

Enterprises are awash in data, and the number of sources of that data is only increasing. For some of the larger companies, data sources can rise into the thousands – from databases, files and tables to ERP and CRM programs – and the data itself can come in different formats, making it difficult to bring together and integrate into a unified pool. This can create a variety of challenges for businesses in everything from securing the data they have to analyzing it.
The problem isn’t going to go away. The rise of mobile and cloud computing and the Internet of Things (IoT) will only add to a situation that already has been exacerbated for many of these large companies by years of mergers and acquisitions, which has resulted in multiple and disparate systems being brought together under one roof and silos of data that can’t always be reconciled. Many times enterprises not only can’t unify the data into a usable pool, but they often can’t get a good reading on exactly what data they have. In a business world that is turning to data analytics to help companies better serve their customers, drive up revenues and improve efficiencies, not having hundreds of silos of unreconciled data can be a significant competitive disadvantage.
In addition, an enterprise without a good understanding of what data they have and where that data is runs the risk of corporate data going out the door and having no way of knowing that the data is lost or stolen.
The situation has given rise to a growing trend around data unification and data preparation – bringing the diverse data together into a single catalog and getting it ready so it can be more easily accessed, analyzed and used in a variety of different ways. There are any number of large and well-established data management vendors out there – think IBM, SAS and Informatica – but, as with most emerging needs in the tech industry, the drive for greater data unification and preparation is giving rise to a growing number of startups that are offering a broad array of self-service software products designed to make it easier and faster for businesses to get a better grasp of their rapidly growing stores of data. Among those is Tamr, a four-year-old company that started as a project in MIT’s Computer Science and Artificial Intelligence Lab (CSAIL) and has since grown into a company with offices in both Cambridge, Mass., and San Francisco, about 70 employees and more than $42 million from two rounds of funding. The US Patent Office today issued a patent to Tamr for the core principles of its data unification platform.
Company officials have looked to differentiate the company from the host of other startups – such as Alation, Paxata and Looker – by focusing primarily on large enterprises that have dozens or hundreds of data sources that need to be cleaned up and unified. Many of the self-service software products now are aimed at situations where a single data analyst may need to unify, prepare and analyze data points from a couple of sources, but those products won’t scale to the extent needed by huge corporations, Toffer Winslow, growth and marketing lead at Tamr, told The Next Platform. It’s only by bringing together “dozens and thousands of data sources can you get the benefits of big data,” Winslow said.
Tamr does this in large part by leveraging machine learning binning algorithms – aided by expert input – to take all the data that’s been cataloged into an enterprise data repository and identifying connections among attributes and features of the data and among data entities and records. Doing so enables the data that is housed in the repository to be used for multiple tasks. Using the machine learning capabilities both reduces the number of components that need to be compared from all the data points available and determines the probabilities that the product in data point A is the same thing as the one in data point B, Ihab Ilyas, co-founder of Tamr and professor of computer science at the University of Waterloo, told The Next Platform.
