
It is like the world is turned on its head.
What is the last place on earth where a massive number of disk drives will be unplugged? The hyperscalers who have convinced us to store massive amounts of data-laden content on their cloudy infrastructure. Where is the first place that will move completely to non-volatile media for primary storage? The enterprise.
Those hyperscalers, the epitome of cutting edge technology, will be forced into using spinning rust for the foreseeable future – unless the volumes for disk drive shipments fall so low that the cost per gigabyte stagnates – precisely because we will be smart enough to let them carry the burden of all of that dense data and push disk drive technology to its extremes in terms of density and I/O performance. The hyperscalers and the clouds wanted our data, and it looks like they are going to get it.
So it is not surprising, then, that at the File and Storage Technologies 2016 conference this week that Eric Brewer, vice president of infrastructure at the search engine giant, presented a paper he did with fellow Googlers Lawrence Ying, Lawrence Greenfield, Robert Cypher, and Theodore Ts’o that made the case that the disk drive industry – which for enterprise storage has consolidated down to Seagate Technology, Western Digital, and Toshiba – has to reconsider form factors and other features to make spinning rust work better for the hyperscalers and cloud builders.
As Brewer points out in a blog post announcing the paper behind the presentation, the storage services offered by Google, Facebook, Baidu, Microsoft, Yahoo and a string of hyperscalers as well as the more formal cloud builders aiming at enterprise markets (mainly Amazon Web Services, Google, Microsoft, IBM SoftLayer, Rackspace Hosting, and the major telcos and a few others) already account for a large portion of disk drive sales, and it will not be long before these companies account for the majority of disk revenues and shipments. We certainly won’t be seeing the PC market, which used to carry the volumes, rebound any time soon, and with enterprises managing much smaller data sets than hyperscalers (in part because enterprises will shift the dense material to the cloud, in part because people have to store our pictures and videos somewhere), the hyperscalers and cloud builders are in a unique position to dictate terms to the few remaining suppliers that build spinning disks.
The FAST 2016 paper, which you can read here, was a gentle nudge for the industry to start thinking outside of the box. Google has some pretty intense storage requirements, and to make its point, Brewer trotted out some statistics about the growth of storage behind the YouTube video streaming service. If you can find an enterprise with 1 PB or 2 PB of data, that is a lot of storage for a commercial company. Even the largest Global 2000 companies (in terms of their storage, not their revenues) might have something on the order tens of petabytes of aggregate capacity across their various arrays and clusters. But YouTube users are uploading more and more videos and the capacity needs are going up exponentially, with the curve currently at a 10X increase every five years. Check it out:
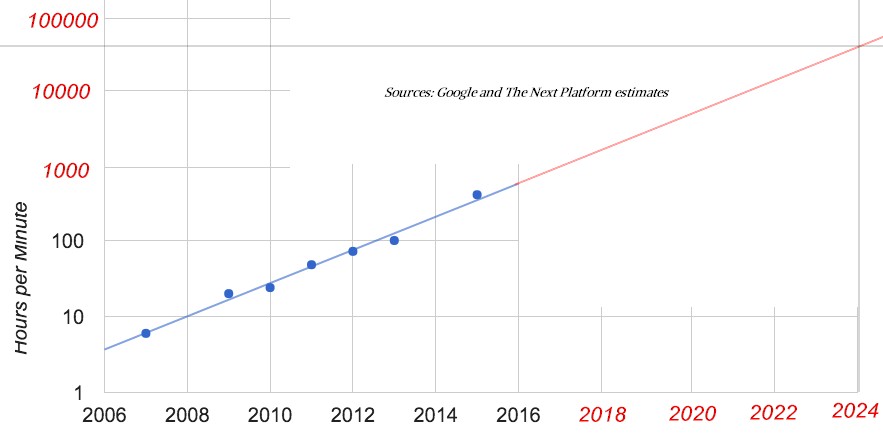
As 2015 was coming to a close, YouTube users were uploading 400 hours of video content every minute of the day, and at that rate, that works out to 1 PB of raw capacity each day. The density of video content is going up as we use higher resolution recording devices, and the number of people using YouTube is also increasing, and we would also guess that people, on average, are also adding more videos, too, driving this exponential growth that Google is showing for YouTube storage in the blue data above.
