

This fall will mark twenty years since the publication of the v1.0 specification of OpenMP Fortran. From early loop parallelism to a heterogeneous, exascale future, OpenMP has apparently weathered well the vicissitudes and tumultuous changes of the computer industry over that past two decades and appears to be positioned to address the needs of our exascale future.
In the 1990s when the OpenMP specification was first created, memory was faster than the processors that performed the computation. This is the exact opposite of today’s systems where memory is the key bottleneck and the HPC community is rapidly adopting faster memory technologies such as stacked memory.
To put the 1990s compute capability in perspective for today’s readers, the leadership class ASCI Red supercomputer was the first supercomputer to achieve 1 teraflops performance when it delivered a world record 1.06 teraflops of performance on the Linpack benchmark in December 1996. The system was powered by 9,298 single-core 200 MHz Intel Pentium processors. ASCI Red was also the first supercomputer installation to consume a megawatt of power (the machine itself consumed 0.85 megawatts), which provided a glimpse into our modern power and cooling challenges as the scientific community tries to build the first exaflops supercomputer. Vectorization, thanks to Seymour Cray, was the route to parallelism on most supercomputers (but not ASCI Red). The multithreaded parallelism that is now common on everything from mobile phones, televisions, routers, tablets, and of course HPC supercomputer clusters was but a nascent technology.
To overcome the CPU bottleneck, vendors in the 1990s sold plug-in CPU boards that could boost system performance. These processor plugins were not computing cores like the cores of today’s cache coherent cores, multicore, and many-core processors, but rather separate single-core processors that exploited the excess bandwidth of the system’s shared RAM memory.
Threading models were still new at that time. In the 1990s, multithreaded codes were generally considered as a way to perform tasks asynchronously. Heavyweight threads were separate processes that were considered by most to be too expensive for most applications due of the extra memory capacity they consumed. Instead, lightweight threads (like pthreads) were preferable because they shared most resources and consumed much less memory. Further, the HPC community realized that multithreaded applications could run on multiprocessor systems to deliver greater performance. Not only were there computational advantages, but memory advantages as well since shared memory was more efficient to access rather that calling routines in the Message Passing Interface (MPI) library to move data between assumed separate distinct memory spaces. The threading debates back then closely resemble modern offload versus shared memory debates concerning accelerators and co-processors as well as the hybrid MPI/OpenMP versus plain vanilla MPI debates. Shared memory versus the runtime overhead to move data via a messaging protocol is still a hot topic today.
Similarly, modern debates over pragmas (which are advisory messages about parallel or optimization opportunities) versus lower-level languages like CUDA and OpenCL resemble 1990s era OpenMP versus threading model debates. Succinctly, pragmas are considered higher-level and easier to use and lower level APIs offer more features and potentially more performance. The challenge back then was the lack of standardization as every vendor created its own set of pragmas to exploit their particular parallel hardware. This was the genesis of the OpenMP standard that now provides a way for thread-based parallelism to be expressed so that is portable across systems and compilers.
Success bred more success as the initial Fortran v1.0 standard was followed by the C/C++ OpenMP specification a year later.
James Reinders was heavily involved in the ASCI Red project at Intel. “At the same time as the first OpenMP drafts were being debated,” Reinders recalls, “ASCI Red was making parallel computing history. The whole concept of massively parallel computing was relatively new and somewhat controversial so it was a very big deal when a bunch of X86 processors connected together became the world’s fastest computer and the first to deliver a teraflops. It might not be obvious that ASCI Red and OpenMP 1.0 both come several years before SIMD floating point (SSE) would appear in X86, and a decade before the first multicore X86 processors. OpenMP 1.0 was very timely for the explosion of parallelism that the 1990s was ushering in.”
Those involved in code modernization know that performance today is achieved by the use of both parallelism across cores and the use of vectorization to exploit the performance of the per core vector units on modern multiprocessors. An Intel Xeon Phi 7210 processor, for example, has 64 cores with two vector units per core. Thus the thread-parallelism focus of earlier OpenMP standard has been forced to adapt.
