

The bi-annual rankings of the Top 500 supercomputers for the November 2016 systems are now live. While the top of the list is static with the same two Chinese supercomputers dominating, there are several new machines that have cropped up to replace decommissioned systems throughout, the momentum at the very top shows some telling architectural trends, particularly among the newcomers in the top 20.
We already described the status of the major Chinese and Japanese systems in our analysis of the June 2016 list and thought it might be more useful to look at some of the broader trends affecting supercomputing, particular in terms of processor, accelerator, and vendor momentum.

We are at the edge of seeing a new wave of systems from the CORAL procurements crop up and by this time next year the Top 500 will have more energy than it has recently. This hinges on the availability of a few enabling technologies, including the availability of Knights Landing (and eventually Knights Hill), the Omni-Path interconnect, and more system-level enhancements including wider adoption of burst buffers.
Ultimately, this list shows that the more things change, the more they stay the same. Despite the availability of higher performance processor SKUs, upgrades to accelerators, including the jump from the Nvidia Tesla K40 to the K80, and more hands on Knights Landing parts, the performance is still creeping along for the bulk of the list.
The times they are certainly changing–and in ways that some might not have been expecting. Despite a push toward exascale machines, the ability to run deep learning frameworks in tandem with simulation data is expected to change the way HPC makers think about building machines for the supercomputing set. For instance, we saw this morning that Cray announced a new supercomputer product, called the XC50, which is outfitted with the latest generation Pascal GPUs and that their release emphasized the role of these accelerators in pushing both simulation and neural network performance.
On that note, consider that just a few years ago the big story in supercomputing was the momentum around accelerators with a tense battle for future systems between Intel’s Xeon Phi coprocessor and Nvidia Tesla GPUs. At that time, the massive parallel capabilities of the GPU were being used to enhance simulation performance on heavy matrix multiply jobs–the same thing, it turns out, that makes GPUs a fit for neural networks and machine learning. The parts for HPC have lacked the lower floating point that the deep learning market is driving inside Nvidia, but with Pascal and the ability to handle mixed precision to 16 bits, we could see a real shakeup.
If you take a look at the chart below, you’ll see that the adoption of accelerators is not as strong as it used to be. However, an accelerator for the purposes of this list means there is an offload model so the new Knights Landing parts, which are self-hosted, no longer count as accelerators and new GPU system acquisitions are slowing down.
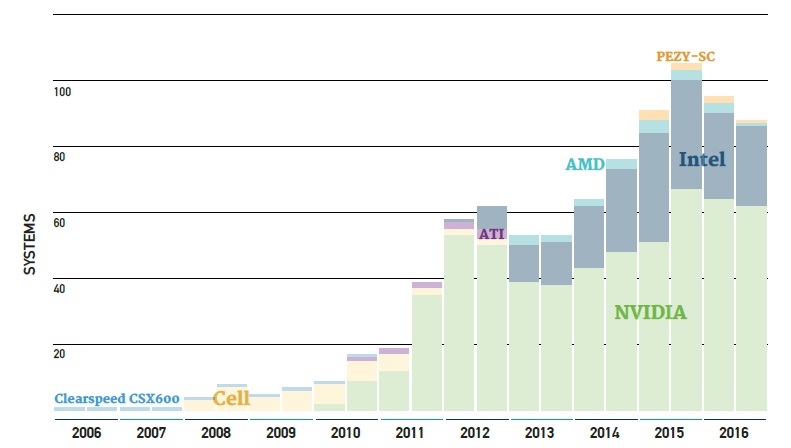 Before making too many assumptions about this GPU system slowdown, recall the deep learning hook for HPC, which has really taken full shape (at least in terms of how it might fit into HPC workflows and future systems) over the last six months.
Before making too many assumptions about this GPU system slowdown, recall the deep learning hook for HPC, which has really taken full shape (at least in terms of how it might fit into HPC workflows and future systems) over the last six months.
If traditional simulation customers begin integrating deep learning into their shops, this could mean big business for GPUs in HPC again—just as GPUs are even bigger business than many expected following the release of Pascal.