So, what happens if we extrapolate into the future? If you plot the curve out, which we did with the red line, then by 2024 or so, YouTube users should be uploading something like 50,000 hours of video per minute, and assuming a constant size for the datasets, Google will then have to install 125 PB of capacity per day by our math, which is 45.6 exabytes per year. It could be much larger unless the data can be compressed as resolutions rise on that video content, balancing it out some. That capacity would require 2.3 million 20 TB disk drives per year, to give you some perspective, and at around $500 a pop if such a drive could meet the performance requirements (which it can’t), that is $1.15 billion just to buy the disks.
This is a staggering amount of data to have to store and a lot to spend, too, and it is no wonder that Google wants to see some more innovation in the disk drive market on which it will depend to provide its storage services and also that will be back-ending its search engine indexing and other data analytics services unless non-volatile storage suddenly gets a lot less expensive.
Interestingly, because Google’s own infrastructure and eponymous file system has redundancies within regions and across datacenters to ensure data is never lost, Brewer and his peers argue that the disk drive industry has to focus less on the reliability of an individual disk drive and more on a collection of disk drives that can act in unison without going all the way to RAID data protection that is commonly deployed in enterprises.
“We need to optimize the collection of disks, rather than a single disk in a server,” Brewer says. “This shift has a range of interesting consequences including the counter-intuitive goal of having disks that are actually a little more likely to lose data, as we already have to have that data somewhere else anyway. It’s not that we want the disk to lose data, but rather that we can better focus the cost and effort spent trying to avoid data loss for other gains such as capacity or system performance.”
Google’s wish list for future disk drives includes higher capacity, lower seek times for drives and therefore higher I/O per second bandwidth, lower tail latencies for the outliers that it often encounters in its online services, better and more stringent security, and a lower total cost of ownership.
What Google is arguing for in the paper is for the industry to come up with a collection of disk drives that act as a unit and within that unit provide a mix of capacity and IOPS that meets its requirements for both better than picking one drive would. Google also wants to have a disk drive lose one of its heads and still function, so capacity and sunk money is not wasted.
Here is how the Google techies visualize how to make the choices:
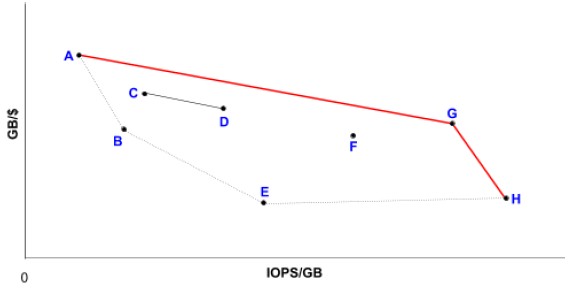
So areal density moves a particular technology up, and platter rotational speed or shrinking platter sizes move it to the right, and the aggregate performance of the disk collectives to exploit is based on the lines drawn connecting the drive types. In the chart above, the red line AGH is one possible collective, line CD is another one, and line ABEF is yet another. The trick, argues Google, is being able to exploit both the capacity and IOPS of the drives and across the collective. “This works well as long as we can get most of both the capacity and IOPS out of each drive, which is not easy,” Google writes in its paper. “The industry is relatively good at improving GB/$, but less so at IOPS/GB.”
To fix this, Google has some ideas, and we have a sneaking suspicion that the company has already created such hybrid collective disks to underpin its Google File System and Colossus file systems. The big trick is to label incoming I/O and data requests as either latency or throughput sensitive and apply quality of service rules to those reads and writes to not only prioritize when and how information is moved around, but where it lands within the collective. We also presume (although the paper does not say this) that it would be desirable to automatically move data between different drives in a collective based on whether it is getting hotter or colder over time. In essence, Google seems to be arguing that a disk drive as we know it should be more like a hybrid array, offering a much better mix of capacity and throughput because of its hybrid nature.
On the security front, Google wants much simpler disk drive firmware that is not so susceptible to bugs and therefore security risks that can be exploited. Google also wants a kind of multi-tenant security encryption key mechanism added to the disk collectives, allowing for encryption at rest for data and also allowing for data from myriad customers to be encoded and stored on the same collection of drives. While enterprise-class disks have encryption today, they do not have this multi-tenancy capability for encryption.