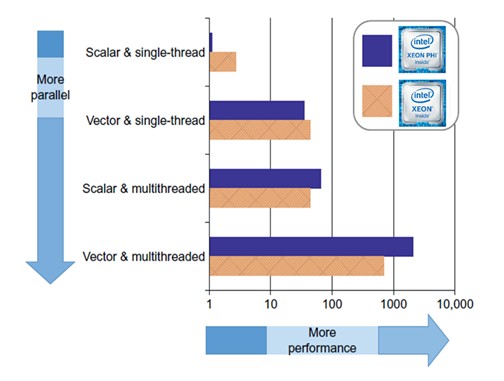
However, the HPC community needed to wait two years after the v1.0 OpenMP specification for vector capabilities on Intel processors to be introduced. The initial set of SSE (Streaming SIMD Extensions) were introduced in the Pentium III processors in 1999. Still, HPC advocates noted that running on two single-core processors could deliver 2X the performance and further that some high-locality applications like ANNs (Artificial Neural Networks) could achieve 4X the performance when using multiprocessing in a shared memory environment. Just as today, the HPC community back then viewed hardware that could deliver a 2X or 4X speedup as exciting, it’s just that the speedup was achieved without vectorization.
Unfortunately, the original SSE instruction set only provided 32-bit floating-point math operations, so there was not a perfect match as HPC is heavily dependent on double precision floating point math. This explains why the introduction of SSE2 was in 2001 considered a big step forward. Suddenly, all those Cray-era vector codes could run at full performance on Pentium 4 processors with SSE2 and the era of commodity multithreaded, vector processors was born.
Of course, OpenMP is a natural for the development of vector parallel codes, but OpenMP continued to focus on loop level parallelism utilizing threads until the introduction of the SIMD construct in 2014. Until then vectorization was handled either by the compiler (via auto vectorization) or explicitly by the programmer via intrinsics. An intrinsic is a line of code that specifies the actual vector instructions much like assembly programming.
After the introduction of the SSE instruction set, the Intel ISA underwent a rapid expansion as more vector functions as well as vector instructions of varying lengths were added. In particular, the industry started exploring the performance implications of wide-vector lengths. The Itanium processor was the first Intel product to exploit wide-vector length instructions and this processor project really pressed the limits of both the hardware and software technology of that time.
For example, the systems management team at Pacific Northwest National Laboratory (PNNL) are very proud that an early version of their NWPerf monitoring software identified a remainder loop issue in one version of the Itanium compiler where the floating point operations transparently exceeded the allocated array space under some circumstances. The error was transparent because the results were correctly masked off so the program produced the right results. However it took NWPerf to identify that a storm of floating point exceptions that would intermittently cause a big drop in application performance. Once identified, the compiler was quickly fixed but the challenge lay in initially finding out why a big scientific code would occasionally exhibit drastic performance drops even though the application reported correct results.
This is but one of many lessons that were learned from Itanium. For example, the modern AVX wide-vector instructions have collision detection as well as a number of performance enhancing features like hardware scatter/gather to help with sparse vector operations.
With vectorization left to the compiler or programmer, the OpenMP ARB focused on expanding parallelization beyond the highly regular loops such as those used in matrix computations that were the focus of the initial v1.0 OpenMP specification. Around the 2005, the OpenMP community started working on the inclusion of task-parallelism. As the usage of thread parallelism increased during this time, Cilk introduced the concept of work stealing to help with load-balancing thread-parallel programs. The basic idea behind work stealing is that, “if a thread runs out of work then it is assumed it has the time to hunt for and steal work from other threads.” Cilk led to the development of the more C++ oriented thread parallelism of Cilk+ and the Intel Thread Building Blocks (TBB) C++ template library. However, these C++ template-based approaches don’t provide the compiler with additional information for parallelization like the OpenMP standard. Thus the compiler does not have as many optimization opportunities plus this may become important for heterogeneous computing as we will see.
