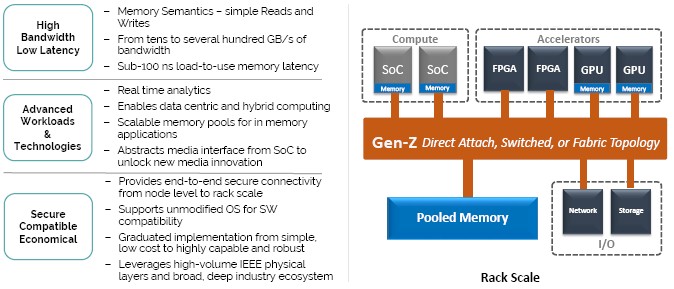
The pools of storage class memory can also exist outside of a server, perhaps in a shared enclosure, and that is the beauty of the Gen-Z approach. The Gen-Z specification has a rights management system in the protocol that gives each device on the memory fabric access to a section of pooled memory, so devices can’t overwrite each other and there is security and authentication on these pool sections so devices can’t see what they are not supposed to see.
Just like the NVM-Express protocol for linking flash devices to compute complexes in servers over PCI-Express strips down the protocol for flash down to the bare minimums and gets rid of all the unnecessary baggage that is the heritage of disk drives, the Gen-Z protocol is going to rip out a lot of garbage from the block and file heritage of storage devices and trim it down to all that is needed for storage class memories.
“It is very inefficient in the world of block and file and socket management in that with everything you do, there is a huge amount of copying of data all over the place,” explains Noblett. “There is a huge efficiency in that with Gen-Z data can sit in one place and we can pass metadata or pointers from place to place, removing all of the copying and therefore the inefficiencies. Stripping out inefficiencies in the hardware and the software is the name of the game when you have data growing exponentially, and we have a requirement to get analytics done in real time. We have to remove all of the cruft in the architectures, and a memory semantic fabric will do this.”
There is some confusion about CCIX, the coherent accelerator consortium championed by Xilinx that launched in May, the updated Coherent Accelerator Processor Interface (New CAPI) from IBM, which will come out with its Power9 processors next year, and the Gen-Z effort. At first glance, these might seem to be competing technologies, but they are actually complementary ones.
“Think of Gen-Z as the transport and then you can lay protocols on top of that,” explains Noblett. “To the degree that you choose coherency, say you want to reach out to a memory pool in a rack, you could overlay your chosen coherency protocol there. And that’s one of the things we will see with Gen-Z, CCIX, and CAPI. We are not trying to do the same things, but we are trying to be accretive and optimizing things like point to point accelerators and things like that that might be on a motherboard as opposed to the scale out pieces you might have on a motherboard, in chassis, and in rack. The way these things will roll out is with maybe some dedicated pins on those particular coherency buses. However, you can take that coherency protocol and overlay it on Gen-Z. There is a way then to optimize that as these things mature. You will see collaboration between the companies to do that.”
Adding pins to processors for memory expansion or I/O expansion of any kind is very expensive, and vendors are loathe to do it because it increases the cost of the chip and the system that uses it as well as the power draw and heat dissipation, which makes the system that much more expensive. So we are beginning to see communication circuits serve multiple purposes. For instance, IBM’s initial CAPI ports on the Power8 processors ran atop the PCI-Express 3.0 controllers on the die, running a minimalist protocol that provided memory coherency for accelerators and network cards attached to the Power8 processing complex. With the Power9 chip, an updated CAPI 2.0 protocol will run atop PCI-Express 4.0 links and a new, generic 25 Gb/sec port on the Power9 chip will be used for running what IBM Is calling New CAPI for attaching devices directly to the chip as well as for supporting NUMA links and the NVLink accelerator interconnect. So it will be with Gen-Z. The initial Gen-Z spec support running the load/store semantics over Ethernet because all chips have one of these, but other ports will no doubt be equipped to run Gen-Z, too, on future processors.
“In its initial state, Gen-Z leverages the 802.3 Ethernet PHY, but processors will have bi-modal pins that we can exploit so we don’t have to waste pins because we have to support legacy and future,” says Noblett. “The way we are likely to see Gen-Z first is on a coherency bus, and all of the system-on chip designs have one. There will be a bridge or a shim from the processor to Gen-Z. Processors take a long time to develop, so as Gen-Z matures it will be easy enough to shim onto any processors that exist now and into the future. So it has an asynchronous on ramp. Once there are enough Gen-Z devices, there will be a push for native integration on the processor. Other protocols will run atop Gen-Z, and this is just being silicon efficient.”
Now here is where it gets fun. As chip makers and their foundries get acquainted with HMC and HBM memory, Noblett says to expect more and more processors to be equipped with this as their main memory. DDR5, the spec of which is coming out this year and which could reach servers by 2020, is probably the last DRAM as we know it. And this means a few different things, we think. For one, NUMA systems (two-socket, four-socket, and larger systems) as we know them could be a thing of the past because there is no way to snoop across memory subsystems on multi-socket machines using HBM or HMC memory in a way that won’t utterly swamp the links between sockets given the bandwidths and core counts we expect in processors. (Intel explained this last year when talking about why its “Knights Landing” Xeon Phi can only be a single socket processor.) To a certain way of thinking, it is the relatively low bandwidth of memory on a CPU that allows NUMA to work at all. Unless the interconnects between CPU sockets (like Intel’s QuickPath Interconnect) get a lot faster, NUMA will only be on systems with slow memory.
