
There are so many companies that claim that their storage systems are inspired by those that have been created by the hyperscalers – particularly Google and Facebook – that it is hard to keep track of them all.
But if we had to guess, and we do because the search engine giant has never revealed the nitty gritty on the hardware architecture and software stack underpinning its storage, we would venture that the foundation of the current Google File System and its Colossus successor looks a lot like what storage upstart Datrium has finally, after many years of development, brought to market for the rest of us.
We would guess further that the relationship between compute and storage on Google’s infrastructure looks very much like what Datrium has put together with the third iteration of its DVX stack, which is, by necessity and by nature, a platform in its own right.
It is hard to say for sure, of course, because companies like Google can be secretive. While a lot of hyperconverged server-storage suppliers such as Nutanix with its Enterprise Computing Platform claim their inspiration came from Google, we don’t think that Google uses a stack anywhere as complex as the hyperconverged server-SAN half-bloods, and the people from server virtualization juggernaut VMware and storage archiving specialist Data Domain, which was acquired by EMC in 2009 and which is now part of Dell, who started Datrium in 2012 and who have raised $110 million in four rounds of funding since that time to commercialize their ideas about converging primary and backup storage while also disaggregating compute from several levels of storage and making the whole shebang cheaper and easier to manage.
“You will find, that if you know people at Google, they have had separated compute and data nodes for a long time, and the same is true of Facebook, Amazon, and so on,” Brian Biles, CEO at Datrium, tells The Next Platform. “And the reason is that at scale you have to operate that way because the rebuild times on storage are just ridiculous, and they have distributed erasure coding for data protection and the system is optimized for low latency I/O because of loads like Gmail. They also optimize for simple maintenance of their nodes. And you can even see it with Amazon with their services, where you store to instance flash but you persist in an object store that is separate. This is the same model, but it is just made private.”
Biles co-founded Datrium Hugo Patterson, who was the chief architect and then CTO at Data Domain and who before that was a member of the technical staff at network-attached storage pioneer NetApp. Boris Weissman is also a co-founder, and was previously a Java engineer at Sun Microsystems, a technical lead at LoudCloud, the cloud startup whose control system was productized as OpsWare and which was acquired by Hewlett Packard Enterprise back in 2007 for $1.6 billion, and then a principal engineer at VMware working on the core hypervisor for over a decade. Sazzala Reddy, a chief architect at EMC and Data Domain, and Ganesh Venkitachalam, who was a principal engineer at VMware and IBM, round out the company’s founders. They know a thing or two about server virtualization and storage virtualization.
Datrium DVX embodies all of the best ideas they have, and it is distinct from the hyperconverged storage out there on the market in some important ways. The reason why we are bringing up Datrium now, even though it is five years old, is that the company’s hybrid compute-storage platform is now available at petascale, which it was not before. Let’s talk about what DVX is first and then how it is different from other hyperconverged storage.
Like many modern converged infrastructure, DVX runs on commodity X86 servers using a combination of flash and disk storage and generic Ethernet networking to lash together nodes in a cluster. The DVX stack is comprised of compute nodes and data nodes, and either can, in theory, be based on any time of server customers prefer, with as many or as few sockets as they desire. For now, Datrium is letting customers pick their own compute nodes but is designing its own specific data nodes. The compute nodes are equipped with processors and main memory and have high-speed flash on them, and the combination of the two provides a place where applications and their hottest data run. Only active data is stored on the compute nodes, and anything that needs to be persisted is pushed out to the data nodes over the network. Importantly, the compute nodes are stateless, meaning they do not talk to each other or depend on each other in any way and the storage is also not dependent or hard-wired to them in any way.

The compute nodes are typically based on two-socket Xeon servers these days, and they can support VMware ESXi or Red Hat KVM hypervisors as a virtualization abstraction layer and also can run Docker containers on the bare metal if customers want to be truly Google-like. Both Red Hat Enterprise Linux 7.3 and the cheaper CentOS 7.3 alternative are supported, by the way, and the VMware stack can support Docker containers inside of the VMs if customers want to do that and nodes running KVM can also support containers atop KVM. The bare metal Docker 1.12 stack runs with RHEL or CentOS. Importantly, the compute nodes, not the data nodes, run its storage stack, which includes distributed erasure coding for data protection as well as the de-duplication and data compression technologies that Data Domain helped develop and commercialize a decade ago.
