
With the current data science boom, many companies and organizations are stepping outside of their traditional business models to scope work that applies rigorous quantitative methodology and machine learning – areas of analysis previously in the realm of HPC organizations.
Dr. Franz Kiraly an inaugural Faculty Fellow at the Alan Turing Institute observed at the recent Intel HPC developer conference that companies are not necessarily struggling with “big” data, but rather with data management issues as they begin to systematically and electronically collect specific data in one place that makes analytics feasible. These companies, as newcomers to “machine learning” and sometimes also statistical modeling, are unsure about potential benefits (or limitations) of the data science hype. In-principle they are much more interested in acquiring solutions that allow testing to determine if some analytics strategy is sensible, rather than in acquiring a specific method from the ever growing zoo of analytics and machine learning solutions.

While ATI is the hub, the collaboration includes the Engineering and Physical Sciences Research Council—UK’s main funding agency for engineering and physical sciences research – and the following universities: Cambridge, Edinburgh, Oxford, Warwick and University College London.
The goal of the collaboration is to help make sense of the billions of gigabytes of data generated globally every day, and their powerful impact on our society, economy and way of life. They have selected a diverse map of opportunities where their data science could potentially be applied and have the most effective impact.
In his talk, Data Analytics, Machine Learning, and HPC in Today’s Changing Application Environment, Kiraly discussed the use of parallelism and high-performance computing in high-level Python and R machine-learning packages. He stressed the importance of adhering to the scientific method to get meaningful results by checking that the trained model is good. In other words, to validate that the model derived from the training set is a sensible one.
Dr. Kirlay takes a method-agnostic approach, which means he works with many data analytics applications. This generality requires architectural flexibility. He notes that, “Running on CPUs seems more natural in the method-agnostic world simply due to the larger architectural flexibility, while GPUs might be (and are usually) used to run specific methods – such as neural networks.”
“Running on CPUs seems more natural in the method-agnostic world simply due to the larger architectural flexibility, while GPUs might be (and are usually) used to run specific methods” – Dr. Franz Kirlay (Alan Turing Institute)
“What to put on CPU and what on GPU seems an open question”, Kirlay observes, “but we still lack software that allows unified access to methods (such as in scikit-learn) plus advanced HPC capability, as well as quantitative benchmarking which would compare machine learning algorithms on different architectures”. He summarized this view by stating, “We don’t know what works, so CPUs seem a natural place to start”.
Kirlay uses both work stations and the Legion compute cluster at University College London (UCL). Legion is a Dell cluster with nodes of different types including a node with Intel Xeon Phi processors and other nodes with various CPU and GPU configurations. He added, “I do not run large enough jobs for Grace” (the 684 node Intel Xeon processor E5-2630v3 compute cluster), but “I do use the Emerald GPU cluster as I am using general-purpose machine learning packages such as scikit-learn and mlr, which have rudimentary CPU parallelization support (scikit-learn via joblib that distributes to cores), but for which GPU interfaces do not exist”. According to the scikit-learn Frequently Asked Questions (FAQ) as of Jan 2017, GPU support is not planned because, “It will introduce many software dependencies and introduce platform specific issues”.
Case Studies
Dr. Kiraly presented three stylized case studies in his Intel HPC developer conference talk.
- A situation where a hospital specializing in the treatments of a certain disease wants to know which patients are at-risk to experience an adverse event such as death.
- A retailer wants to accurately model the behavior of customers so they can predict based on past behavior what products each customer may purchase in the future.
- A manufacturer wishes to find the best parameter settings for their machines that can reduce the MTBF (Mean Time Between Failures) while producing the greatest amount of high quality products.
Big Data
One of the most important questions a data scientist must answer is “how does the customer know that I am not playing expensive computer games with their money?” In other words, the algorithm/model must be deployable and solve the real-world task for the customer.
As shown by Lapedes and Farber in “How Neural Networks Work”, machine learning is effectively fitting a model to a high dimensional surface. The more complex the problem, the bumpier the surface, which means that data must be provided to define each important point of inflection in the surface. Thus complex problems require big training sets.
The sheer size of big data means that data scientists have to think about the data and processing the data in a modeling context. In practice, this translates to using a cluster to perform HPC tasks and to perform data cleaning along with preprocessing to convert the data into a form that is amenable to the machine learning package. In particular, Kiraly notes that “data cleaning may take the majority of the man power in a machine learning project”. He believes that, “data quality is not separable from data modeling”.