The advent of these high-bandwidth, on-package memories will obviate the need for traditional DDR main memory, and the advent of storage class memories with load/store semantics that look and smell like main memory to applications will also replace what would have been DDR main memory, too. The question will then be: What do we need DDR memory for? And then we might ask how machines will be clustered together. Right now, they link through their memory, more or less. What happens when the memory hierarchy is so stratified? Does the whole world go to single-socket servers with high speed local memory and medium speed storage class memory? That could be fun, if interconnects between nodes can keep doubling.
The future that the Gen-Z Consortium envisions depends on the spec getting done and other chip makers – namely Intel – getting on board. Intel has no interest in IBM’s CAPI or Nvidia’s NVLink, and has similarly shown no interest in CCIX, either. But it could be pulled by the market into supporting Gen-Z with both its Xeon processors and its 3D XPoint storage class memory (or memory class storage if you use that term).
The Gen-Z spec is at the 0.8 level right now and is due to be completed by the end of the year; early proponents of the idea started work on it about a year ago, so it is coming along fast. When the spec is completed, code to implement Gen-Z interfaces for devices using FPGAs will also be available. Proofs of concept for Gen-Z in systems are expected in 2017, and it will probably take until 2018 to get Gen-Z products on the market, and integration into SoCs and processors will follow beyond that.


Talking System Architecture With AMD CTO Mark Papermaster
It is funny to think that in a certain light, AMD has Big Blue to thank for its resurgence in the datacenter. And not because IBM is not good at crafting processors and interconnects, but because some of the seasoned executives who honed their skills in semiconductors at IBM ended …

Intel Declares A Truce Before Bus Wars Flare Up
A system is more than its central processor, and perhaps at no time in history has this ever been true than right now. Except, perhaps, in the future spanning out beyond the next decade until CMOS technologies finally reach their limits. Looking ahead, all computing will be hybrid, using a …
How – And When – Optical I/O Will Make Disaggregated Systems Better
As many of you know from reading The Next Platform, we are firm believers that eventually we will get disaggregated and composable systems that drive up the sharing of hardware resource across many workloads and therefore drive down the cost of hardware to support workloads. This would have always been …
Seriously, the layer two is going to be Ethernet?
For a tech that will only be used in the enterprise or datacenter they should aim higher.
They do.
AFAIK its EoGen-Z (Ethernet-over-Gen-Z, Gen-Z will route Eth on top),with up to 2,8 TB (Terabytes not bits) with 128 lane cables… even with 800EGbe standard to came out when the same kind of 112Gb PAM4 SerDes is available, its kind of “legacy” (GenZ doesn’t use SerDes, should have better latencies).
On optical cables should strech as far as Eth on the same.
AFA only for the entreprise and datacenter, don’t put your money on it!.. Just look at the “connectores”, because thats the beaty of it, 1 “chiclet”, a 2C with 8 lanes and minimum 40 GB/s with the lowest 25 GT/s, is a bit smaller and less fat than the x1 PCI-E but has more bandwith than a current PCI-E 4 x16!… and the conectores are universal for cables or any kind of adapter (same kind of conector type, no matter the size, and what hangs out or misses filling), are devised very cleverly to accept any adapter with larger or smaller connectivity (interconnector fully asynchronous and fully asymetric, all lanes in a conector can go all downstream and upstream or any combination of up and down, dynamically set at link “handshake”)… and any conector can be, vertical, right angle, “slim”…
No wonder Arm and Sansung (doesn’t do servers… yet) jumped head first —> from the datacenter to your smartphone, i wont be a bit surprised.
PS: Gen-Z isn’t a cache coerency protocol… I see so much confusion!… its a *Interconnet Fabric* that speaks the language of memories (load/store/atomic), and by doing so, you can have “memory coerency” (not cache), the all virtual memory of a sistem, with very little effort, that is, with practically no modification of the software.
OpenCAPI does exactly the same thing, but its not a “physical link”, its a “layer” on top (and does not have cache coerency either, only v4 Will have support)… but relays a lot on “old legacy” software bloat. AFAIK the only True Open “Cache Coerency” protocol is CCIX (open but not free, there is some licencing for sure) … not even the venerable grand daddy of all, HyperTransport or Lightning Data Transport had “CC” without licencing… and it was, and still is, so much better than PCI-E (another Beta8 vs VHS), and had HTX conectores (and cables) that easely could accept x16 PCI-E (exactly the same form factor) with nativelly better bandwidth and much better latency (doesn’t use serdes either)… and it has provisions for power management (by now it could have DVFS, dinamically apliable from 2 lanes to the 32 of any link) … is standing still from 11 years ago, at 6,4 GT/s…
IMHO, this are the 2 things from HyperTransport that are missing in Gen-Z, 1 or 2 trully (x4 and x16, by far the most commum) “Universal Connectores” that accept PCI-E (and think AMD gave more than it looks like already), and provisions for Power Management with DVFS as target… to be perfect.