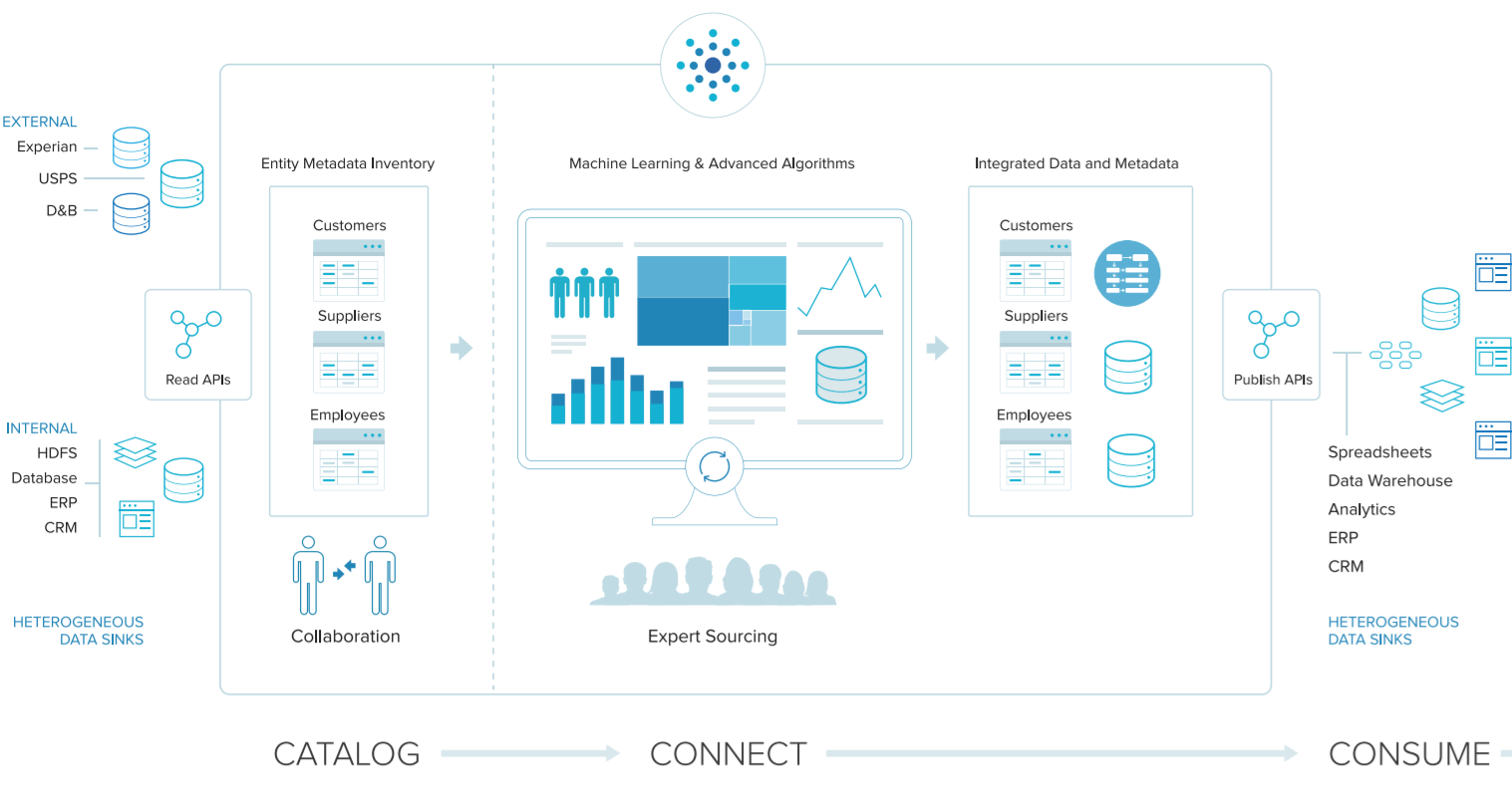
Tamr’s namesake software creates an organized inventory of a company’s information assets through such features as a connector and API, source tagging and collaboration and metadata visualization capabilities. It taps into data sources such as JDBC, file systems, content management systems like Sharepoint and Documentum, and big data stores like Hive, Amazon S3 and Google Cloud Storage, and scours such formats as CSV, XLSX, relational databases, semi-structured data like JSON and XML, and full text. The Tamr software runs on Linux operating systems, such as CentOS and Oracle Linux, and runs on such databases as Oracle, Postgres and Spark. It can run in the Google Compute Engine, Amazon EC2, VMware and Citrix virtualization environments.
The first step is cataloging the data from various information assets to create the company’s central data repository and global schema for the data. It’s also at this layer that the significance of data entities and features of the data sources are determined to help build the machine learning models, with such issues as feature selection also being aided by expert input. Connections and links among data entities and sources are then made by leveraging the machine learning algorithms and handling such issues as deduplication, schema discovery and schema mapping. Once connections are made, the data can be consumed through such models as an organization’s ETL solution, growing the connections and mappings of the existing data sources and creating a consolidated view of the data.
Large enterprises are looking for ways to better unify and use their vast data resources, Ilyas said. Tamr’s technology is designed to reconcile the disparate data to find connections. A product in one data source may be listed by name, by a file number and name in another and by a name and location in a third. In addition, a person’s name may be written one way in one file and then misspelled in another. Finding the connections in these situations to enable the creating of a central repository is crucial, the officials said.
Winslow talked of one large industrial customer that had grown over the past couple of decades through a series of acquisitions. “As a result, they have hundreds of procurement systems,” he said. “They data is not all on one version of Ariba or SAP. Some of the systems are home-grown, others are off-the-shelf.” By unifying the data and creating links, the company is able to get a better view of their products, customers, suppliers and workforce, and use the data to keep better track of its information and negotiate better pricing in its supply chain.
Tamr has a growing customer lineup of well-known corporations, including GE, Toyota, Thomsen Reuters, HP and Amgen. The company is seeing early adopters in such industries as pharmaceuticals and life sciences, financial services and big industrial manufacturing, all of which have common threads running through them.
“Many these companies have a history of growing through acquisitions, and they decentralized sites that deploy all of their own IT,” Winslow said. “The combination of the two things creates a lot of data silos.”


Baidu Takes FPGA Approach to Accelerating SQL at Scale
While much of the work at Baidu we have focused on this year has centered on the Chinese search giant’s deep learning initiatives, many other critical, albeit less bleeding edge applications present true big data challenges. As Baidu’s Jian Ouyang detailed this week at the Hot Chips conference, Baidu sits …
Pivotal Opens Up More Of Its Platform
Just a few years ago, using a new kind of tool such as the Hadoop data muncher was sufficient to gain competitive advantage in many industries. But now, incumbents in just about every sector of the global economy are facing challenges from upstarts, what Pivotal – the database, analytics, and …
Be the first to comment