

At the annual Supercomputing Conference (SC16) last week, the emphasis was on deep learning and its future role as part of supercomputing applications and systems. Before that focus, however, the rise of novel architectures and reconfigurable accelerators (as alternatives to building a custom ASIC) was swift.
Feeding on that trend, a panel exploring how non-Von Neumann architectures looked at the different ways the high performance computing set might consider non-stored program machines and what the many burgeoning options might mean for energy efficiency and performance.
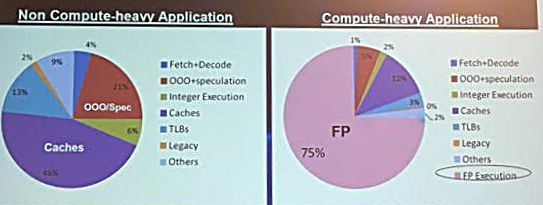
Among the presenters was Gagan Gupta, a computer architect with Microsoft Research, who detailed the inherent inefficiencies of Von Neumann architectures and various ways his company is considering workarounds, including by the use of FPGAs. “For non-compute intensive applications only about 6% of the power is consumed by the execution units, which means that remaining power is being spent marshalling the program and the data around these units. And if the application is compute-intensive, the efficiency is better with 75% of the power performing the actual computation, but there is still that 25% inefficiency.” This is the “Von Neumann tax” Gagan says, and getting around this is the Microsoft team’s goal for both applications and datacenter functions.
“Our objective has been to reduce this Von Neumann tax as much as possible while still accelerating different applications and functions. If you look at the options for doing this, there is a long list of tradeoffs,” Gagan explains. “Von Neumann architectures are the most flexible but offer the lowest energy efficiency and performance per watt. A dedicated ASIC would give us the best performance per watt, although at the cost of flexibility. This is where we found FPGAs could strike the right balance between flexibility, performance per watt, and the ability to accelerate many different functions within the datacenter.”
A vast portion of Microsoft’s datacenters now deploy FPGAs, with one per server blade. As Gagan explains it, there is one conventional server plane for hardware acceleration using FPGAs, which are connected using conventional networking infrastructure that already exists. Each server uses conventional CPU machines with an FPGA that is directly connected to the network for fast access to data. As we have covered in the past, this is how the company was able to accelerate Bing search on the application side (by mapping search algorithms, feature extraction, expression analysis, scoring, etc.) directly onto the FPGA for a doubling of throughput and latency reduction of 30%. To get to this point, Gagan says that this benefit came at an additional cost of less than 30% and an additional power footprint of about 25% compared to a CPU-only system approach.
In addition to acceleration of Bing, the company has also accelerated the networking stack for its Azure cloud. “We implemented software defined networking inside the FPGAs, which has given us very low networking latencies. We also use FPGAs on the network to speed encryption and decryption off the main processor,” Gagan says. Interestingly, Microsoft is thinking along the same lines as Intel.Just as we described following a chat with Intel’s VP and GM of the Xeon and Cloud groups, Jason Waxman, future datacenters with accelerated elements can be considered in terms of pools versus a singular, homogenous whole.
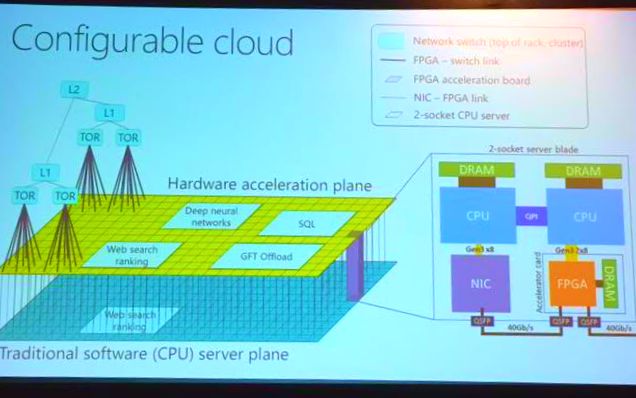
What Intel looks at as a rack-level sense of datacenter operation, Microsoft calls a “configurable cloud” in which there is a “conventional compute layer, a converged network and an additional layer of reconfigurable chips” wherein all pieces can work concurrently for underlying functions (network virtualization, for instance) or as pools to boost a particular machine learning, search, or other application.
By enabling the FPGAs to generate and consume their own networking packets independent of the hosts, each and every FPGA in the datacenter can reach every other one (at a scale of hundreds of thousands) in a small number of microseconds, without any intervening software. This capability allows hosts to use remote FPGAs for acceleration with low latency, improving the economics of the accelerator deployment, as hosts running services that do not use their local FPGAs can donate them to a global pool and extract value which would otherwise be stranded. Moreover, this design choice essentially turns the distributed FPGA resources into an independent computer in the datacenter, at the same scale as the servers, that physically shares the network wires with software.
Even though this is the future direction of the datacenter from Microsoft’s point of view, like Waxman, there is no fear that the traditional CPU is going away anytime soon. From legacy applications to vanilla datacenter workloads, it will continue to play an important role. However, if one trend has certainly been clear over the last two years in particular, it is that the datacenter at nearly all hyperscale and large-scale enterprises will be shifting toward ever-increasing levels of heterogeneity with FPGAs, custom ASICS, and GPUs leading the pack.

What Will AMD Do With Programmable Logic And Other Xilinx IP?
AMD has finished its acquisition of Xilinx, which ended up costing close to $49 billion instead of the original $35 billion projected when the deal was announced in October 2020 thanks to the rise of AMD’s shares over the past year and a half. And now, with AMD getting the …

What’s Next for FPGA Maker Achronix Post-IPO?
In addition to covering momentum in the FPGA market overall, from the first inklings that compute acceleration could be a large opportunity to recent acquisitions of the two largest FPGA device makers by Intel and AMD, we have kept an eye on FPGA startups. While there haven’t been many, those …
Xilinx Works From The Edge Towards Datacenters With Versal FPGA Hybrids
The “Everest” family of hybrid compute engines made by Xilinx, which have lots of programmable logic surrounded by hardened transistor blocks and which are sold under the Versal brand, have been known for so long that we sometimes forget – or can’t believe – that Versal chips are not yet …
It is probably the only way forward to get actual more compute performance out in upcoming generations of architectures. As all the performance gains both in CPU and also now in GPU are slowing down considerable from generation to each next generation. Bad news for end consumers though they will likely not benefit from this in having faster computation in their end device as things are concentrating more and more in the hand of big powerful hyperscalers