Biles is not revealing all of the feeds and speeds on the data node, but it is a dual-controller OEM disk enclosure based on a modest X86 processor with some NVRAM packed in to persist a replica of the hot data on the compute hosts and to front end a dozen 7,200 RPM SATA disks that provide the raw persistent capacity. Biles jokes that this enclosure has just enough oomph to drive the disks, which at 100 MB/sec of bandwidth for each drive is just enough to saturate a 10 Gb/sec Ethernet link. Each data node uses inexpensive 4 TB disk drives, for a total raw capacity of 48 TB for the enclosure and after all of the de-duplication and compression works on the data and after the overhead of erasure coding is taken out, there is about 100 TB on the data node. This, quite frankly, is not a balance set of compute and data, and the Datrium folks knew that.
So for the past several years, they have been perfecting a wide erasure coding technique that can distribute data chunks evenly across a pool of data nodes that have been networked together, and adapting the de-duplication pool so it spans multiple data nodes. Most of the code for this updated erasure coding and de-duplication stack runs on the compute nodes, not the data nodes, so there is no reason to suddenly need very hefty data nodes as is the case with a lot of hyperconverged storage. And equally importantly, that global object storage pool that underpins the DVX stack lets each compute node spread its data across the compute nodes in a stateless fashion so none of the compute nodes are dependent on the other for access to their persistent data. This is what Datrium calls split provisioning.
The upshot is that the DVX platform now offers the ability to independently scale compute and storage, and with the most recent 3.0 release, it can scale both a lot future. In the initial release that has been shipping since early last year, the compute cluster could scale to 32 nodes, but they only shared one data node. This was severely limiting on the use cases. But starting with this update, the compute can scale to 128 nodes, with one, two, four, or eight sockets each customers choose, and the data nodes can scale to ten in the storage cluster.
All of the elements of the DVX stack can be linked using modest and dirt cheap 10 Gb/sec Ethernet adapters and switches on the nodes, but in some cases, lower latency or higher bandwidth switching might help. It call comes down to cases. Biles says that support for 25 GB/sec and 40 Gb/sec is coming in the near future.
With the expanded DVX stack, the data nodes can scale to up to 1 PB of effective capacity, and importantly for enterprise customers, handle up to 1.2 million concurrent snapshots of datasets.
This snapshotting is part of the backup and protection that is integrated into the DVX stack, and it is one of the reasons why customers who are used to having primary data storage and backup storage (something like the virtual tapes on disk arrays that Data Domain created) will spend a lot less money if they just have a single stack with snapshots for cloning data and erasure coding for spreading the data out for performance and high persistence.
Those 128 compute nodes can crank through 200 GB/sec of reads off of the storage nodes, and in aggregate they can process 18 million IOPS against the local flash on their nodes, which in turn pull data off the disk nodes when needed.
Here is the performance profile of the DVX cluster as it scales compared to that of a typical all-flash array, according to Datrium:
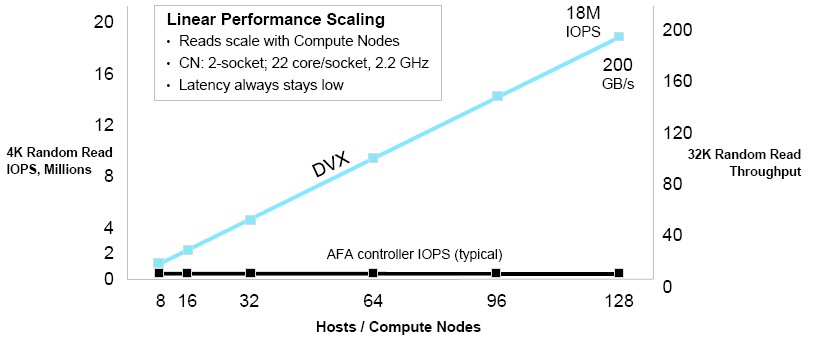
The write performance of the DVX stack scales with the number of data nodes and, to a certain extent, to the NVRAM that is in the enclosure. Here is how Datrium says the DVX clusters compare to EMC’s XtremIO clustered flash arrays.
