

A new crop of applications is driving the market along some unexpected routes, in some cases bypassing the processor as the landmark for performance and efficiency. While there is no end in sight for the CPUs dominant role, at least not until Moore’s Law has been buried along the roadside, there is another path—this time, down memory lane.
Just as machine learning oriented applications represent the next development platform, memory appears to be the next platform for compute, especially with all the options coming down the pike. Phase change memory, memristors, resistive RAM, 3D XPoint, and others are on the research horizon. And while this won’t extend to all application areas, given the thrust of machine learning and memory bandwidth and capacity-strained applications, the more that can be packed into memory and computed on directly, the more efficient and high performance applications will be.
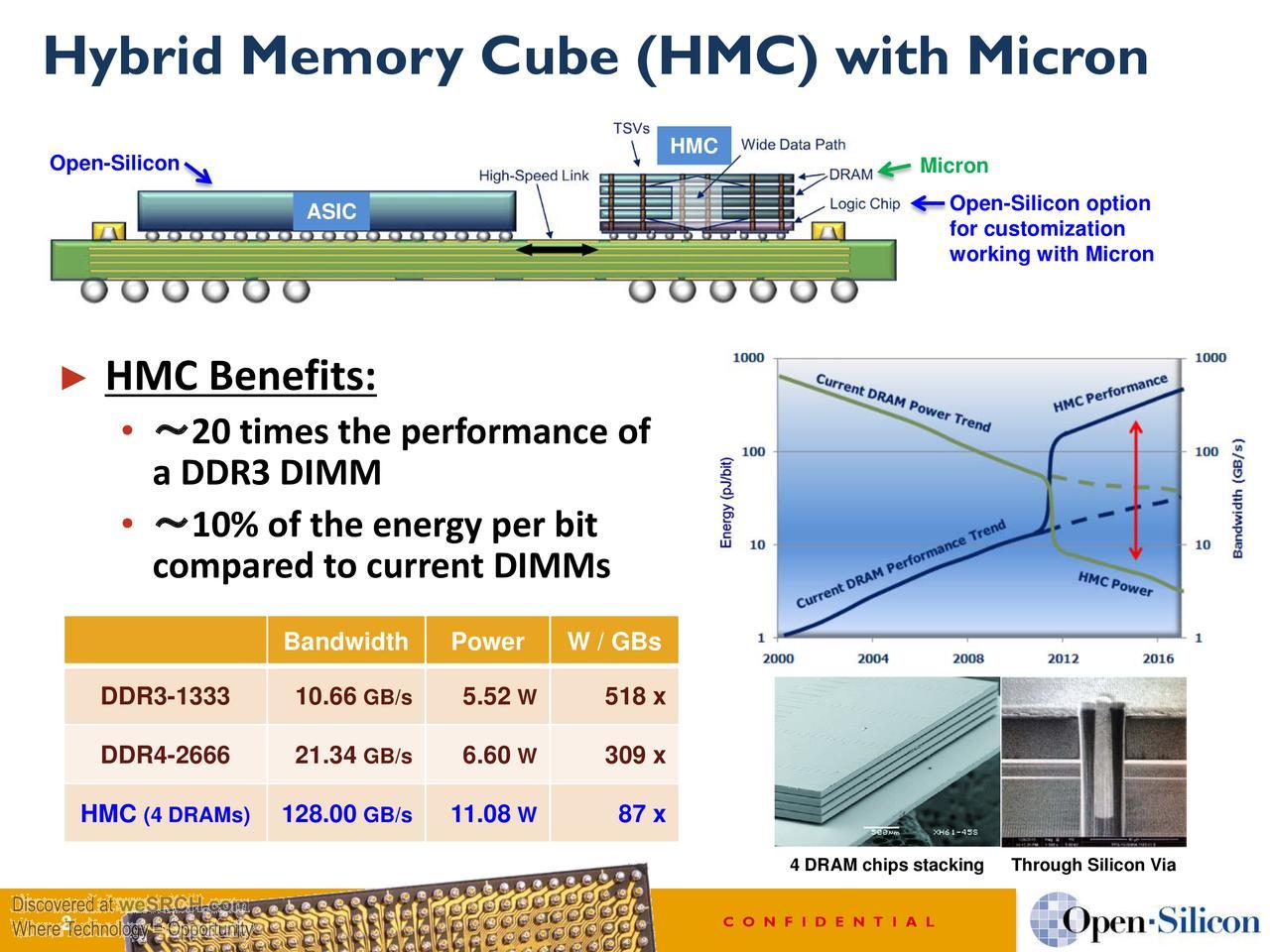
Capacity, capability, and data movement-wise, stacked memory is the one expected to live up to the hype in the nearest term. But what is not often cited when it comes to 3D memory is how much of the compute burden the logic layer inside stacked memory device can shoulder. One of the reasons we have been paying attention to this is because of a new set of custom processors for machine learning and other specialized workloads which take advantage of the compute inside the logic layer, relegating the host CPU to mere housekeeping tasks. Of course, another use case will be in top supercomputers, albeit next to CPUs and accelerators that cannot play second fiddle to a simple logic layer.
Supercomputing use cases aside, a look at the logic layer inside a hybrid memory cube (HMC) device can be thought of a fully capable SoC—one with expanding capabilities on the horizon, including the addition of FPGAs for reconfigurable logic. The goal, according to Micron’s Steve Pawlowski, is to make memory the core compute brick or building block beginning with the new set of applications that don’t require wide vectors, double-precision capabilities, and the inefficiencies of a beefy general purpose server processor.
In the three decades he spent at Intel, most recently as a senior fellow, Pawlowski and teams could comfortably push compute capabilities from the processor level with only a second glance at the role of memory. However, at the edge of Moore’s Law, with memory bandwidth as the next great bottleneck, he started to see that the next wave of capabilities might be better aligned with memory—at least conceptually. This realization landed him at Micron, where, still in partnership with Intel, Pawlowski is focusing on the increased role of memory in both data storage and compute.
The misconception about HMC and high bandwidth memory (HBM) is that these logic layers contain highly specialized functions. This is not the case at all; there are memory controllers with some limited arithmetic functions, but for areas like machine learning, that is all that’s needed. Outside of the supercomputing use cases where 64-bit procession is needed, the real emphasis is on memory capacity and memory bandwidth. “The whole idea is that to create a system where we can optimize to get as much efficiency as possible by optimizing the bandwidth per core and maintaining that as the system scales. You can do all of that in these small modules of logic as compute bricks.”
To re-emphasize, even though there is great potential in computing in memory, the devices now aren’t complex. That logic layer is just a simple piece inside of something equal simple—at least in theory. There is a memory controller with the HMC broken into 32 elements that span through the memory. A request comes in, it looks to see where it is routed within those 32 elements and individual controllers for independent requests bring the data together and present it back out. In essence, it’s like taking the memory controller out of the CPU and putting it into the logic layer. There are things that can be done from that point, of course, including adding error correction and such, but with added features come added costs, both monetary and software-wise.
“What’s in the layer now is the ability to talk to the memory stack and perform a limited set of operations. There are certain things you might want to do that would otherwise require going back to the processor and that is a waste of energy. This is what is possible now, but what we are looking at in the follow-on generations is where do some processing in the logic layer and some in the memory. This is fairly long term, but we’ve already found we can improve things like sort by orders of magnitude by creating a sort table inside the memory device itself, for example,” Pawlowski tells The Next Platform.
While it might be optimistic to say that memory is the next platform today, what Pawlowski points to on the horizon is compelling, especially for memory-limited application areas. Of course, this does come with a hefty price—and not just in terms of the hardware development. Significant application retooling or rewriting will be necessary and that is something that Micron is hesitant to push to the market too quickly, especially given the existing high costs of current and future HMC devices. “There are things today that we are trying to optimize not only for the memory operation but for the compute in a way that won’t have an impact on the software model,” he says. “If you go in today with this new thing and see that everything needs to be rewritten, even if there are advantages, it is not going to take off. We are trying to stage it in terms of adding new features over time so the impact to ecosystems will be more gradual. What we’ll find at 14nm or 7nm is a tremendous amount of logic area to put things like reconfigurable fabrics and cores and have them take advantage of being fairly close to memory.
The other optimistic angle here is that eventually HMC and HBM devices will be able to do more when strung together. For now, we can have very high bandwidth in a single device matched with the all-important logic layer. However, if all of that speed and efficiency can’t scale, it will be limited in scope. There are plans in the works at Micron and AMD to address this, including work on a DoD Fast Forward program, but again, these are forward-looking technologies.

