

Supercomputing centers around the world are preparing their next generation architectural approaches for the insertion of AI into scientific workflows. For some, this means retooling around an existing architecture to make capability of double-duty for both HPC and AI.
Teams in China working on the top performing supercomputer in the world, the Sunway TaihuLight machine with its custom processor, have shown that their optimizations for theSW26010 architecture on deep learning models have yielded a 1.91-9.75X speedup over a GPU accelerated model using the Nvidia Tesla K40m in a test convolutional neural network run with over 100 parameter configurations.
Efforts on this system show that high performance deep learning is possible at scale on a CPU-only architecture. The Sunway TaihuLight machine is based on the 260-core Sunway SW26010, which we detailed here from both a chip and systems perspective. The convolutional neural network work was bundled together as swDNN, a library for accelerating deep learning on the TaihuLight supercomputer
According to Dr. Haohuan Fu, one of the leads behind the swDNN framework for the Sunway architecture (and associate director at the National Supercomputing Center in Wuxi, where TaihuLight is located), the processor has a number of unique features that couple potentially help the training process of deep neural networks. These include “the on-chip fusion of both management cores and computing core clusters, the support of a user-controlled fast buffer for the 256 computing cores, hardware-supported scheme for register communication across different cores, as well as the unified memory space shared by the four core groups, each with 65 cores.”
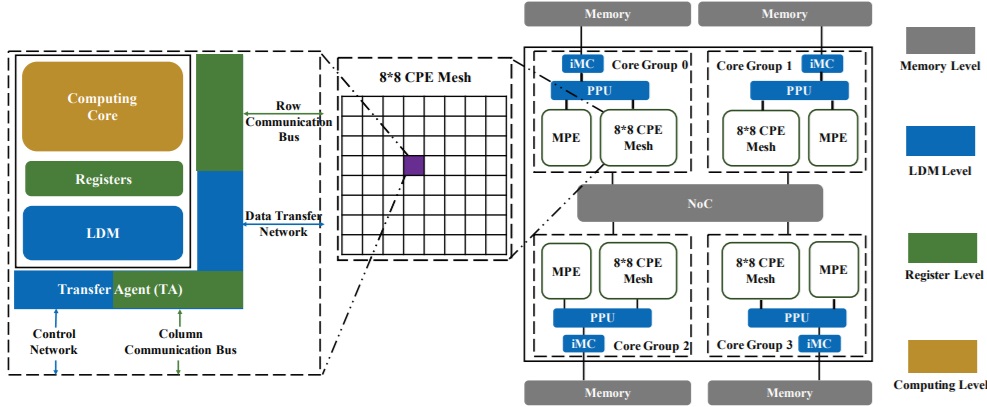
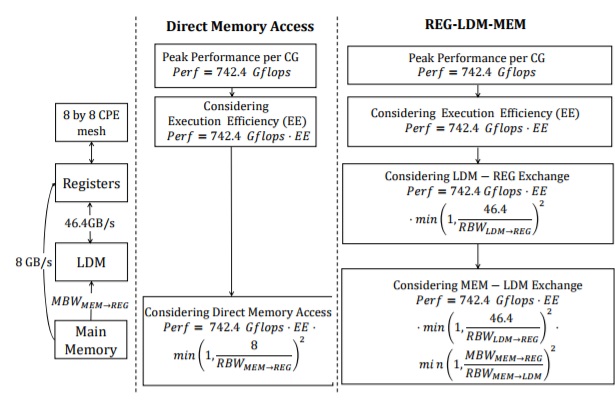
Despite some of the features that make the SW26010 a good fit for neural networks, there were some limitations teams had to work around, the most prominent of which was memory bandwidth limitations—something that is a problem on all processors and accelerators tackling neural network training in particular. “The DDR3 memory interface provides a peak bandwidth of 36GB/s for each compute group (64 of the compute elements) for a total bandwidth of 144 GB/s per processor. The Nvidia K80 GPU, with a similar double-precision performance of 2.91 teraflops, provides aggregate memory bandwidth of 480 GB/s…Therefore, while CNNs are considered a compute-intensive kernel care had to be taken with the memory access scheme to alleviate the memory bandwidth constraints.” Further, since the processor does not have a shared buffer for frequent data communications as are needed in CNNs, the team had to rely on a fine-grained data sharing scheme based on row and column communication buses in the CPU mesh.
“The optimized swDNN framework, at current stage, can provide a double-precision performance of over 1.6 teraflops for the convolution kernels, achieving over 50% of the theoretical peak. The significant performance improvements achieved from a careful utilization of the SW26010s architectural features and a systematic optimization process demonstrate that these unique features and corresponding optimization schemes are potential candidates to be included in future DNN architectures as well as DNN-specific compilation tools.”
According to Fu, “By performing a systematic optimization that explores major factors of deep learning, including the organization of convolution loops, blocking techniques, register data communication schemes, as well as reordering strategies for the two pipelines of instructions, the SW26010 processor on the Sunway TaihuLight supercomputer has managed to achieve a double-precision performance of over 1.6 teraflops for the convolution kernel, achieving 54% of the theoretical peak.”
Part of the long-term plan for the Sunway TaihuLight supercomputer is to continue work on scaling traditional HPC applications to exascale, but also to continue neural network efforts in a companion direction. Fu says that TaihuLight teams are continuing the development of swDNN and are also collaborating with face++ for facial recognition applications on the supercomputer in addition to work with Sogou for voice and speech recognition. Most interesting (and vague) was the passing mention of a potential custom chip for deep learning, although he was non-committal.
The team has created a customized register communication scheme that targets maximizing data reuse in the convolution kernels, which reduces the memory bandwidth requirements by almost an order of magnitude, they report in the full paper (IEEE subscription required). “A careful design of the most suitable pipelining of instructions was also built that reduces the idling time of the computation units by maximizing the overlap of memory operation and computation instructions, thus maximizing the overall training performance on the SW26010.”
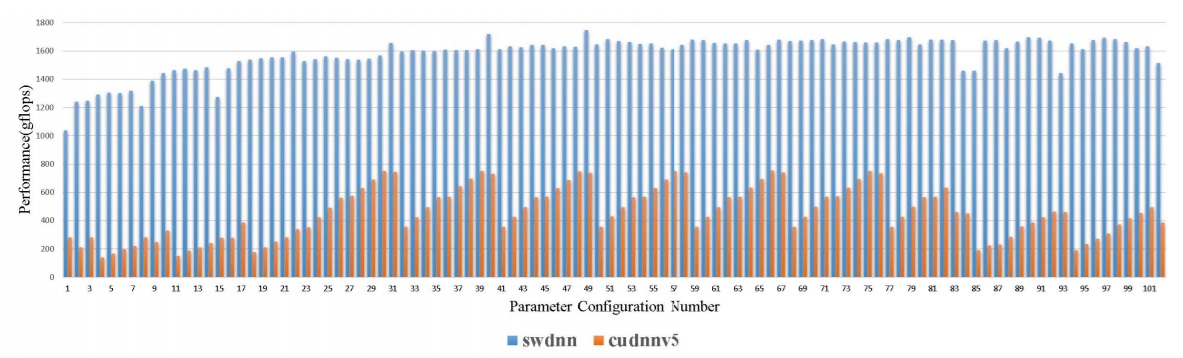
To be fair, the Tesla K40 is not much of a comparison point to newer architectures, including Nvidia’s Pascal GPUs. Nonetheless, the Sunway architecture could show comparable performance with GPUs for convolutional neural networks—paving the way for more discussion about the centrality of GPUs in current deep learning systems if CPUs can be rerouted to do similar work for a lower price point.
The emphasis on double-precision floating point is also of interest since the trend in training and certainly inference is to push lower while balancing accuracy requirements. Also left unanswered is how convolutional neural network training might scale across the many nodes available—in short, is the test size indicative of the scalability limits before the communication bottleneck becomes too severe to make this efficient. However, armed with these software libraries and the need to keep pushing deep learning into the HPC stack, it is not absurd to think Sunway might build their own custom deep learning chip, especially if the need arises elsewhere in China—which we suspect it will.
More on the deep learning library for the Sunway machine can be found at GitHub.