While we expect there to be a shift in the number of GPU systems because of this deep learning acceleration push on large supercomputers over the next year, the same cannot be said of the general processor trendline for HPC—at least not yet.
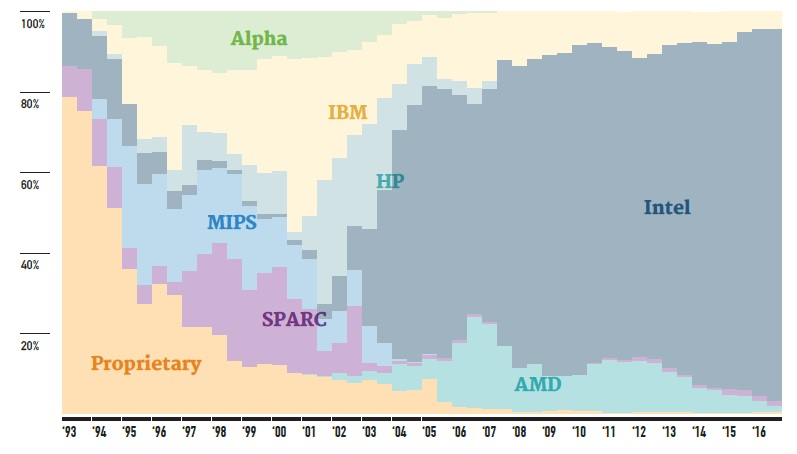
Indeed, IBM is pushing for greater share of Power-based machines on the Top 500, ARM sees a path to taking up to 25% of the market eventually (overall, not just in HPC), and of course, AMD finally has a chance to make a comeback with its Zen processors when those start shipping in the second half of 2017. But even the most optimistic watcher of HPC processor trends cannot see all of these, with a few novel architectures thrown in, as capable of pulling more than 25% or so off that steady Intel share pictured.
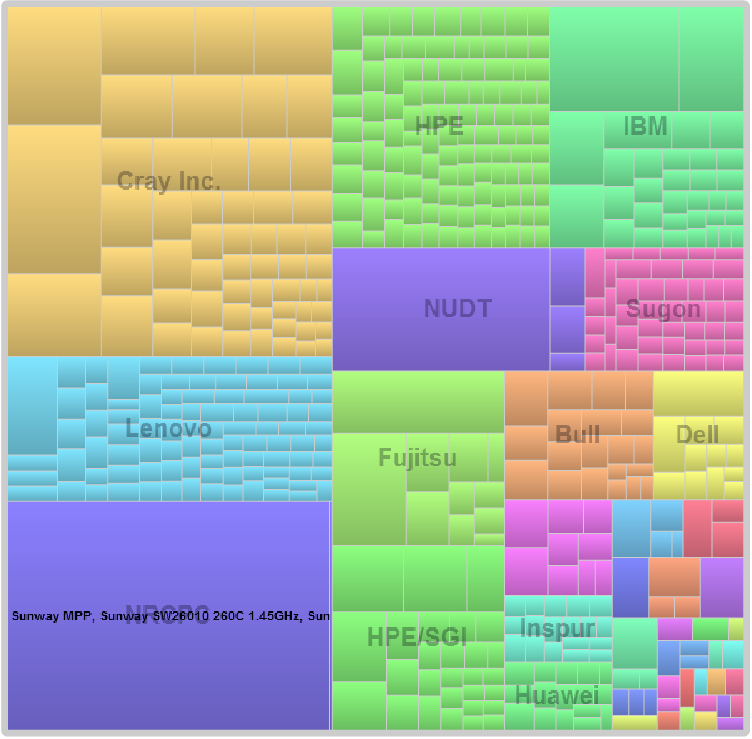
Even with that lack of diversity in the processor ecosystem on the Top 500, several vendors are able to carve out niches. The most notable example here is Cray, which as seen in the chart below, doesn’t have as many systems as some of the others, is slicing off quite a piece of the performance pie.