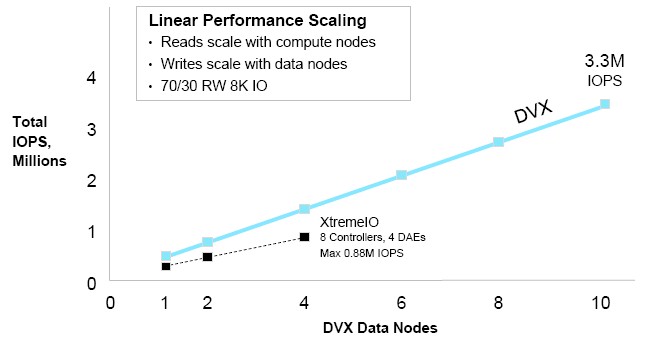
The important thing to note here is that Datrium is getting the same or better performance on reads and writes as all-flash arrays using a mix of DRAM and flash on stateless compute nodes and NVRAM and disks on data nodes. Now we understand why Google is so keen on advancing the state of the art of disk technology. If you need exabytes of capacity, as hyperscalers do, you can’t afford to go all flash. Enterprises, which have relatively modest datasets and often have no more than a few petabytes, can do this. And, as the sales of Pure Storage and other all-flash array makers demonstrates, this is precisely what they are doing. It is just funny that the most advanced companies in the world have no choice but to keep a technology that is sixty years old already alive for another decade.
That leaves us with explaining how this kind of simple convergence is different from hyperconvergence.
First of all, the compute nodes are completely stateless, and that means that applications running on one node can be isolated from those on the other. They are isolated from each other’s faults and crashes and not woven into a single compute fabric. The machines can be of distinct types and therefore the performance requirements of the software can be matched to the hardware. this is not the case with hyperconverged stacks, which tend to be homogeneous. Second, because storage is broken from compute in a stateless manner, there is fault isolation between the compute and data nodes. With hyperconverged software, if a node goes down, it is a problem for the entire cluster as that node’s data is restored. The other interesting difference is that the hyperconverged stacks out there need to be in an all-flash configuration, which can be very pricey, for de-duplication, compression, and other data reduction techniques to work at an acceptable performance, but Datrium’s DVX can do it on a mix of flash, NVM, and disk. And finally, hyperconverged stacks tie compute to storage within a node, and you can’t scale up one without the other. (This is something the hyperconvergers need to fix.)
The two DVX components for compute and storage are sold and priced separately, and given the fact that they scale independently this makes sense. The software for the compute nodes cost $12,000 per server, and the data node costs $94,000 each. So a top-end cluster with 128 nodes might cost $25,000 for a hefty server node with lots of cores, RAM, and flash plus another $12,000 for the DVX compute software, or $4.74 million across the compute infrastructure with maybe 7,200 cores and as many virtual machines and ten times as many containers, with terabytes of memory and tens of terabytes of flash. The ten data nodes, you are talking another $940,000 in addition to that, and after some modest discounting, you might get it all for maybe 25 percent off or around $4 million. That assumes the use of open source software, and adding commercial ESXi or KVM would balloon this cost even more. Still, that is a lot less expensive than buying primary flash and disk inside of compute nodes and then having to buy a separate petascale class backup array.
A company like Google can get its iron for half that price, but it has to create its own software, and that is not free, either, even if it is fun. Imagine what 100,000 nodes, like the hyperscalers put into one datacenter, actually costs with all the hardware, software, and people costs fully burdened.

Pushing Up The Scale For Hyperconverged Storage
Hyperconverged storage is a hot commodity right now. Enterprises want to dump their disk arrays and get an easier and less costly way to scale the capacity and performance of their storage to keep up with application demands. Nutanix has a become as significant player in a space where established …
** Datrium Employee ** Thanks, Timothy. BTW, just to clarify the paragraph where “Biles is not revealing feeds …”
DVX Data Nodes receive data pre-erasure-coded, pre-inline compressed, encrypted, etc. from Compute Nodes (hosts with DVX software). Data Nodes do some coordination and HA, but array-controller-like functions are all elsewhere; what’s left for them to do is drive IO. They just have an internal object interface to each drive, redundant hardware for HA, and NVRAM for fast writes. They’re very stripped down on CPU to keep costs low. The 12 drives collectively, and the 10Gb net connection, can get up to about 1GB / sec. at a hardware limit.