Interestingly, Google is also arguing for a change in the form factor of disk drives, and questions whether the 2.5-inch and 3.5-inch form factors that dominate the industry are necessarily the right size. Given that Google wants a mix of high capacity and high IOPS across its collectives, it might want to see a move back to 5.25-inch and 1.8-inch platters, sizes that have been used in the past in the industry. Google also thinks the industry should be looking at making disk drives for clouds and hyperscalers taller, since that adds capacity and amortizes the packaging and circuitry for the drive control over a larger capacity. Google also thinks it is a good idea to add more actuator arms to drives to read more data more quickly from the drive – and says this is not a new idea. (Google cites dual-arm drives made by Conner Peripherals back in the dot-com boom, but IBM was doing this back in the early mainframe days for the same reason.)
Among the other suggestions Google is making includes moving the caching from the drives out to the storage tray or the server host accessing data; adopting a single 12 volt power standard instead of the mix of 3.3, 5, and 12 volt power used by enterprise disks today; optimized conventional and shingled magnetic recording (SMR) formatting techniques on a single drive to strike a balance between IOPS and capacity in a single drive, perhaps by having two different heads on the drive; and increasing the disk sector size from 4 KB to 64 KB or larger to reduce the error correction overhead per unit of capacity.
You will notice that Google did not say the future of its storage was flash or any other kind of solid state media, and Brewer and his colleagues explained why. “The root reason is that the cost per GB remains too high, and more importantly that the growth rates in capacity/$ between disks and SSDs are relatively close (at least for SSDs that have sufficient numbers of program-erase cycles to use in data centers), so that cost will not change enough in the coming decade. We do make extensive use of SSDs, but primarily for high performance workloads and caching, and this helps disks by shifting seeks to SSDs.”
It looks like Seagate and Western Digital have a lot of work to do. The question is, will they be able to do it fast enough to satisfy the needs of the hyperscalers and cloud builders? And will there be any other customers for these products over which to spread the cost?


Google Gives A Peek At What A Quantum Computer Can Do
Four years ago, Google engineers boasted of achieving “quantum supremacy” following experiments that showed its 53-qubit Sycamore quantum system solving problems that classical supercomputers either can’t or take a very long time to accomplish. At the time, Google was slapped around by rivals in the quantum space, with competitors like …

Why Dropbox’s Exascale Strategy Is Long-Term, On-Prem Disk
The various life-extension technologies that will keep disk at the forefront of some of the largest storage installations are working–and keeping disk’s largest consumers, like Dropbox, around for long haul… When it comes to exascale storage capacity, the national labs have nothing on Dropbox. The company’s custom-built system for storing …

Anthropic Fires Off Performance And Price Salvos In AI War
It is a strange time in the generative AI revolution, with things changing on so many vectors so quickly it is hard to figure out what all of this hardware and software and people-hours costs and what it might be worth when it comes to transforming, well, just about everything. …
I feel that soon Backblaze will enter in hyperscalers league, they manage more than 200 Petabytes of customer data. By the way, they publish from time to time a report filled with real figures showing HDD reliability.
Funny you should mention that. I was just looking at some of their disk data.
Mr Timothy Prickett Morgan , while your articles show some insight and thoughtfulness, the title including “Spinning Rust” is insulting to the scientists, engineers and other professionals in magnetic recording. It is attention grabbing, following the intellectual manner of the New York Daily News. Perhaps you could be less insulting and more reasonable in your headlines?
Way back in the day the B6700 at my Jr. College had a head per track platter hard drive with one fixed R/W head per track! It was about the size of a washing machine and had an inner seismically isolated case enclosed by an outer case, to prevent all hell breaking loose should some operator accidentally bump into the thing and upset those large and fast spinning platters! The UNIVAC 1100 series had the FASTRAND II random-access mass storage system with two huge drums rotating in opposite directions at 880 revolutions per minute, the thing weighed as much as a station-wagon! Those drives if they got out of hand could really make a mess of data, people, and brick and mortar.