The Nitty Gritty Of The Sunway Exascale System Network And Storage
We took a look recently at the compute engines at the heart of the future – and as yet unnanmed – Sunway exascale system that will be installed at the National Supercomputing Center in Wuxi, China. This exascale machine will be a follow-on to the current Sunway TaihuLight system, both …

Why Did China Keep Its Exascale Supercomputers Quiet?
There are no greater bragging rights in supercomputing than those that come with top ten listing on the bi-annual list of the world’s most powerful systems – the Top500. And there are no countries more inclined to throw themselves (and billions) into that competition this decade than the U.S. and …
A First Peek At China’s Sunway Exascale Supercomputer
The trade war between the United States and China is not just a top-down political and economic one, but also a technical one. And one could argue that the Sunway TaihuLight supercomputer that was unveiled in June 2016 with mostly indigenous technology rather than chippery that was Made in America …
I wouldn’t really call the Taihu Light the world’s top performing supercomputer at all. It is the top performer in HPL, which is becoming less and less relevant as systems get larger.
Its actually one of the worst performing systems in terms of its peak FLOPS compared to its HPCG FLOPS. Its only 0.4% in that.
It is beaten by the ancient K Computer in both HPCG and Graph500, despite having almost 10x the peak FLOPS of K. Its also beaten by the old Tianhe 2 in HPCG as well. Both of those benchmarks are becoming more relevant as systems get larger.
Taihu Light went in the opposite direction for byte/FLOP and memory capacity per node that real pre exascale and exascale architectures are moving towards.
Well the clouds certainly are starting to cover of nVidia HQ and it is going to get worse as the Chinese are more and more likely going to move to homegrown solutions and there big players going to dominate the AI sector in Asia. Both nVidia and Intel are going to run into serious trouble in the near future.