Kiraly recommends using data resampling to train and assess the performance of machine learning algorithms. Resampling splits the entire data set into multiple training and test sets. The data scientist trains a learner on each training set, which is then used to predict on a corresponding test set. The prediction (or inference) results are assessed according to some performance measure. Then the individual performance values are aggregated, typically by calculating the mean.

The mlr (Machine Learning in R) toolbox (mentioned below) supports various resampling strategies:
- Cross-validation (“CV”),
- Leave-one-out cross-validation (“LOO””),
- Repeated cross-validation (“RepCV”),
- Out-of-bag bootstrap and other variants (“Bootstrap”),
- Subsampling, also called Monte-Carlo cross-validaton (“Subsample”),
- Holdout (training/test) (“Holdout”).
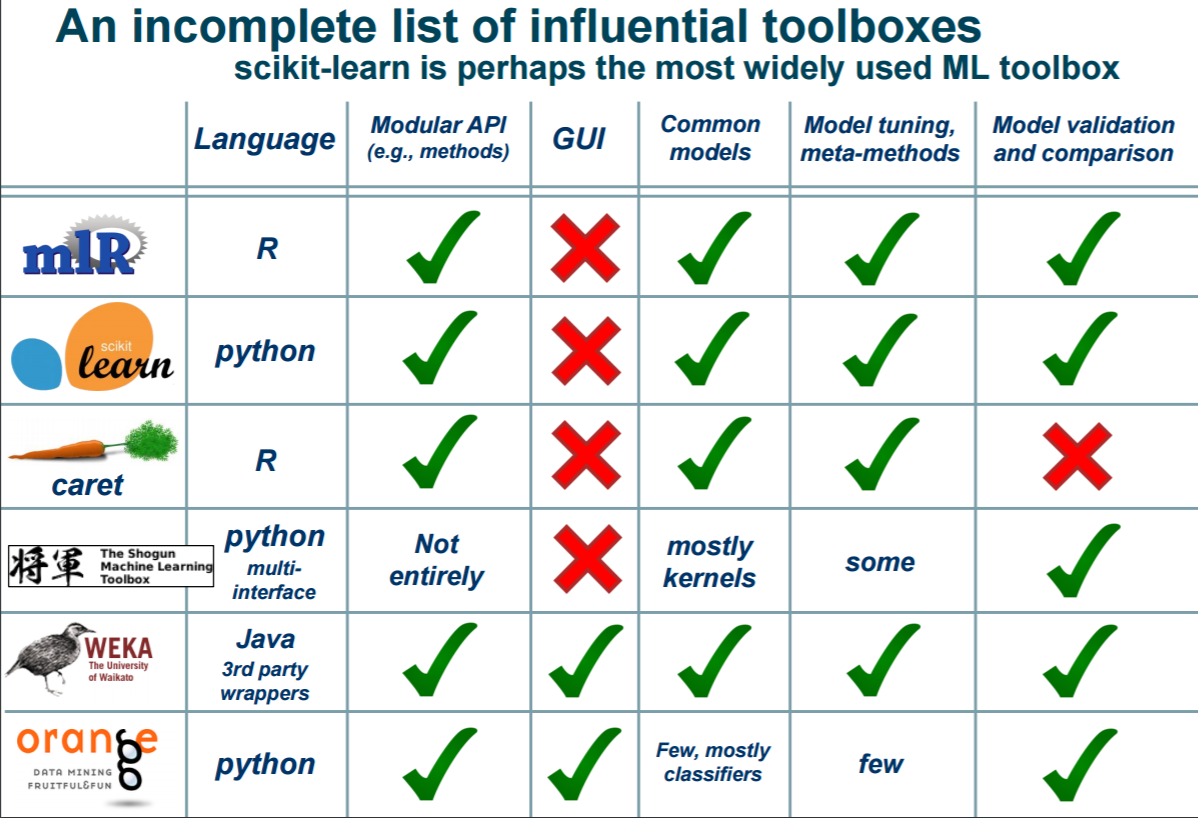
Tool boxes
Dr. Kirlay presented a number of popular machine learning toolboxes that are written in both Python and the R programming language. He observed that most popular by far is the Python based Scikit-learn.
Intel has provided an optimized version of scikit-learn for IA (Intel Architecture) processors in the Intel distribution for Python. Python (both 2.7 and 3.5) versions are available for Windows, Linux, and Mac OS. The current release delivers performance improvements through the use of Intel Math Kernel Library, Intel Message Passing Interface, and Intel Threading Building Blocks libraries along with threading improvements. It is freely downloadable from the Intel Registration Center.
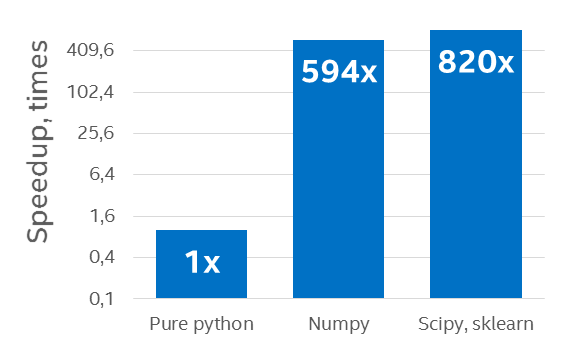
Speedup on a 96-core (with Hyperthreading ON) Intel Xeon processor E5-4657L v2 2.40 GHz over a pure Python example using the default Python distribution (Results courtesy Intel)[i]
While the current machine learning packages provide a number of useful features that are generally usable without extensive programming, Dr. Kirlay observed that more work needs to be done to provide time-series prediction and other more advanced techniques to the existing packages.
Summary
The advent of high-performance, highly-parallel CPUs is opening the doors to new approaches and expanded business models. Many companies and organizations are now stepping outside of their traditional business models to scope types of work that applies rigorous quantitative methodology and machine learning to create value from the data they are collecting – types of analysis traditionally reserved for High Performance Computing but which are now available to everyone due to advances in computing power. The open source software is there, as is the data and computational capability which is why more and more organizations are becoming data analytic experts. The key is to adhere to the scientific method to provide meaningful results that can be deployed to generate value.
Rob Farber is a global technology consultant and author with an extensive background in HPC and in developing machine learning technology Rob can be reached at info@techenablement.com.
[i] Configuration Info: – Fedora* built Python*: Python 2.7.10 (default, Sep 8 2015), NumPy 1.9.2, SciPy 0.14.1, multiprocessing 0.70a1 built with gcc 5.1.1; Hardware: 96 CPUs (HT ON), 4 sockets (12 cores/socket), 1 NUMA node, Intel(R) Xeon(R) E5-4657L v2@2.40GHz, RAM 64GB, Operating System: Fedora release 23 (Twenty Three)