From a higher level view, the performance improvements of the list are not as dramatic in many cases (and certainly not as consistent) as they have been in the past. As you can see below based on Top 500 data since 1999, the sum of the performance of the overall list is falling off the projected line. This started in around 2014 and hasn’t really caught up, even with the addition of a few monster machines at the top. This is influenced in part by the relatively recent addition of many smaller systems from web companies and others adding bulk to the list for certain countries but with lower performance profiles, but could also signal a shift for smaller academic and research centers using smaller, dense clusters that are focused on specific applications and more HPCG benchmark-oriented results than Linpack.
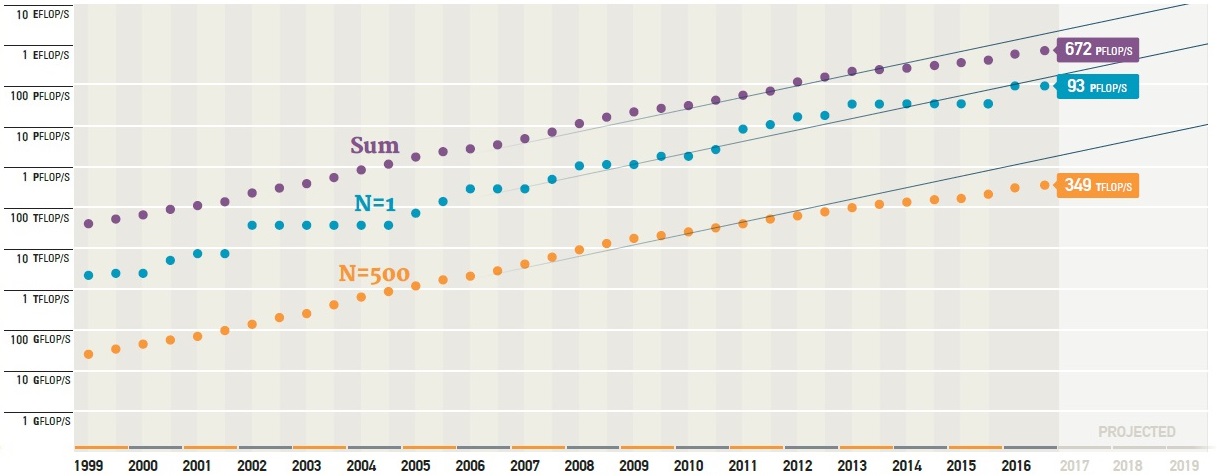
One thing we always note when we discuss Top 500 list results is that this is a good metric of performance and share, but the list is really just a small slice of the overall supercomputers on the planet. The large hyperscale web operators generally do not run the Linpack benchmark to attain a Top 500 ranking and on the other end, some countries, to up their performance share, have many of the smaller web companies run the benchmark to up the overall share too. In short, the Top 500 list is a useful bellwether but is not always a full, true representation of what is happening. We have little sense about what the classified machines look like, and of course, many of the industrial users of HPC do not run the benchmarks since their systems are part of their competitive advantage.
While the top few supercomputers tend to get the share of international attention, for the HPC community as a whole, changes coming starting as early as June 2017 will start to reveal the new shape of the curves above. We expect that the flattened lines on all three fronts will get an uptick, particularly at the bottom.

Top500 Supers: Nvidia Utterly Dominates Those Shiny New Machines
If you stare at something for a little bit of time and let your mind wander, you can think of a new way to analyze something that you have looked at a bunch of times. We squinted at the June 2024 Top500 supercomputer rankings, which are out a month earlier …

The Supercomputing Efficiency Curve Bends In The Right Direction
Things get a little wonky at exascale and hyperscale. Things that don’t matter quite as much at enterprise scale, such as the cost or the performance per watt or the performance per dollar per watt for a system or a cluster, end up dominating the buying decisions. The main reason …
A Status Check on Global Exascale Ambitions
As we head toward the annual Supercomputing Conference season we wanted to take a moment for a level-set on exascale. There has been much talk about reaching this pinnacle over the last several years and while plenty of centers say they have reached exascale, that is only for single-precision peak …
Before Knights Hill (which is pretty optimistic to expect in 2017), there will first be Knights Mill, although I don’t know if that will also go into supercomputers since it mainly adds half precision.