For now, however, if machine learning applications are the bellweather for what future systems need to look like, there is great promise on the memory horizon. The more compute that is added pushes performance higher—and the more work done to make all of this scale into massive systems only ups the game for this new breed of applications. As Pawlowski says, “In my career at Intel, I spent much of my time trying to pack more math performance into wider vectors and push precision, but when you look at what is next for applications and machine learning, the biggest bottleneck is just keeping those processors fed. Having the data be resident and bringing the compute close for higher efficiency is important there and as that logic layer builds, we will see more applications that can benefit.”

Skyrocketing HBM Will Push Micron Through $45 Billion And Beyond
Micron Technology has not just filled in a capacity shortfall for more high bandwidth stacked DRAM to feed GPU and XPU accelerators for AI and HPC. It has created DRAM that stacks higher and runs faster than the competition from SK Hynix and Samsung. And therefore Micron has also found …
Meta Platforms Hacks CXL Memory Tier Into Linux
We have been excited about the possibilities of adding tiers of memory to systems, particularly persistent memories that are less expensive than DRAM but offer similar-enough performance and functionality to be useful. In particular, we have been strong advocates for disaggregating DRAM memory from the CPUs that make use of …
Mashing Up CXL And Gen-Z For Shared Disaggregated Memory
If you are impatient for not just memory pooling powered by the CXL protocol, but the much more difficult task of memory sharing by servers attached to giant blocks of external memory, you are not alone. Memory fabric creator IntelliProp is right there with you. And that is why IntelliProp, …
Hybrid Memory Cube (HMC) technology has one major drawback, which is rarely mentioned in the literature. Its performance varies a lot depending on the address scheme. For example, application writes or reads to a single physical address in HMC could be two orders of magnitude slower than random accesses to the entire range of addresses. HMC has several “knobs” to configure mapping between logical address on the chip pins and physical address inside the device. Each application using HMC will need to use those knobs, otherwise read and write performance will be unexpectedly low or vary a lot.
Now if they could get that Logic layer to perform basic memory operations, eg. XOR, add, subtract, multiply, shift, rotate etc. directly on the memory without having to involve the compute node, we’d really have something.
Simple ALU operations performed in the memory without eating memory bandwidth? Oh yes please!