Python Could Reset the AI Inference Playing Field
When it comes to neural network training, Python is the language of choice. But for inference, code needs to be transformed to meet the various hardware performance and device limitations. This has meant that the various AI inference hardware makers have had to build comprehensive custom software stacks to handle …
Is Mojo The Fortran For AI Programming, Or More?
When Jim Keller talks about compute engines, you listen. And when Keller name drops a programming language and AI runtime environment, as he did in a recent interview with us, you do a little research and you also keep an eye out for developments. The name Keller dropped was Chris …

Making AI Run At Any Scale But Not At All Costs
AI is arguably the most important kind of HPC in the world right now in terms of providing immediate results for immediate problems, and particularly for enterprises with lots of data and a desire to make money in a new economy that does not fit models and forecasts before the …
I really do not understand the last chart, with blue bars.
The brains behind Spark processing engine are trying a holistic approach based on a run time called WELD.
The results are impressive:
Weld provides speedups of up to 6x for Spark SQL, 32x for TensorFlow, and 30x for Pandas.
Weld: A common runtime for high performance data analytics
https://cs.stanford.edu/~matei/papers/2017/cidr_weld.pdf
Data are provided by Intel, so don’t take them seriously (remmeber when they stated that they beated Nvidia in AI?).
It can be just comparison of genericly compiled poorly optimised version versus pervectly tuned hand optimised…
Optimisations like fitting problem into pipeline, optimising memory prefetch of utilising new instructions (FMA4 can do 32 operations per single clock but compilers rarely utilise it)…
We even dont know how oroginal version works on multi-core and multi-cpu envinroment. There must be reason why they used 2x12C instead of single 24C
I believe in a similar dream except mine is based on FPGAs. You should only have to learn how to program one device. The Stratix 10 SoC can do things that processors can’t do like pipeline thousands of operations so you don’t have to use memory as much.
If a sea of processors was the way to go we’d all be using 1024, 386 cores. You have to get away from ALU + REGFILE as your compute unit and have something much more flexible. having a little tight ALU that runs at high speed only worsens the dark silicon problem.