The focus on task-parallelism was solidified in the versions 2.0 and 3.0 of the OpenMP specification. In particular, the version 3.0 specification released in 2008 included the concept of tasks and task constructs. After 2009, the industry then saw a resurgence of incompatible pragma specifications with the advent of offload-based programming for parallel hardware such as accelerators (like GPUs) and the introduction of co-processors such as the Many Integrated Core coprocessors (MIC) architecture. MIC is now known as the Intel Xeon Phi product family. During this time, vendors each added their custom pragmas to their compilers to support offload programming. For example, Intel created its own offload pragma set in the Intel compilers, the now defunct CAPS Enterprise created another pragma set called HMPP (Hybrid Multicore Parallel Programming), and other vendor efforts such as the OpenACC standard started to appear.
The OpenMP v4.0 specification from July 2014 added support for accelerators, atomics, error handling, thread affinity, tasking extension, user defined reductions, along with SIMD and Fortran 2003 support. This was a big set of additions to the standard and even though the OpenMP specification as of 2017 is now at version 4.5, many compilers (and OSes) are still working to implement the full v4.0 (and v4.5) specification.
The addition of the SIMD clause is important for modern vector/parallel HPC performance programming as it ensures consistent performance across platforms. In effect, the SIMD clause says, “This is a vector loop and I as the programmer take responsibility that it will vectorize correctly.”
The reason is that vectorization has become much more important to the performance of OpenMP codes. For example, the early SSE2 ISA could deliver a potential 2X performance boost over unvectorized code as two single-precision operations could be performed per vector instruction. Today, the Intel AVX-512 instruction set found in the Intel Xeon Phi processor, for example, can deliver a 16X single-precision performance boost or an 8X performance boost for double precision over unvectorized code. For the HPC community, a 16X performance increase is spectacular and a transparent 16X performance drop is unacceptable. Thus getting a failure when forced vectorization via a SIMD loop fails is now considered a good thing, because the programmer can fix the issue right then.
Looking ahead, it is likely that heterogeneous systems are going to be a constant in our lives.
At the moment, heterogeneous programs are difficult to write as the programmer must think how two different devices operate. This is potentially a big opportunity for the OpenMP ARB as pragmas tell the compiler about the parallel work and further offload pragmas provide information about where the computation is to be performed. It is possible to envision a future where the compiler is also told about various targeted devices in the heterogeneous environment so it can generate appropriate parallel and “glue code” to meld a heterogeneous system into a unified, high performance whole. Perhaps targeting very low power yet high performance massively parallel hardware is the way to our heterogeneous, exascale future. If so, heterogeneous OpenMP can help get us there and work stealing may again become a hot topic in the OpenMP community.
Rob Farber is a global technology consultant and author with an extensive background in HPC and in developing machine learning technology that he applies at national labs and commercial organizations. Rob can be reached at info@techenablement.com.

NSF Puts $10 Million Into Composable Supercomputer
If they are doing their jobs right, the high performance computing centers around the world in academic and government institutions are supposed to be on the cutting edge of any new technology that boosts the performance of simulation, modeling, analytics, and artificial intelligence. Not the bleeding edge, where the hyperscalers …
Intel’s Chips No Longer Pay More Than Their Fair Share Of Foundry Costs
The biggest benefit that is coming from the separation of the Intel chip design and marketing business from its foundry operations is that Intel’s chip product groups no longer have to shoulder the totality of the immense costs of its manufacturing operations. The biggest downside is that they these chip …

Intel Targets DAOS Object Storage At More Than HPC
Intel is looking to position itself as a leader in AI and HPC through a holistic approach that plays to the company’s strengths across a broad swath of the IT ecosystem. This covers not just silicon hardware such as CPUs and ASICs, but also the firm’s expertise in open software …
“The Itanium processor was the first Intel product to exploit wide-vector length instructions and this processor project really pressed the limits of both the hardware and software technology of that time.”
What? IPF had the same multimedia-oriented 64-bit SIMD as everything else. IPF SIMD was expressly referred to as an idiomatically-compatible evolution of both PA-RISC MAX and Intel MMX.